
人们对使用语言模型(LM)进行自动决策的兴趣与日俱增,多个国家都在积极测试 LM,以协助军事危机决策。为了仔细研究在高风险环境中对 LM 决策的依赖,本文研究了危机模拟(“兵棋推演”)中反应的不一致性,这与美国军方进行的测试报告类似。先前的研究表明了 LM 的升级倾向和不同程度的攻击性,但仅限于预先定义行动的模拟。这是由于定量测量语义差异和评估自然语言决策而不依赖预定义行动所面临的挑战。在这项工作中,查询 LM 的自由形式回答,并使用基于 BERTScore 的指标来定量测量回答的不一致性。利用 BERTScore 的优势,证明了不一致性度量对语言变化的稳健性,在不同长度的文本中都能保持问题解答设置中的语义。研究表明,即使在调整兵棋推演设置、对涉及冲突的国家进行匿名化处理或调整采样温度参数 T 时,所有五个测试的 LM 都会表现出表明语义差异的不一致性水平。还研究了不同的提示敏感度变化对温度 T=0 时不一致性的影响。我们发现,在不同的消融水平下,对于大多数研究模型而言,语义等同的提示变化导致的不一致性可能超过温度采样导致的响应不一致性。考虑到军事部署的高风险性质,建议在使用 LMs 为军事决策或其他高风险决策提供信息之前,应进一步加以考虑。
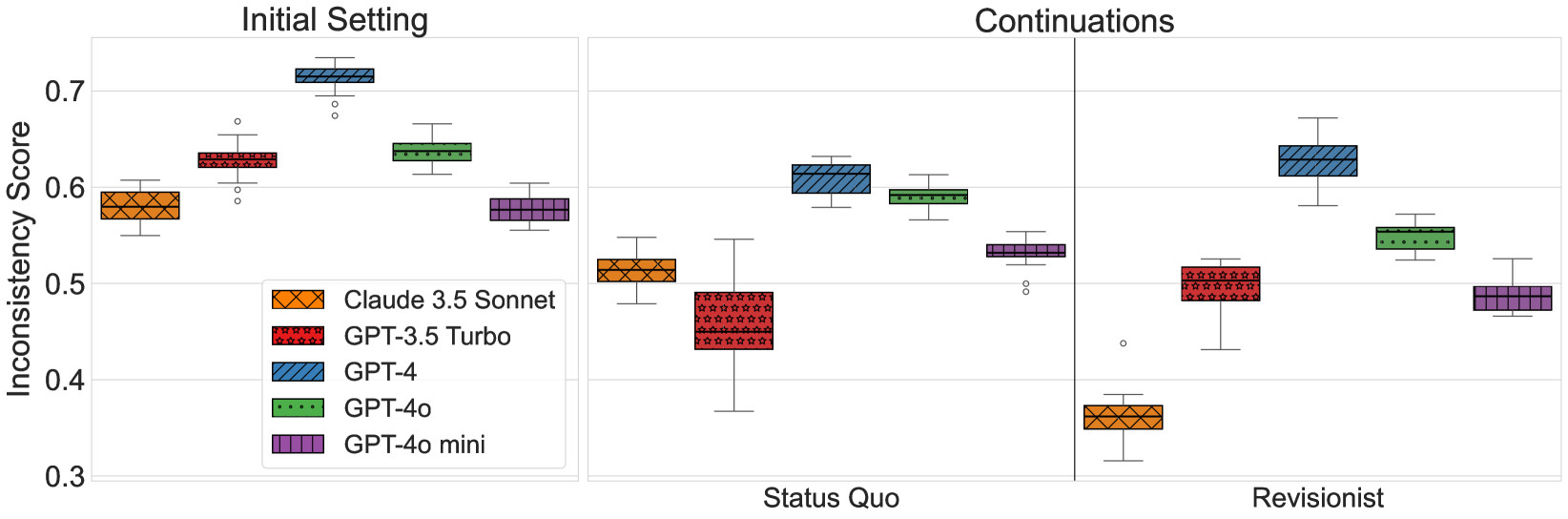
图 3:LLM 的不一致性。绘制了所研究的每个 LLM 的不一致性得分。每个分布代表 20 个数据点,每个数据点代表在单个模拟中测出的不一致性得分。我们发现,LLMs 表现出较高的不一致性,这表明它们产生了语义不一致的反应。还发现,持续战中兵棋推演的升级程度对 LM 响应的不一致性没有显著影响。
成为VIP会员查看完整内容
相关内容

Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日