
转载机器之心报道****编辑:张倩、蛋酱中科院计算所、中国科学院大学、中关村实验室合作的一篇论文拿到了 EMNLP 2024 最佳论文奖。刚刚,EMNLP 2024 论文奖项结果出炉了! EMNLP 2024 会议近日在美国迈阿密盛大开幕,现场热闹非凡。

本届会议收到了前所未有的 6395 篇论文,其中有效投稿 6105 篇,比上一年足足增加了 1196 篇。经过了严格的审稿过程,主办方保持了与往年差不多的论文接收率,最终有 1271 篇主会议论文被接收。

让国内研究者更加激动的是,EMNLP 2025 将在中国苏州举办:
伴随着本届会议的进行,最佳论文、杰出论文等奖项陆续出炉。以下是获奖论文信息: 最佳论文
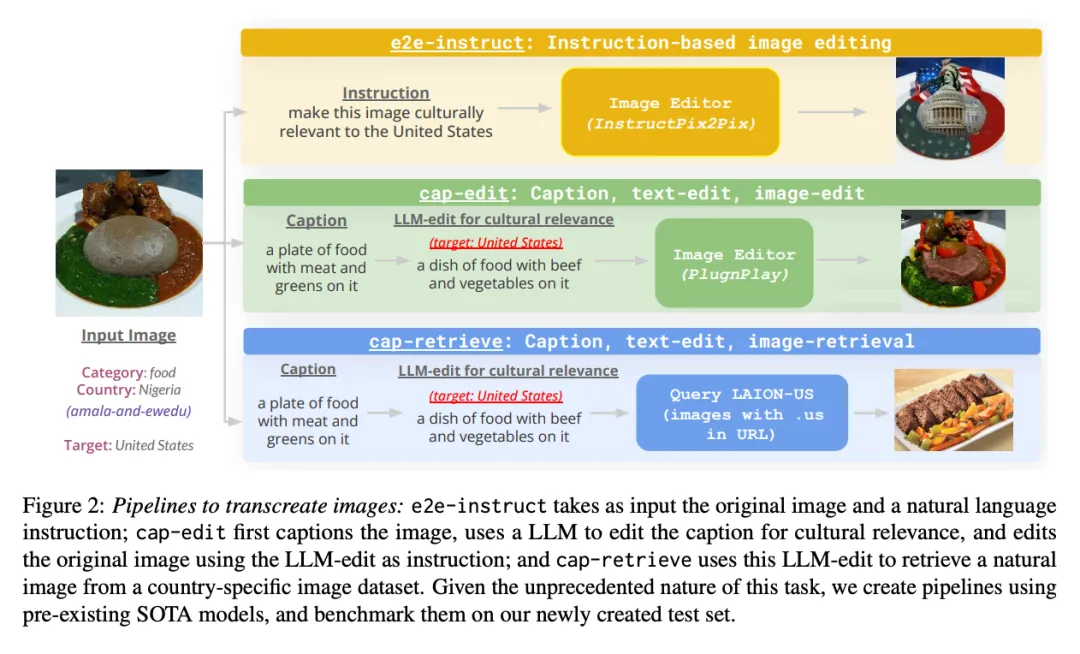
论文 1:《An image speaks a thousand words, but can everyone listen? On image transcreation for cultural relevance》

- 作者:Simran Khanuja, Sathyanarayanan Ramamoorthy,Yueqi Song,Graham Neubig
- 机构:CMU
- 链接:https://aclanthology.org/2024.emnlp-main.573.pdf
- 获奖理由:介绍了「transcreation」的概念,即生成文化上合理的图像,并提供了一个基准数据集来评估 LLM 在这项任务中的能力,开辟了一个具有重大现实意义的新研究领域。
摘要:随着多媒体内容的兴起,人类翻译人员越来越注重文化适应,不仅是文字,还包括图像等其他方式。虽然一些应用可以从中受益,但机器翻译系统仍然局限于处理语音和文本中的语言。这项工作引入了翻译图像的新任务,使其具有文化相关性。首先,本文建立了三个由最先进的生成模型组成的 pipeline 来完成这项任务。接下来,研究者建立了一个由两部分组成的评估数据集,(i) 概念:由 600 幅跨文化连贯的图像组成,每幅图像只关注一个概念;(ii) 应用:由 100 幅从真实世界应用中收集的图像组成。本文对翻译图像进行了多方面的人工评估,以评估文化相关性和意义保存情况。结果发现到目前为止,图像编辑模型未能完成这项任务,但可以通过在循环中利用 LLM 和检索器来加以改进。在较简单的概念数据集中,最佳 pipeline 只能为某些国家翻译 5% 的图像,而在应用数据集中,对某些国家则无法成功翻译,凸显了这项任务的挑战性。
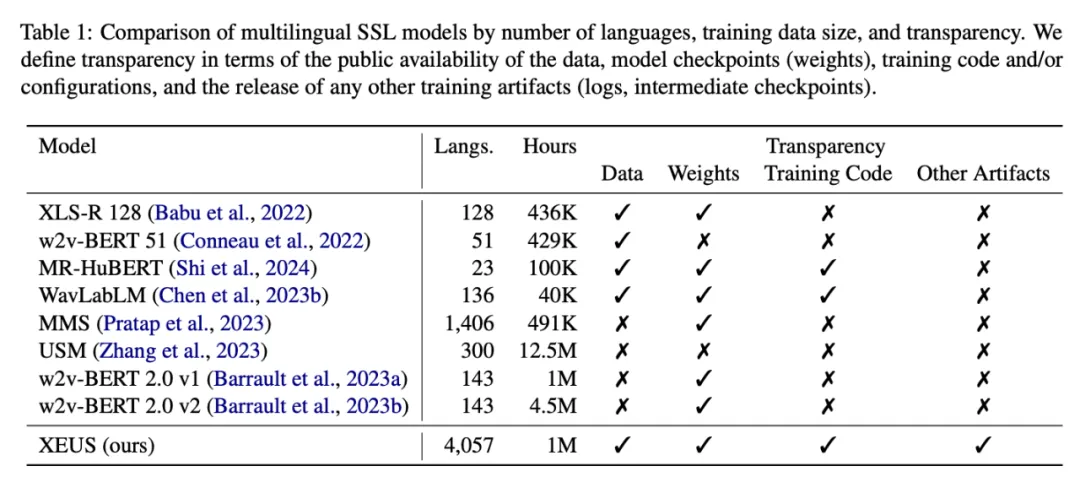
论文 2:《Towards Robust Speech Representation Learning for Thousands of Languages》

- 作者:William Chen, Wangyou Zhang, Yifan Peng, Xinjian Li, Jinchuan Tian,Jiatong Shi, Xuankai Chang, Soumi Maiti, Karen Livescu, Shinii Watanabe
- 机构:CMU、上海交大、丰田工业大学(芝加哥)
- 链接:https://aclanthology.org/2024.emnlp-main.570.pdf
- 获奖理由:发布了一个涵盖 4000 多种语言、超过 100 万小时语音的数据集,以及一个在数据基础上训练的多语言模型。
摘要:自监督学习(SSL)通过减少对标注数据的需求,帮助语音技术扩展到更多的语言。然而,目前的模型还远远不能支持全球 7000 多种语言。本文提出了通用语音跨语言编码器 XEUS,该编码器在 4057 种语言的 100 多万小时数据基础上进行训练,将 SSL 模型的语言覆盖范围扩大了 4 倍。研究者将现有公开语料库中的 100 万小时语音与新创建的来自 4057 种语言的 7400 多小时语料库结合起来公开发布。为了处理多语言语音数据的不同条件,他们还采用了一种新颖的去混响目标来增强典型的 SSL 掩蔽预测方法,从而提高了鲁棒性。随后他们在多个基准上对 XEUS 进行了评估,结果表明它在各种任务中的表现始终优于 SOTA SSL 模型,或取得了与之相当的结果。XEUS 在 ML-SUPERB 基准上创造了新的 SOTA:尽管参数或预训练数据较少,但它的性能分别比 MMS 1B 和 w2v-BERT 2.0 v2 高出 0.8% 和 4.4%。
论文 3:《Backward Lens: Projecting Language Model Gradients into the Vocabulary Space》

- 作者:Shahar Katz, Yonatan Belinkov, Mor Geva, Lior Wolf
- 机构:以色列理工学院、特拉维夫大学
- 链接:https://aclanthology.org/2024.emnlp-main.142.pdf
- 获奖理由:通过将梯度投射到词汇空间来实现可解释性,为模型编辑引入了一种优雅而直观的方法。
摘要:了解基于 Transformer 的语言模型(LM)如何学习和调用信息是深度学习领域的一个关键目标。最近的可解释性方法将前向传递获得的权重和隐藏状态投射到模型的词汇表中,有助于揭示信息如何在 LM 中流动。本文将这一方法扩展到 LM 的后向传递和梯度。研究者首先证明,梯度矩阵可以被视为前向传递和后向传递输入的低秩线性组合。然后,研究者开发了将这些梯度投射到词汇项目中的方法,并探索了新信息如何存储在 LM 神经元中的机制。 论文 4:《Pretraining Data Detection for Large Language Models: A Divergence-based Calibration Method》

- 作者:Weichao Zhang, Ruging Zhang, Jiafeng Guo, Maarten de Rijke, Yixing Fan,Xueqi Cheng
- 机构:中科院计算所、中国科学院大学、中关村实验室、阿姆斯特丹大学
- 链接:https://aclanthology.org/2024.emnlp-main.300.pdf
- 获奖理由:提出了一种用于预训练数据黑盒检测的新数据集和方法
摘要:随着大型语言模型(LLM)训练语料库规模的扩大,模型开发者越来越不愿意公开其数据的详细信息。这种缺乏透明度的情况给科学评估和道德部署带来了挑战。最近,人们开始探索预训练数据检测方法,这类方法会通过黑盒访问推断给定文本是否是 LLM 训练数据的一部分。Min-K% Prob 方法已经取得了最先进的成果,该方法假定非训练样本往往包含一些 token 概率较低的离群词。然而,这种方法的有效性可能有限,因为它往往会误分那些包含许多由 LLM 预测为高概率的常用词的非训练文本。本文受散度随机性的启发,引入了一种基于散度的校准方法,来校准用于预训练数据检测的 token 概率。研究者计算了 token 概率分布和 token 频率分布之间的交叉熵(即散度),从而得出检测得分。此外还开发了一个中文基准 —PatentMIA,以评估 LLMs 检测方法在中文文本上的性能。在英文基准和 PatentMIA 上的实验结果表明,本文提出的方法明显优于现有方法。

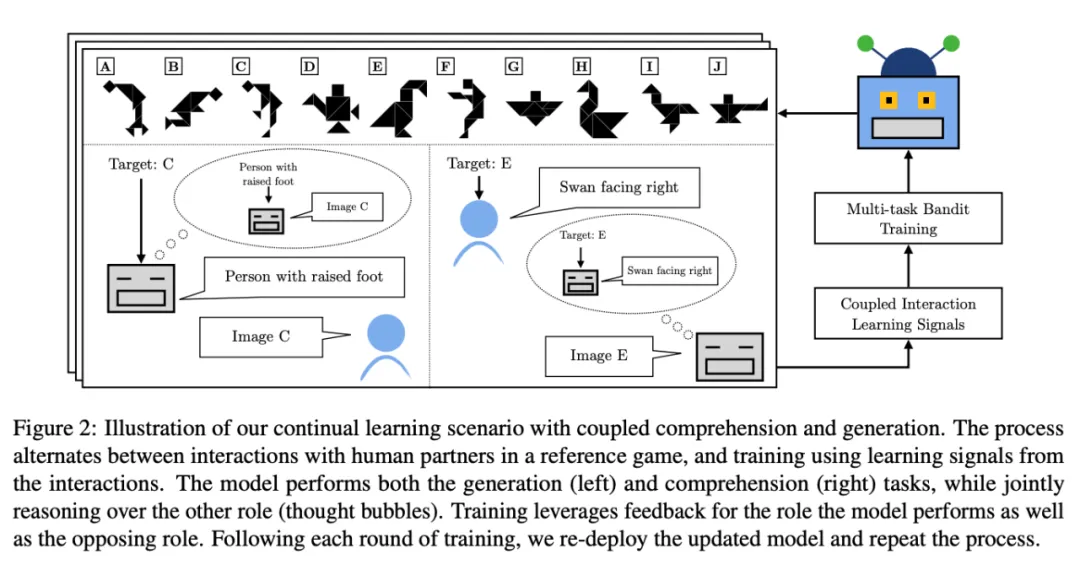
论文 5:《CoGen: Learning from Feedback with Coupled Comprehension and Generation》

- 作者:Mustafa Omer Gul, Yoav Artzi
- 机构:康奈尔大学
- 链接:https://aclanthology.org/2024.emnlp-main.721.pdf
- 获奖理由:探索语言理解与语言生成的结合,以改善双人参考游戏中的人际互动。
摘要:同时具备语言理解和生成能力的系统可以从两者之间的紧密联系中获益。本文将理解和生成功能结合在一起,重点关注从与用户的互动中不断学习,提出了将这两种学习和推理能力紧密结合的技术。研究者将研究置于双人参考游戏中,并在与人类用户的数千次互动中部署各种模型,同时从互动反馈信号中学习。结果发现,随着时间的推移,性能有了显著提高,与无耦合系统相比,理解力生成耦合的绝对性能提高了 26%,准确率提高了 17%。本文分析还表明,耦合对系统语言的质量产生了重大影响,使其明显更像人类语言。
杰出论文

-
论文 1:Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models
-
作者:Sander Land、Max Bartolo
-
机构:Cohere
-
获奖理由:深入探讨了多个开源 LLM 中未充分训练的 token 所引发的问题。
-
论文 2:Learning to Retrieve lteratively for in-Context Learning
-
作者:Yunmo Chen, Tongfei Chen, Harsh Jhamtani, Patrick Xia, Richard Shin, Jason Eisner, Benjamin Van Durme
-
机构:微软
-
获奖理由:提出了一种创造性的方法,将 in-context leaming 示例的选择建模为马尔可夫决策过程。
-
论文 3:Measuring Psychological Depth in Language Models
-
作者:Fabrice Y Harel-Canada, Hanyu Zhou, Sreya Muppalla, Zeynep Senahan Yildiz, Miryung Kim, Amit Sahai, Nanyun Peng
-
机构:加州大学洛杉矶分校
-
获奖理由:提供了一套以叙事理论为基础的有用指标,用于评估 LLM 的叙事写作。
-
论文 4:Do LLMs Plan Like Human Writers? Comparing Journalist Coverage of Press Releases with LLMs
-
作者:Alexander Spangher, Nanyun Peng, Sebastian Gehrmann, Mark Dredze
-
机构:南加利福尼亚大学、加州大学洛杉矶分校、彭博社
-
获奖理由:提出了一种通过将 LLM 与新闻记者进行比较来评估 LLM 的方法和数据集
-
论文 5:Words Worth a Thousand Pictures: Measuring and Understanding Perceptual Variability inText-to-mage Generation
-
作者:Raphael Tang, Crvstina Zhang, Lixinyu Xu, Yao Lu, Wenvan Li, Pontus Stenetor, Jimmy Lin, Ferhan Ture
-
机构:Comcast AI Technologies、滑铁卢大学、伦敦大学学院、哥本哈根大学
-
获奖理由:为文本到图像的生成提出了一种经人工校准的可变性测量方法,并对实际影响进行了全面的学科间分析和讨论。
-
论文 6:Finding Blind Spots in Evaluator LLMs with Interpretable Checklists
-
作者:Sumanth Doddapaneni, Mohammed Safi Ur Rahman Khan, Sshubam Verma, Mitesh M Khapra
-
机构:Nilekani Centre at AI4Bharat、印度理工学院
-
获奖理由:关于使用 LLM 作为评估者的研究,信息丰富,发人深省。
-
论文 7:GoldCoin: Grounding Large Language Models in Privacy Laws via Contextual Integrity Theory
-
作者:Wei Fan, Haoran Li, Zheye Deng, Weiqi Wang, Yanggiu Song
-
机构:香港科技大学计算机科学与工程系
-
获奖理由:提出了一个框架,该框架利用隐私场景公正理论(Contextual Integrity Theory) 将大型语言模型与隐私法对齐,增强了它们在各种上下文中检测隐私风险的能力。
-
论文 8:Verification and Refinement of Natural Language Explanations through LLM-Symbolic Theorem Proving
-
作者:Xin Quan, Marco Valentino, Louise A. Dennis, Andre Freitas
-
机构:曼彻斯特大学、瑞士 Idiap 研究所
-
获奖理由:提出了一个集成 LLM 和定理证明的神经符号框架,以提高 NLl 任务的自然语言解释的质量和逻辑有效性。
-
论文 9:The Zeno's Paradox of'Low-Resource’ Languages
-
作者:Helina Hailu Niaatu, Atnafu Lambebo Tonia, Benjamin Rosman, Thamar Solorio, Monoit Choudhury
-
机构:MBZUAI 等
-
获奖理由:仔细研究了「低资源语言意味着什么」这个问题。
-
论文 10:When is Multilinguality a Curse? Language Modeling for 250 High- and Low-Resource Languages
-
作者:Tvler A.Chana. Catherine Arnett. Zhuowen Tu, Ben Bergen
-
机构:加州大学圣迭戈分校
-
获奖理由:对影响 LLM 跨语言预训练和性能的因素进行了广泛而严格的实证调查。
-
论文 11:Language Models Learn Rare Phenomena from Less Rare Phenomena: The Case of the Missing AANNS
-
作者:Kanishka Misra, Kyle Mahowald
-
机构:得克萨斯大学奥斯汀分校
-
获奖理由:介绍了一个有意思的实验设置,演示了 LLM 如何泛化以学习罕见现象。
-
论文 12:Fool Me Once? Contrasting Textual and Visual Explanations in a Clinical Decision-Support Setting
-
作者:Maxime Guillaume Kayser, Bayar Menzat, Cornelius Emde, Bogdan Alexandru Bercean, Alex Novak, Abdalá Trinidad Espinosa Morgado, Bartlomiej Papiez, Susanne Gaube, Thomas Lukasiewicz, Oana-Maria Camburu
-
机构:牛津大学、维也纳技术大学等
-
获奖理由:评估了临床人体研究中不同类型解释的有用性。
-
论文 13:Threshold-driven Pruning with Segmented Maximum Term Weights for Approximate Cluster-based Sparse Retrieval
-
作者:Yifan Qiao, Parker Carlson, Shanxiu He ,Yingrui Yang, Tao Yang
-
机构:加州大学圣巴巴拉分校
-
链接:https://sites.cs.ucsb.edu/~tyang/papers/2024EMNLP-CameraReady.pdf
-
获奖理由:提出了一个 probablistically-rank-safe 的动态 pruning 方案,用于快速的基于聚类的稀疏检索,这个方案对于当前检索系统和 RAG 管道来说非常重要。
-
论文 14:Learning Planning-based Reasoning by Trajectories Collection and Process Reward Synthesizing
-
作者:Fangkai Jiao, Chengwei Qin, Zhengyuan Liu, Nancy F. Chen, Shafig Joty
-
机构:新加坡南洋理工大学、新加坡信息通讯研究院、Salesforce 研究院
-
获奖理由:通过对合成数据提供中间基本原理监督,并在 trajectory 上应用 DPO,增强了 LLM 的推理能力。
-
论文 15:Are Large Language Models Capable of Generating Human-Level Narratives?
-
作者:Yufei Tian, Tenghao Huang,Miri Liu, Derek Jiang, Alexander Spangher, Muhao Chen, Jonathan May, Nanyun Peng
-
机构:加州大学洛杉矶分校、南加利福尼亚大学、加州大学戴维斯分校
-
获奖理由:引入了一个框架,在话语(discourse)层面评估 LLM 生成的叙述。
-
论文 16:Formality is Favored: Unraveling the Learning Preferences of Large Language Models on Data with Conflicting Knowledge
-
作者:Jiahuan Li, Yiging Cao, Shuiian Huang, Jiajun Chen
-
机构:南京大学计算机软件新技术国家重点实验室
-
获奖理由:研究了 LLM 在训练数据信息相互冲突的情况下如何学习。
-
论文 17:OATH-Frames: Characterizing Online Attitudes Towards Homelessness with LLM Assistants
-
作者:Jaspreet Ranjit, Brihi Joshi, Rebecca Dorn, Laura Petry, Olga Koumoundouros, Jayne Bottarini, Peichen Liu, Eric Rice, Swabha Swayamdipta
-
机构:南加利福尼亚大学计算机科学系、
-
获奖理由:在领域专家和 LLM 助理的帮助下,对公众对无家可归者的态度进行大规模分析。
-
论文 18:SUPER: Evaluating Agents on Setting Up and Executing Tasks from Research Repositories
-
作者:Ben Bogin, Kejuan Yang, Shashank Gupta, Kyle Richardson, Erin Bransom, Peter Clark, Ashish Sabharwal, Tushar Khot
-
机构:艾伦人工智能研究所、华盛顿大学
-
获奖理由:创新的基准测试,用于评估基于大型语言模型(LLM)的智能体能否复现来自研究库的结果。
-
论文 19:Towards Cross-Cultural Mlachine Translation with Retrieval-Augmented Generation from Multilingual Knowledge Graphs
-
作者:Simone Conia, Daniel Lee, Min Li, Umar Faroog Minhas, Saloni Potdar, Yunyao Li
-
机构:罗马大学、Adobe、苹果
-
获奖理由:解决了翻译与文化相关的命名实体的挑战,挑战了以前关于如何翻译命名实体的观点。
-
论文 20:Which questions should l answer? Salience Prediction of Inquisitive Questions
-
作者:Yating Wu, Ritika Rajesh Mangla, Alex Dimakis, Greg Durrett, Junyi Jessy Li
-
机构:德克萨斯大学奥斯汀分校、 BespokeLabs.ai
-
获奖理由:提出了一种预测语言敏感问题突出程度的方法和数据集,为语言社区内关于人类如何处理信息和信息内容的话语结构的持续辩论提供信息。
