
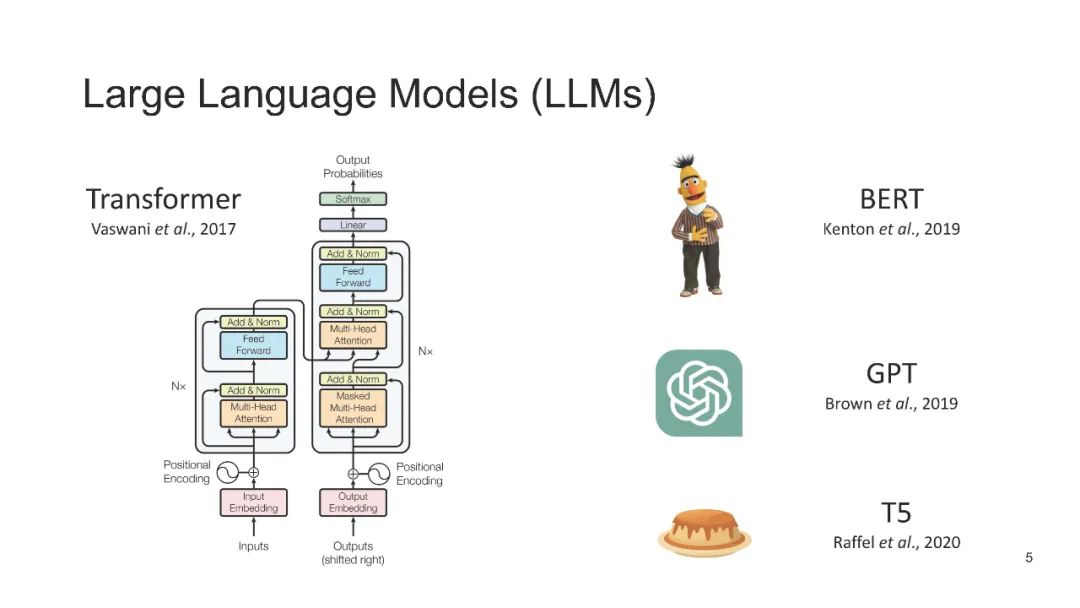
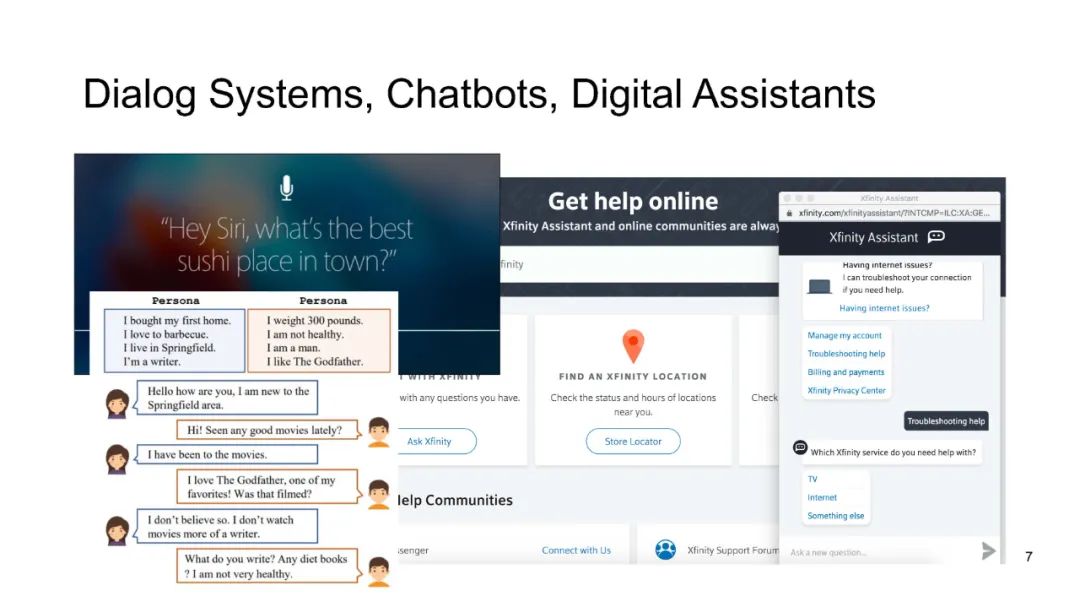
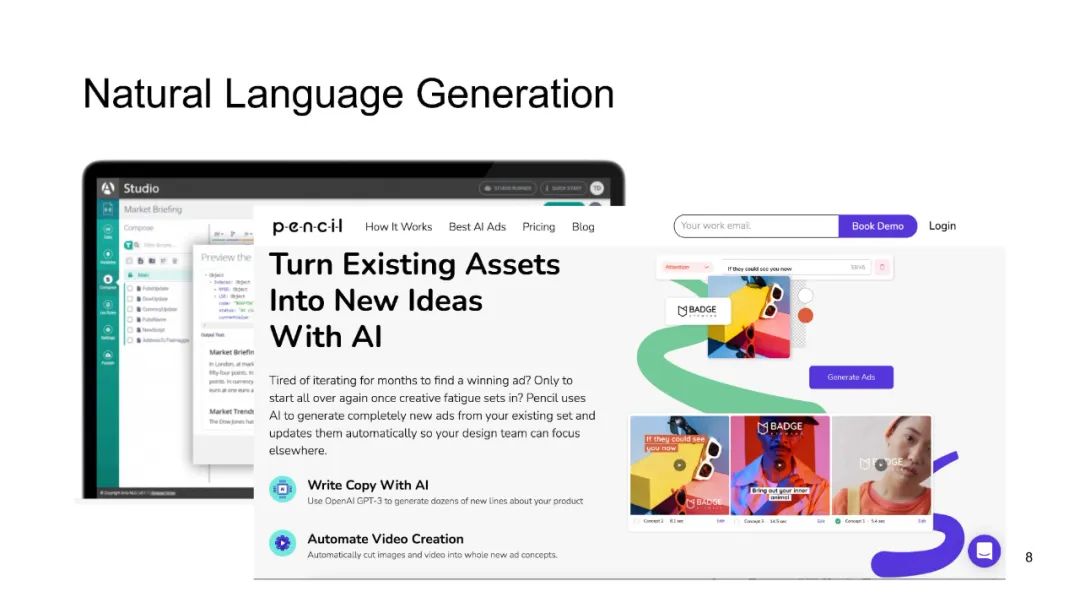
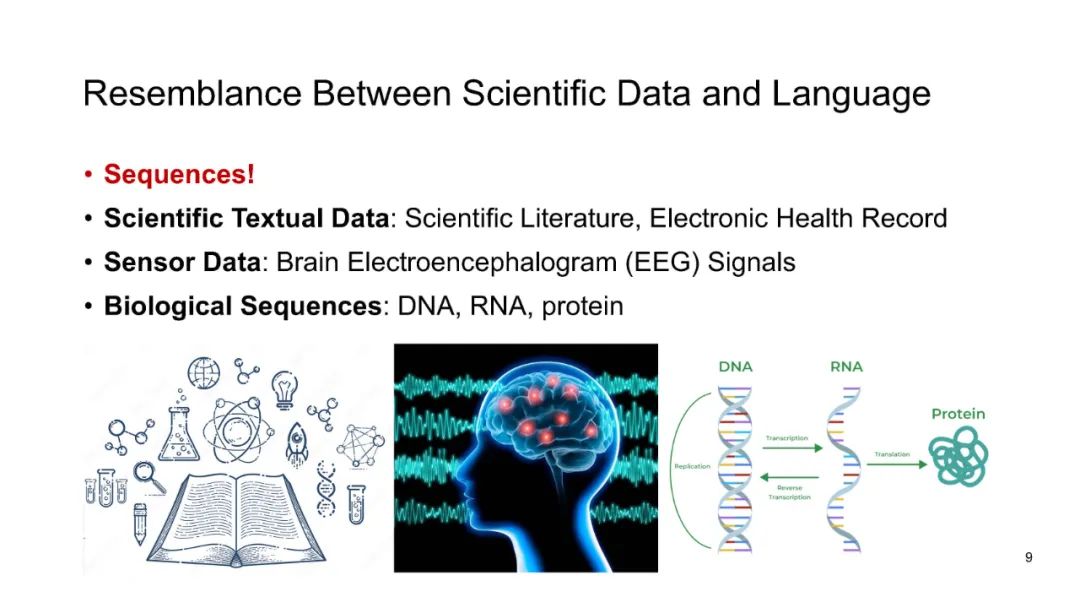
人工智能在科学领域的能力横跨广泛的范围,从原子层面上解决量子系统的偏微分方程,到分子层面上预测化学或蛋白质结构,甚至延伸到社会预测,如传染病爆发的预测。以ChatGPT等模型为代表的大语言模型(LLMs)的最新进展,展示了其在自然语言处理任务中的显著能力,例如语言翻译、构建聊天机器人和回答问题。当我们审视科学数据时,可以发现其与自然语言在序列特征上的相似性——科学文献和健康记录以文本呈现,生物组学数据按序列排列,或者如脑信号等传感器数据。这引发了一个问题:我们是否可以利用这些最新LLMs的潜力来推动科学进步?在本教程中,我们将探索大语言模型在三类科学数据中的应用:1)文本数据,2)生物医学序列,以及3)脑信号。此外,我们将深入探讨LLMs在科学研究中的挑战,包括确保可信性、实现个性化,以及适应多模态数据表示。





成为VIP会员查看完整内容
相关内容
Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日