我们很高兴地在此宣布 Gluon Time Series (https://gluon-ts.mxnet.io) 正式开源了!GluonTS 是一个由亚马逊的科学家们开发的,用于构建、评估以及比较基于深度学习的时间序列模型的 python 工具包。GluonTS 基于 Apache MXNet 的 Gluon 接口,为搭建时间序列模型提供更简洁高效的组件。本文将介绍 GluonTS 工具包的关键功能,并演示如何应用 GluonTS 来解决时间序列预测问题。
时间序列建模任务
顾名思义,时间序列即按时间排列的数据的集合。时间序列自然存在于各种场景中,常由在一个固定时间段中测量某些过程而得到。比如说,零售商在每个营业日结束时会计算并记录这一天售出了多少商品。对于单个商品而言,这样的记录就是一个每日销量的时间序列。抑或是电力公司测量每个家庭在某一个时段(例如每小时)的用电量,这样就得到了电力消耗的一个时间序列。还有,亚马逊云服务的用户会使用 Amazon CloudWatch 来记录资源和服务的各项指标,这样会产生各种指标的时间序列。一个典型的时间序列如下所示,纵轴显示测量得到的值,横轴显示时间:
![]()
针对一组时间序列,你或许想知道如下问题的答案:
时间序列在未来会如何变化?——预测
时间序列在某一时间段的行为是否异常?——异常检测
某一时间序列属于哪一个类别?——时间序列分类
某些未能记录到的值应该是多少?——缺失数据填充
GluonTS 可以使构建时间序列模型——对于产生时间序列的过程的数学描述变得更简单,在你解决以上问题的道路上助你一臂之力。在众多时间序列模型中,GluonTS 侧重于基于深度学习的模型。
GluonTS 主要功能及组件
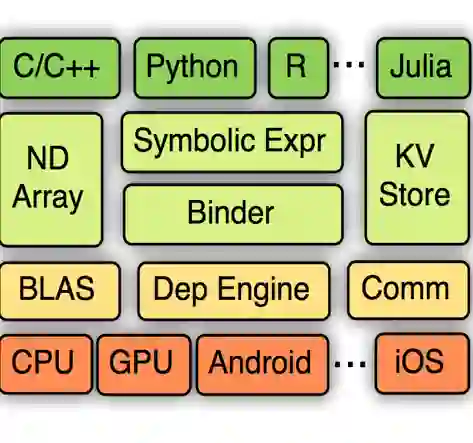
GluonTS 提供的组件可以让构造基于深度学习的时间序列模型更加简单和高效。时间序列领域的深度学习模型通常包含例如基于长 - 短期记忆单元的循环神经网络、卷积操作和注意力机制等模块,这些模块也存在于自然语言处理和计算机视觉等领域的模型中。由于这一点,使用 Apache MXNet 这样的深度学习框架来进行开发和实验是一个非常方便的做法。
然而,针对时间序列的建模也会用到一些仅在这个领域内才会使用的组件。GluonTS 基于 Apache MXNet 的 Gluon 接口构建了以下模块:
GluonTS 的大多数组件可以用于任意之前提到的时间序列建模场景,不过目前 GluonTS 的模型实现及周边工具还是重点着力在预测任务上。
使用 GluonTS 进行时间序列预测
下面我们将一起使用 GluonTS 提供的一个时间序列模型,在一个真实的时间序列数据集上进行预测。在这个例子中,我们将使用实现了 DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks 这篇论文中提出的 DeepAR 模型的 DeepAREstimator。给定一个或更多个时间序列,我们要训练 DeepAR 模型,让它能基于之前的 context_length 值预测下一个 prediction_length 值。DeepAR 模型并不是对每个未来的时间点提供单一的预测值,而是针对每个输出点给出一个参数化的概率分布。GluonTS 使用一对 Estimator/Predictor 的抽象概念来封装训练好的模型,相信接触过其他机器学习框架的用户对这样的抽象一定不会陌生。一个 Estimator 表示一个可被训练的模型,训练后可以得到一个 Predictor,Predictor 可以用来在测试数据上进行预测。要建立一个 DeepAREstimator 对象,需要提供以下的超参数:
当然,你也可以提供一个 Trainer 对象来提供其他的超参数,用于设定训练过程中的其他细节,但现在让我们先使用缺省的超参数快速得到一个 DeepAREstimator。
from gluonts.model.deepar import DeepAREstimator
from gluonts.trainer import Trainer
estimator = DeepAREstimator(freq="5min",
prediction_length=36,
trainer=Trainer(epochs=10))
在真实数据集上训练模型
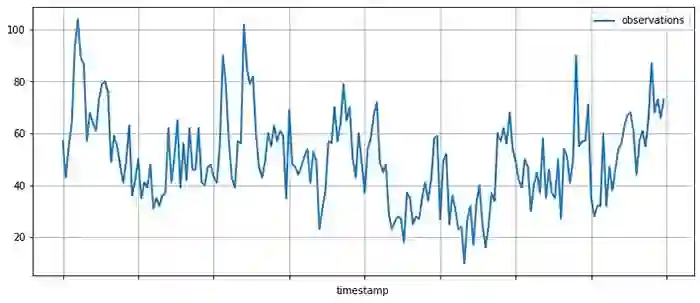
得到 Estimator 之后,现在可以用一些数据来训练这个模型了。在这里我们使用一个记录了提到 AMZN 股票代号的推特数量的公开数据集。用 pandas 下载并显示这个数据集,如下:
import pandas as pd
import matplotlib.pyplot as plt
url = "https://raw.githubusercontent.com/numenta/NAB/master/data/realTweets/Twitter_volume_AMZN.csv"
df = pd.read_csv(url, header=0, index_col=0)
df[:200].plot(figsize=(12, 5), linewidth=2)
plt.grid()
plt.legend(["observations"])
plt.show()
![]()
GluonTS 提供了 Dataset 抽象层来统一各种不同输入格式的读取。在这里,我们使用 ListDataset 来读取在内存中以字典列表形式存储的数据。在 GluonTS 中,任何 Dataset 对象都是一个将字符串键值映射到任意值的字典的迭代器。将数据截断到 2015 年 4 月 5 日为止,用于训练模型。在 4 月 5 日之后的数据将被用于测试训练好的模型。
from gluonts.dataset.common import ListDataset
training_data = ListDataset(
[{"start": df.index[0], "target": df.value[:"2015-04-05 00:00:00"]}],
freq = "5min"
)
数据集在手,现在就可以使用刚才建立的 Estimator 的 train 接口来训练模型。当训练完成之后,你就会得到一个可以进行预测的 Predictor 对象。
predictor = estimator.train(training_data=training_data)
模型评估
现在你可以使用 Predictor 来画出模型对于在训练数据之后的时间段的一些预测。绘出模型给出的预测有助于我们对这个模型的预测质量有一个定性的感受。现在,基于同样的数据集,在之前用于训练的时间段之后的时间段取出若干组测试数据。
test_data = ListDataset(
[
{"start": df.index[0], "target": df.value[:"2015-04-10 03:00:00"]},
{"start": df.index[0], "target": df.value[:"2015-04-15 18:00:00"]},
{"start": df.index[0], "target": df.value[:"2015-04-20 12:00:00"]}
],
freq = "5min"
)
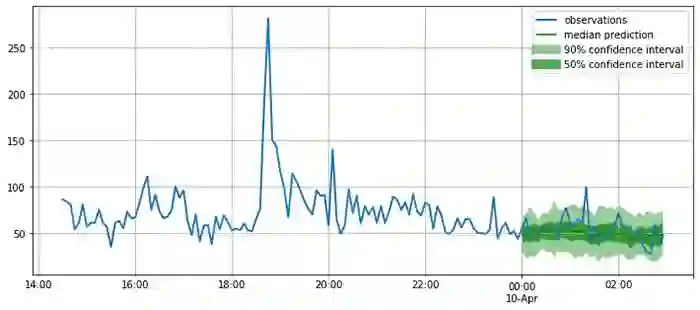
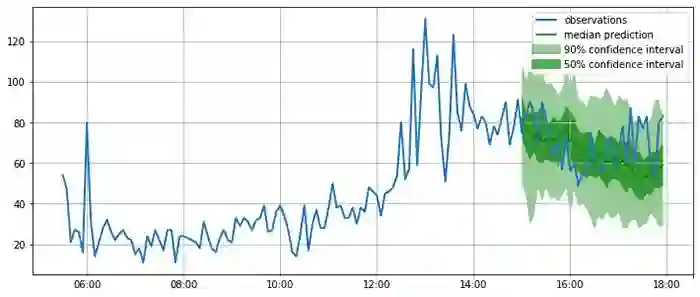
如下图所示,模型给出的是概率预测,这是很重要的一点,因为概率预测提供了对于模型置信度的估计,并且可以使得下游基于此预测的决策能够考虑到预测的不确定性。
from itertools import islice
from gluonts.evaluation.backtest import make_evaluation_predictions
def plot_forecasts(tss, forecasts, past_length, num_plots):
for target, forecast in islice(zip(tss, forecasts), num_plots):
ax = target[-past_length:].plot(figsize=(12, 5), linewidth=2)
forecast.plot(color='g')
plt.grid(which='both')
plt.legend(["observations", "median prediction", "90% confidence interval", "50% confidence interval"])
plt.show()
forecast_it, ts_it = make_evaluation_predictions(test_data, predictor=predictor, num_eval_samples=100)
forecasts = list(forecast_it)
tss = list(ts_it)
plot_forecasts(tss, forecasts, past_length=150, num_plots=3)
![]()
![]()
![]()
看起来预测还算准确!现在我们可以定量地使用一系列指标来定量评估预测的质量。GluonTS 提供了用于评估模型的 Evaluator 模块。Evaluator 模块提供了常用的误差指标,例如 MSE、MASE、symmetric MAPE、RMSE 以及(加权)量化误差等。
from gluonts.evaluation import Evaluator
evaluator = Evaluator(quantiles=[0.5], seasonality=2016)
agg_metrics, item_metrics = evaluator(iter(tss), iter(forecasts), num_series=len(test_data))
agg_metrics
{'MSE': 163.59102376302084,
'abs_error': 1090.9220886230469,
'abs_target_sum': 5658.0,
'abs_target_mean': 52.38888888888889,
'seasonal_error': 18.833625618877182,
'MASE': 0.5361500323952336,
'sMAPE': 0.21201368270827592,
'MSIS': 21.446000940010823,
'QuantileLoss[0.5]': 1090.9221000671387,
'Coverage[0.5]': 0.34259259259259256,
'RMSE': 12.790270668090681,
'NRMSE': 0.24414090352665138,
'ND': 0.19281054942082837,
'wQuantileLoss[0.5]': 0.19281055144346743,
'mean_wQuantileLoss': 0.19281055144346743,
'MAE_Coverage': 0.15740740740740744}
你可以将以上指标与其他模型或是你的预测应用的业务要求作比较。例如,我们可以用 Seasonal Naive Method 进行预测,然后与以上结果比较。Seasonal Naive Method 假设数据会有一个固定的周期性(本例中,2016 个数据点是一周,作为一个周期),并通过基于周期性来复制之前观察到的训练数据进行预测。
from gluonts.model.seasonal_naive import SeasonalNaivePredictor
seasonal_predictor_1W = SeasonalNaivePredictor(freq="5min", prediction_length=36, season_length=2016)
forecast_it, ts_it = make_evaluation_predictions(test_data, predictor=seasonal_predictor_1W, num_eval_samples=100)
forecasts = list(forecast_it)
tss = list(ts_it)
agg_metrics_seasonal, item_metrics_seasonal = evaluator(iter(tss), iter(forecasts), num_series=len(test_data))
df_metrics = pd.DataFrame.join(
pd.DataFrame.from_dict(agg_metrics, orient='index').rename(columns={0: "DeepAR"}),
pd.DataFrame.from_dict(agg_metrics_seasonal, orient='index').rename(columns={0: "Seasonal naive"})
)
df_metrics.loc[["MASE", "sMAPE", "RMSE"]]
![]()
通过比较以上这些指标,就可以得到你的模型与基线模型或其他高阶模型的对比。想要进一步提升模型性能的话,可以尝试改进模型架构,或者调节超参数的值。
一起给 GluonTS 添砖加瓦!
这篇博客中,我们仅仅触及了 GluonTS 强大功能的冰山一角,要了解更多,请移步教程 (https://gluon-ts.mxnet.io/examples/index.html) 学习更多样例。GluonTS 是使用 Apache 证书的开源项目,我们非常欢迎来自社区的漏洞报告以及代码贡献。现在就去 GluonTS 的 github 主页 (https://github.com/awslabs/gluon-ts) 看看吧!