推荐!《不确定性下的作战决策:推理、序贯和对抗性方法》美国空军293页博士论文,含代码



引言
-
第二章回顾了不确定性下的决策和优化的文献,重点是模糊性模型和优化实践的最新进展。 -
第三章对第二章中定量文献的理论回顾进行了补充,对定性的不确定性和军事评估实践的应用进行了调查。第四章、第五章和第六章在第二章和第三章的基础文献的基础上,分别探讨了静态、动态和多Agent环境下的不确定性决策。 -
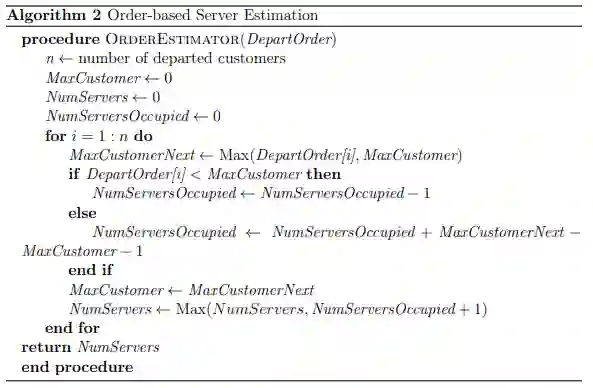
第四章开发了一种新的方法,用于对部分可观察的、随机的到达和离开时间进行稳健的队列推理。这个一般的方法适用于任意的队列,但具体的动机是网络安全和恐怖主义的应用。 -
第五章开发了一种在动态的、部分可观察的和模糊的环境中进行稳健信息收集的新方法,并扩展应用于网络安全检测问题。 -
第六章介绍了一个新的应用,即利用最优和近似技术解决具有不完善信息的广义形式游戏的多域网络和防空问题。
1.1 总结
1.2 贡献




便捷下载,请关注专知人工智能公众号(点击上方关注)
点击“发消息” 回复 “ODMU” 就可以获取《推荐!《不确定性下的作战决策:推理、序贯和对抗性方法》美国空军293页博士论文,含代码》专知下载链接



登录查看更多
相关内容
Arxiv
0+阅读 · 2023年1月13日

相关VIP内容
相关资讯