

本文提出了一项开创性的、全面的综述,首次聚焦于基于视觉-语言模型(VLMs)的3D物体检测,这是多模态AI领域快速发展的前沿技术。我们结合学术数据库与AI驱动的搜索引擎,采用混合搜索策略,筛选并分析了超过100篇最先进的论文。我们的研究首先将3D物体检测置于传统流程中,考察了如PointNet++、PV-RCNN和VoteNet等利用点云和体素网格进行几何推理的方法。随后,我们追溯到向VLM驱动系统的转变,其中如CLIP、PaLM-E和RoboFlamingo-Plus等模型通过语言引导推理、零-shot泛化和基于指令的互动,增强了空间理解能力。我们探讨了这一转变所依赖的架构基础,包括预训练技术、空间对齐模块和跨模态融合策略。通过可视化和基准比较,展示了VLMs在语义抽象和开放词汇检测中的独特能力,尽管在速度和注释成本方面存在权衡。我们的比较综合强调了关键挑战,如空间错位、遮挡敏感性和实时性有限,同时提出了新兴解决方案,如3D场景图、合成标注和多模态强化学习。本文综述不仅巩固了基于VLM的3D检测的技术格局,还提供了前瞻性的路线图,识别了有前景的创新和部署机会。它为希望在机器人技术、增强现实和具身AI中利用语言引导的3D感知的研究人员提供了基础性参考。与此综述和评估相关的项目已在Github上创建,链接为:https://github.com/r4hul77/Awesome-3DDetection-Based-on-VLMs

1 引言
图1提供了一个视觉示例,展示了物体检测如何从传统的2D方法发展到更先进的3D检测技术。图像显示了一个苹果在3D空间中的检测,使用的边界框不仅捕捉了物体在X轴和Y轴上的位置,还捕捉了它的深度(Z轴)。这突出了3D检测的核心优势:比起限于平面图像坐标的2D方法,3D检测能够更准确地感知和定位物体在空间环境中的位置。如图所示,2D边界框无法完全表示物体的体积、大小或它与附近物体的关系,这些都是机器人操作或自主导航等任务中重要的因素。 物体检测本身是计算机视觉中的基础任务,广泛应用于自动驾驶、机器人、监控和增强现实等领域[Ghasemi等,2022]。其主要目标是通过在图像或传感器数据中绘制带有类别标签的框,识别和定位有意义的物体[Zou等,2023]。传统的物体检测系统主要依赖于2D图像,早期的模型使用手工特征[Agarwal和Roth,2002;Papageorgiou等,1998]。深度学习的现代突破导致了实时检测器的出现,如YOLO[Redmon等,2016]、SSD[Liu等,2016]和Faster R-CNN[Ren等,2016],即使在复杂的条件下也能实现高精度[Sapkota和Karkee,2024;Sapkota等,2024c]。然而,没有深度信息,这些2D系统在需要空间推理或在3D世界中进行物体交互的任务中表现欠佳。 为克服这些空间限制,3D物体检测方法逐渐得到了越来越多的关注,这些方法操作的是体积数据,如LiDAR点云、深度图和RGB-D输入[Wang等,2021]。这些模型提供了更完整的物体几何和空间关系表示,通常利用体素化、基于点的表示或3D卷积[Arnold等,2019;Caglayan和Can,2018]。然而,尽管这些传统的3D深度学习模型在空间推理方面提供了显著的改进,但它们也有自己的约束[Qian等,2022;Wang等,2022c]。它们需要大量的注释[孟等,2021;Xiang等,2014],需要大规模的3D数据集和详细的人工标签,而这些标签的创建既昂贵又费时[Brazil等,2023;Sølund等,2016;Tremblay等,2018]。此外,它们常常在跨领域泛化方面表现不佳[Eskandar,2024],缺乏语义灵活性[Zhang等,2021],并且在适应新物体类别或部署环境时,训练要求也非常严格[Mao等,2023;Peng等,2015]。进一步 complicating 它们的部署,传统模型往往依赖于传感器,依赖于精心校准的多模态系统,如LiDAR-摄像头融合系统[Alaba和Ball,2022],这使得它们在无控制或资源受限的环境中表现得较脆弱。 此外,这些系统在可解释性和灵活性方面也存在局限[Wang等,2022a],缺乏融入高层次、任务导向指令的能力[Chen等,2023a]。例如,它们无法理解像“只检测离手边的熟透苹果”这样的命令,也无法实时适应不断变化的任务目标或用户意图。视觉-语言模型(VLMs)的出现提供了一个具有变革性的解决方案,通过结合视觉感知和自然语言理解,VLMs为3D物体检测引入了全新的语义推理层次。如图1所示,我们的示例展示了一个现实世界中的苹果在3D空间中被检测出来,不仅具备空间精度,还通过语义理解得到了上下文的注解。该图还突出了双重优势:直接3D检测相较于2D方法的五大优点,以及VLM-based 3D检测系统相比传统CNN-based 3D检测器提供的五大独特优势。直接的3D检测方法通过提供更高的空间精度、深度感知定位、体积上下文、遮挡处理和度量尺度推理,超越了它们的2D对应物。这些能力对于现实世界的机器人应用至关重要,因为它们需要对物体的位置和交互有全面的理解。与此同时,基于VLM的方法进一步提升了这些能力,通过启用基于提示的控制[Tang等,2025b]、零-shot泛化[Zhang等,2024c]、语义意识[Zhang等,2024f]、多模态集成[Zang等,2025]和可解释性[Raza等,2025;Yellinek等,2025]。与基于CNN的系统不同,VLMs可以处理自然语言查询并将高层次推理整合到检测过程中[Chen等,2024d;Fu等,2025],允许执行像“找到适合采摘的最近苹果”这样的任务,而无需针对每个新任务进行特定的训练。
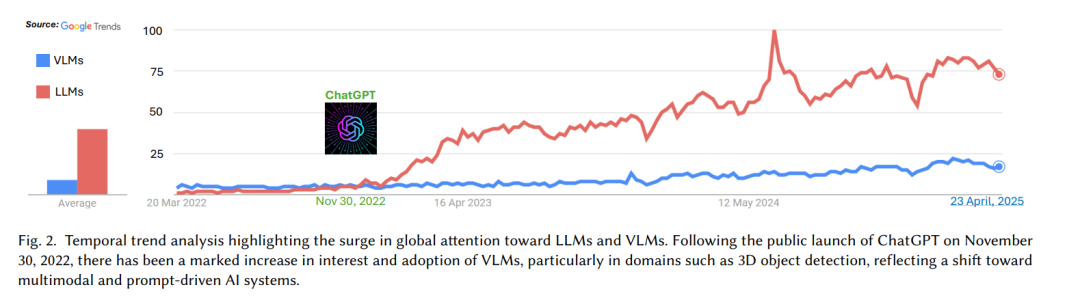
尽管基于点云处理的传统3D物体检测方法(通常基于卷积神经网络(CNN))已经取得了一定的进展,但这些方法仍然面临语义理解、数据效率和适应性方面的关键限制。如前所述,基于CNN的3D检测器通常需要昂贵的传感器校准、大规模注释数据集和严格的重新训练程序来适应新环境。更重要的是,它们缺乏复杂推理任务所需的语义可解释性,例如识别特定物体属性或响应用户定义的自然语言提示。 近年来,VLMs已成为解决传统2D和仅基于几何的3D物体检测方法固有局限性的变革性解决方案。VLMs将计算机视觉的视觉模式识别优势与大规模语言模型(LLMs)的语义推理能力相结合,能够对场景进行更丰富的多模态理解[Ma等,2024]。如图2所示,2022年11月30日ChatGPT的公开发布,引发了对LLMs前所未有的兴趣,迅速将它们确立为自然语言理解的基础工具。虽然VLMs的崛起较为渐进,但LLMs的影响促使了对多模态系统的关注增加。这种增长的兴趣在需要高层次推理和上下文理解的领域中尤为明显,如机器人技术中的3D物体检测、增强现实和自动导航。与传统的3D检测器不同,VLMs使得灵活查询、少量示例学习或零-shot学习以及语义任务泛化成为可能——这一切都无需为每个新任务重新训练。
这一范式转变在几项近期工作中得到了体现。例如,Agent3D[Zhang等,2024c]利用VLMs执行基于用户定义查询的开放词汇3D检测,使机器人能够在复杂的室内场景中定位诸如“椅子后面的红色杯子”这样的物体。同样,SpatialVLM[Chen等,2024d]引入了一种空间基础的视觉-语言框架,通过对RGB-D输入的推理,检测并描述具有空间上下文的3D物体。这些模型不仅能够识别物体,还能够推理物体之间的空间关系、功能性和以人为本的目标。这将3D感知从纯粹的几何任务提升为一种认知任务,在这种任务中,模型能够理解诸如“找到树左下角的熟透苹果”这样的指令。虽然VLM趋势的爆发程度没有LLMs那么激烈,但它们显示出稳步上升的良好轨迹,标志着朝着真正智能、语义感知的3D系统的更广泛转变的初期阶段。随着多模态模型能力的扩展,VLMs有望在AI驱动的应用中架起感知与认知之间的桥梁。
综述目标
本综述的目标是系统地调查使用VLMs进行3D物体检测的发展格局,并评估它们在将空间感知与语义理解结合的日益重要作用。我们首先考察3D物体检测的基础概念,它从基于几何的方法发展到多模态框架的演变,以及与传统2D检测的区别。接下来,我们探讨传统的3D检测架构,包括PointNet++ [Sheshappanavar和Kambhamettu,2020]、VoxelNet [Chen等,2023b;Sindagi等,2019]和PV-RCNN [Shi等,2020],以建立对比基准。在此基础上,我们回顾基于VLM的最新方法,突出它们的开放词汇能力、语义基础和跨模态对齐。我们深入探讨了底层架构、预训练和微调策略,以及检测输出的可视化,以理解VLMs如何在3D空间中感知和推理。本综述还进一步比较了传统方法和基于VLM的方法,分析了各自的优缺点和权衡。关键地,我们分析了当前数据可用性、基础对齐精度和计算可扩展性方面的挑战,并提出了潜在的解决方案,如多模态数据集扩展和混合模型集成。通过回顾100多篇论文,本研究旨在为研究人员提供全面的路线图,深入了解VLMs赋能的3D物体检测的现有能力和未来发展方向。