所有云架构师都需要知道如何构建数据平台,使企业能够做出基于数据的决策,并以快速高效的方式提供企业级智能。这本手册向您展示如何使用AWS、Azure、谷歌云和多云工具如Snowflake和Databricks设计、构建和现代化云原生数据和机器学习平台。
作者 Marco Tranquillin、Valliappa Lakshmanan 和 Firat Tekiner 讨论了整个数据生命周期,从在云环境中摄取到激活,使用真实世界的企业架构。您将学习如何转换、保护和现代化熟悉的解决方案,如数据仓库和数据湖,并能够利用最近的AI/ML模式获得准确和更快的洞察,以驱动竞争优势。
您将学习如何: * 设计一个现代化和安全的云原生或混合数据分析和机器学习平台 * 通过在一个受管理的、可扩展的和有弹性的数据平台中整合企业数据,加速数据驱动的创新 * 民主化对企业数据的访问,并管理业务团队如何提取洞察力和构建AI/ML能力 * 使您的企业能够使用流式管道实时做出决策 * 构建一个MLOps平台,转向预测和规范分析方法
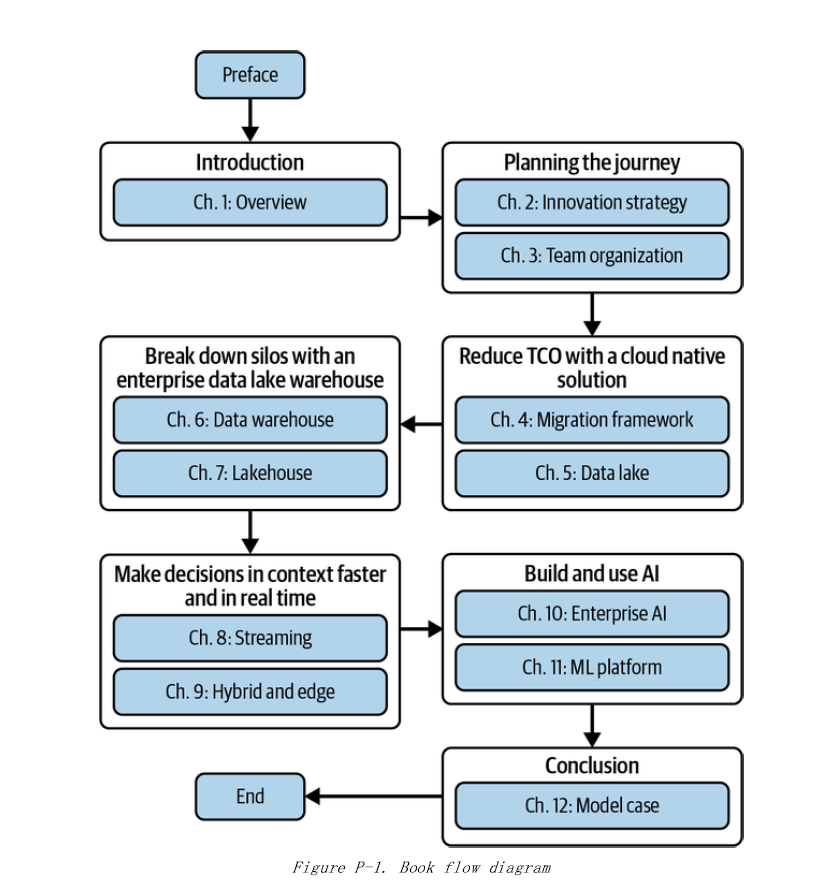
来自前言 这本书适合谁?
这本书是为那些希望通过使用公共云技术创建数据和ML平台来支持其业务的数据驱动决策的架构师而写的。数据工程师、数据分析师、数据科学家和ML工程师会发现这本书对于获得他们可能在其上实现的系统的概念设计视图很有用。
数字原生公司早在几年前就已经这样做了。
早在2016年,Twitter解释说,他们的数据平台团队维护着“支持和管理为各种业务目的生产和消费数据的系统,包括公开报告的指标、推荐、A/B测试、广告定向等”。2016年,这涉及到维护世界上最大的Hadoop集群之一。到2019年,这开始包括支持使用云原生数据仓储解决方案。
以Etsy为例,他们说他们的ML平台“通过开发和维护技术基础设施来支持ML实验,Etsy的ML实践者依赖这些基础设施来原型、训练和部署ML模型。” Twitter和Etsy都已经建立了现代数据和ML平台。这两家公司的平台是不同的,以支持平台需要支持的不同类型的数据、人员和业务用例,但底层方法相当相似。 在这本书中,我们将向您展示如何构建一个现代的数据和ML平台,使您的业务中的工程师能够:
从各种来源收集数据,如操作数据库、客户点击流、物联网(IoT)设备、软件即服务(SaaS)应用程序等。 * 打破组织的不同部分之间的壁垒 * 在摄取或加载数据时处理数据,同时保证数据质量和治理的正确流程 * 定期或即席分析数据 * 使用预构建的AI模型丰富数据 * 构建ML模型进行预测分析 * 定期或响应触发事件或阈值对数据采取行动 * 传播洞察和嵌入分析
这本书为那些在企业中使用数据和机器学习模型的人员提供了关于架构上的良好入门,因为您需要在数据或机器学习平台团队构建的平台上完成您的工作。因此,如果您是数据工程师、数据分析师、数据科学家或机器学习工程师,您会发现这本书对于获得高级系统设计视图非常有帮助。 尽管我们的主要经验是与google Cloud相关,但我们努力保持对底层架构的服务的云端中立的视野,通过引入但不限于所有三个主要的云供应商(即,Amazon Web Services [AWS]、Microsoft Azure和google Cloud)的示例。