

1 引言
决策制定是人工智能(AI)系统的核心能力,使智能体能够在复杂环境中导航、实现目标,并适应不断变化的条件。传统的决策框架通常依赖变量之间的关联或统计相关性,但如果忽视底层因果关系,则可能导致次优结果(Pearl et al., 2009)。因果推断领域的兴起为解决这些挑战提供了强大的框架和工具,例如结构因果模型(Structural Causal Models, SCMs)和潜在结果框架(Potential Outcomes Framework)(Rubin, 1978; Pearl, 2000)。 与传统方法不同,因果决策制定(Causal Decision Making, CDM)专注于识别和利用因果关系,使智能体能够推理其行动的后果、预测反事实场景,并以严谨的方式优化决策(Spirtes et al., 2000b)。近年来,基于因果推理的各种决策方法得到了发展,并在推荐系统(Zhou et al., 2017)、临床试验(Durand et al., 2018)、金融(Bai et al., 2024)和网约车平台(Wan et al., 2021b)等领域得到了广泛应用。尽管取得了诸多进展,但一个基本问题仍然存在:
在何时以及为何需要因果建模进行决策制定?
这一问题与反事实思维(Counterfactual Thinking)密切相关,即推理在不同决策或行动下可能发生的情况。在某些领域,未选择的决策结果难以甚至无法直接观察,因此反事实分析至关重要。例如,商业领导者在选择一种营销策略而非另一种时,可能永远无法完全得知未选策略的结果(Rubin, 1974; Pearl et al., 2009)。类似地,在计量经济学、流行病学、心理学和社会科学等领域,由于无法直接观察反事实,因果方法往往是必要的(Morgan & Winship, 2015; Imbens & Rubin, 2015)。 另一方面,在某些情况下,非因果分析可能足够。例如,个人投资者的决策对股票市场动态的影响可以忽略不计,因此可以从已有的股票价格时间序列推断不同投资决策的潜在结果(Angrist & Pischke, 2008)。然而,即使在理论上可以计算反事实结果的情况下,如在已知模型(例如 AlphaGo)环境中,穷举计算所有可能的结果在计算上是不可行的(Silver et al., 2017, 2018)。在这些场景下,因果建模仍然具有优势,它提供了结构化的方法来高效推断结果并制定稳健决策。
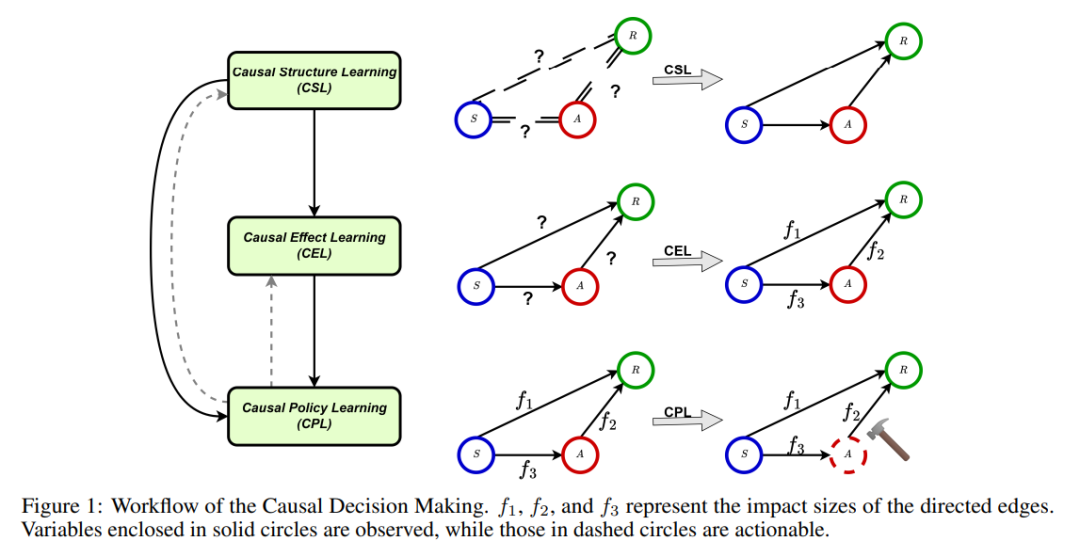
因果决策制定的三大核心任务
现有研究通常假设决策者具有复杂的先验知识或强因果模型,以进行后续决策。要做出有效且可信的决策,深入理解行动、环境和结果之间的因果关系至关重要。因此,本综述综合了因果决策制定(CDM)领域的最新研究进展,并提供了一个涵盖基础概念、最新进展和实际应用的全面概览。 本研究重点讨论因果视角下决策制定的三大核心任务:
- 因果结构学习(Causal Structure Learning, CSL):发现变量之间的因果关系。
- 因果效应学习(Causal Effect Learning, CEL):理解特定行动对结果的影响。
- 因果策略学习(Causal Policy Learning, CPL):基于前两个任务的知识优化决策策略。
设S 表示环境状态,包含决策者所接触的所有相关特征信息,A 代表采取的行动,π 为决定采取何种行动的策略,R 为采取行动 A 后观察到的回报。如图 1 所示,CDM 通常从 CSL 开始,以发现变量之间的未知因果关系。一旦因果结构被建立,CEL 可用于评估特定行动对结果回报的影响。为了进一步优化复杂的行动策略,CPL 可用于评估给定策略或识别最优策略。在实践中,也可能直接从 CSL 过渡到 CPL,而不经过 CEL。此外,CPL 还可以通过改进实验设计(Zhu & Chen, 2019; Simchi-Levi & Wang, 2023)或自适应调整因果结构(Sauter et al., 2024)来提升 CEL 和 CSL 的效果。
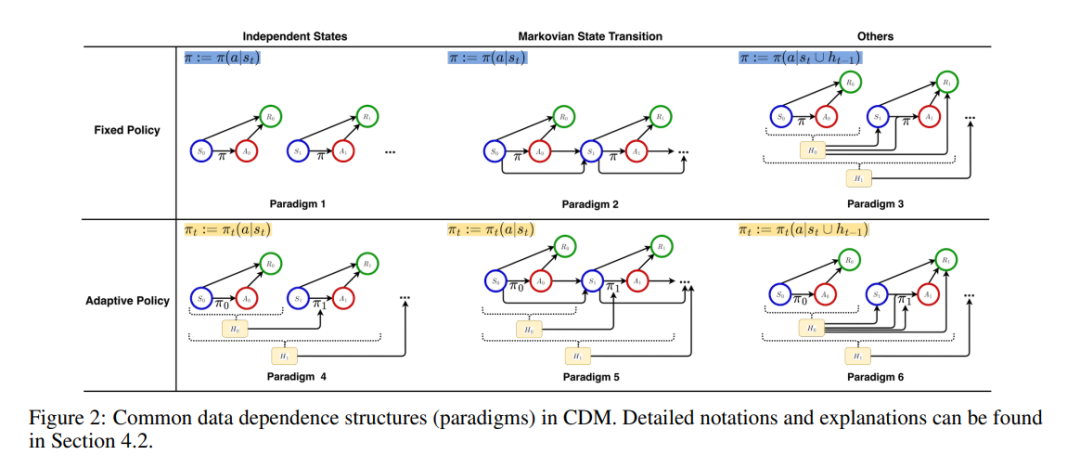
因果决策制定的六种范式
基于上述框架,文献中的决策问题可以进一步归纳为六种范式,如图 2 所示。这些范式总结了实践中常见的数据依赖假设:
- 范式 1-3(离线学习):数据按照未知的固定行为策略收集。
- 范式 4-6(在线学习):策略动态适应新收集的数据,实现持续优化。
这些范式还反映了不同的状态依赖假设:
- 范式 1 & 4:所有观察值相互独立,不存在长期效应。
- 范式 2 & 5(马尔可夫决策过程, MDP):假设给定当前状态-行动对 (St, At),下一个状态 St+1 和回报 Rt 仅取决于当前状态和行动,而与过去所有状态 {Sj}j<t 和行动 {Aj}j<t 无关。
- 范式 3 & 6(更广义的依赖关系):考虑所有历史观测可能影响状态转换和回报,包括部分可观测马尔可夫决策过程(POMDP)(Hausknecht & Stone, 2015; Littman, 2009)、面板数据分析(Hsiao, 2007, 2022)和动态治疗方案(DTR)(Chakraborty & Murphy, 2014; Chakraborty & Moodie, 2013)。
在不同的范式下,CSL 主要在范式 1 下展开,CEL 和离线 CPL 涉及范式 1-3,而在线 CPL 则涵盖范式 4-6。本综述围绕这三个任务和六种范式,提供了一个系统性框架,以帮助理解因果决策制定在不同任务和数据结构下的应用。