谷歌推出了全新的开源模型系列「Gemma」。相比 Gemini,Gemma 更加轻量,同时保持免费可用,模型权重也一并开源了,且允许商用。

Gemma 官方页面:https://ai.google.dev/gemma/ 总体来说,Gemma 是一个轻量级的 SOTA 开放模型系列,在语言理解、推理和安全方面表现出了强劲的性能。

技术报告链接:https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
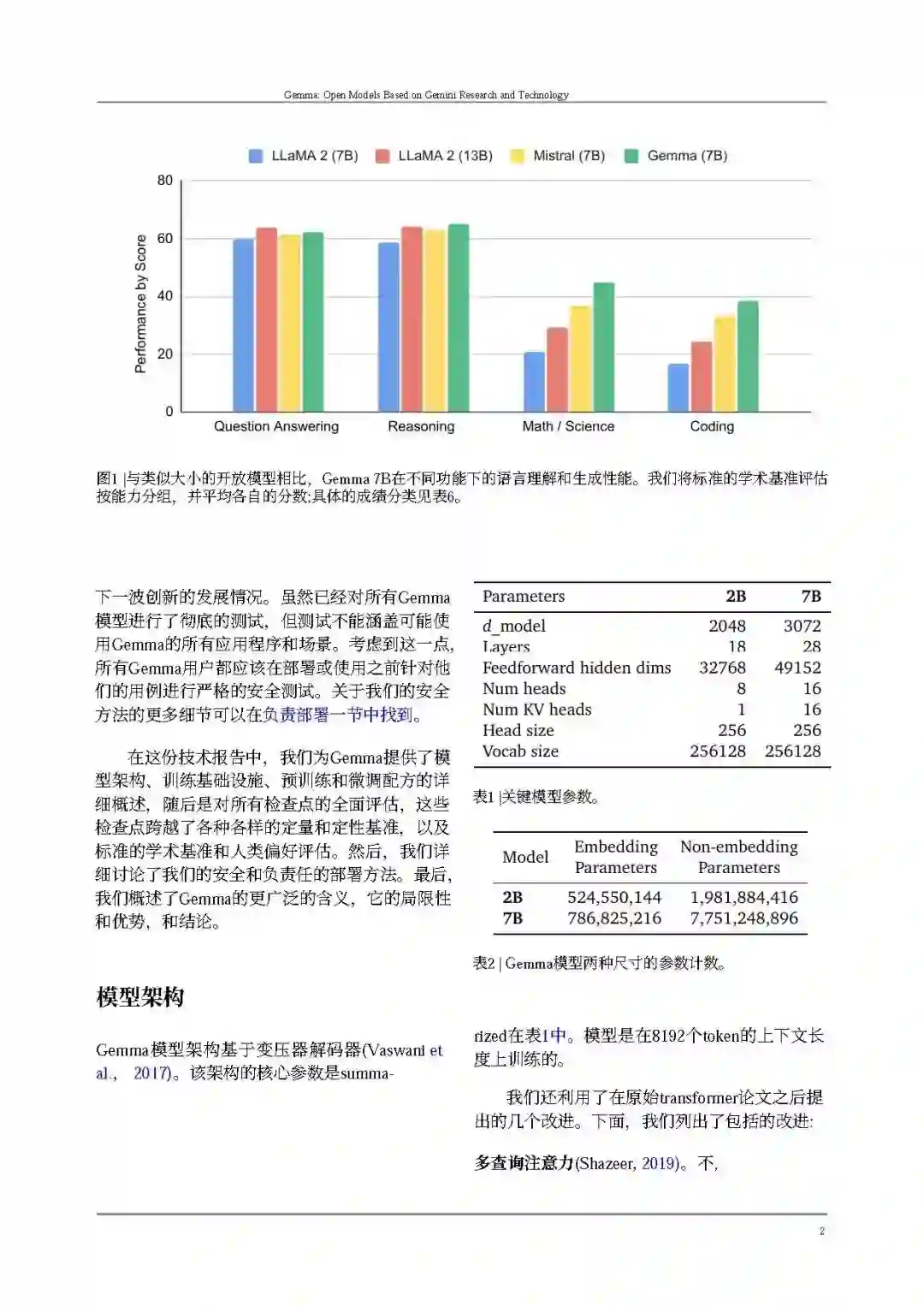
谷歌发布了两个版本的 Gemma 模型,分别是** 20 亿参数和 70 亿参数**,并提供了预训练以及针对对话、指令遵循、有用性和安全性微调的 checkpoint。其中** 70 亿参数的模型用于 GPU 和 TPU 上的高效部署和开发,20 亿参数的模型用于 CPU 和端侧应用程序**。不同的尺寸满足不同的计算限制、应用程序和开发人员要求。
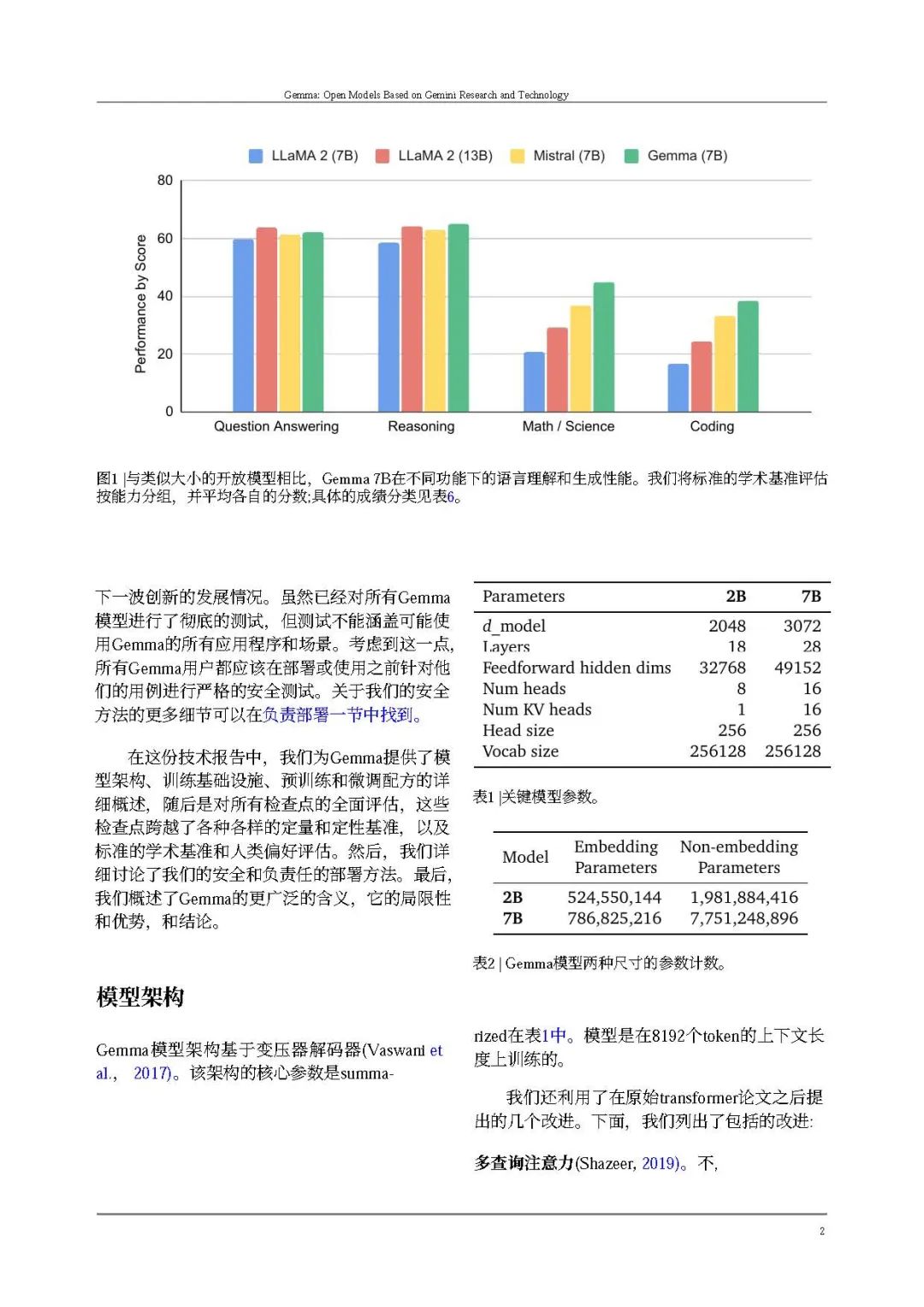
Gemma** 在 18 个基于文本的任务中的 11 个上优于相似参数规模的开放模型**,例如问答、常识推理、数学和科学、编码等任务。
我们介绍了Gemma,一系列基于Google的Gemini模型(Gemini团队,2023年)的开放模型。我们训练Gemma模型,使用的文本令牌高达6T,采用与Gemini模型家族类似的架构、数据和训练配方。与Gemini一样,这些模型在文本领域实现了强大的通用能力,以及在规模上的最先进的理解和推理技能。通过这项工作,我们发布了预训练和微调的检查点,以及用于推理和服务的开源代码库。 Gemma有两种规模:一种是7亿参数模型,用于GPU和TPU上的高效部署和开发;另一种是2亿参数模型,用于CPU和设备上的应用。每种规模都旨在满足不同的计算约束、应用和开发者需求。在每个规模上,我们都发布了原始的、预训练的检查点,以及为对话、指令遵循、有用性和安全性微调的检查点。我们对我们模型的缺点进行了一系列定量和定性基准测试的彻底评估。我们相信,预训练和微调检查点的发布将促进对当前指令调整机制的影响的彻底研究和调查,以及日益安全和负责任的模型开发方法论的发展。
Gemma在与相似规模(以及一些更大的)开放模型(Almazrouei等人,2023年;Jiang等人,2023年;Touvron等人,2023年a,b)相比,推进了最先进性能,在包括自动化基准和人类评估在内的广泛领域中。示例领域包括问题回答(Clark等人,2019年;Kwiatkowski等人,2019年)、常识推理(Sakaguchi等人,2019年;Suzgun等人,2022年)、数学和科学(Cobbe等人,2021年;Hendrycks等人,2020年)以及编码(Austin等人,2021年;Chen等人,2021年)。详见评估部分。
像Gemini一样,Gemma建立在序列模型(Sutskever等人,2014年)和transformers(Vaswani等人,2017年)、基于神经网络的深度学习方法(LeCun等人,2015年)以及在分布式系统上进行大规模训练的技术(Barham等人,2022年;Dean等人,2012年;Roberts等人,2023年)之上。Gemma还建立在Google长期的开放模型和生态系统的基础上,包括Word2Vec(Mikolov等人,2013年)、Transformer(Vaswani等人,2017年)、BERT(Devlin等人,2018年)和T5(Raffel等人,2019年)以及T5X(Roberts等人,2022年)。
我们认为负责任地发布大型语言模型(LLMs)对于提高前沿模型的安全性、确保公平访问这项突破性技术、使当前技术的严格评估和分析成为可能,以及使下一波创新的发展成为可能至关重要。尽管对所有Gemma模型进行了彻底测试,但测试无法覆盖Gemma可能被使用的所有应用和场景。考虑到这一点,在部署或使用前,所有Gemma用户都应对其用例进行严格的安全测试。有关我们对安全方法的更多细节,可以在“负责任部署”部分找到。
在这份技术报告中,我们提供了Gemma的模型架构、训练基础设施以及预训练和微调配方的详细概述,接着是对所有检查点在广泛的定量和定性基准测试中的彻底评估,以及标准学术基准测试和人类偏好评估。然后,我们详细讨论了安全和负责任部署的方法。最后,我们概述了Gemma的更广泛影响、其局限性和优势,以及结论。