

游戏智能体的发展在推进向人工通用智能(AGI)的道路上扮演着至关重要的角色。大型语言模型(LLMs)及其多模态对应物(MLLMs)的进展为在复杂的电脑游戏环境中赋予游戏智能体类似人类的决策能力提供了前所未有的机会。本文从一个全面的视角对基于LLM的游戏智能体进行了综述。首先,我们介绍了基于LLM游戏智能体的概念架构,围绕六个基本功能组件:感知、记忆、思考、角色扮演、行动和学习。其次,我们调研了文献中记录的现有代表性的基于LLM游戏智能体,这些智能体在方法论和跨六大游戏类型的适应性灵活性方面进行了探讨,包括冒险、沟通、竞争、合作、模拟以及制作与探索游戏。最后,我们展望了这一新兴领域未来研究和发展的方向。维护并可访问的相关论文精选列表位于:https://github.com/git-disl/awesome-LLM-game-agent-papers。
智能在代理与环境的互动中以及作为感觉运动活动的结果而出现。 ——体现认知假说 [1] 大型语言模型(LLMs),如ChatGPT [2]所示,代表了自然语言理解(NLU)和生成性人工智能(Gen-AI)中的一个重要里程碑。通过在包含数百亿参数的大量多样化网络来源上进行生成性训练,LLMs展示了从庞大文本语料库中概括知识的惊人能力,并以接近人类水平的NLU表现展示对话智能。多模态LLMs(MLLMs),如GPT-4V [3]和Gemini [4]的出现,标志着另一个里程碑,使LLMs能够感知和理解视觉输入。我们推测,LLM技术的成功为追求类人人工通用智能(AGI)提供了前所未有的机会:以前认为仅限于人类的认知能力,如推理、规划和反思,以及自我控制、自我理解和自我改进的程度,现在通过适当提示集成了内置认知智能的LLMs来实现。
我们将基于LLM的智能体(LLMA)定义为一个智能实体,它使用LLMs1作为执行类人决策过程的核心组件 [5]。尽管LLMAs能够进行类似人类的认知处理,但现有LLMAs与类人AGI之间的区别是显而易见的:当前的LLMAs依赖于解码和概括来自预训练数据的预先存在的知识 [6],而AGI能够通过在现实世界中的实验和经验发现和学习新知识 [7; 8]。受到人类婴儿智力发展过程的启发,体现认知假说 [1] 假设智能体的智能源于观察和与其环境的互动,即,将智能体植入一个集成了物理、社会和语言经验的世界对于促进有利于发展类人智能的条件至关重要。
数字游戏被认为是培养AI智能体的理想环境,因为它们具有复杂性、多样性、可控性、安全性和可复制性。从经典的国际象棋和扑克游戏 [9; 10; 11] 到现代视频游戏如Atari游戏 [12]、星际争霸II [13]、Minecraft [14] 和DOTA II [15],长期以来一直是推进AI研究的工具。与基于传统强化学习(RL)的智能体 [10; 16; 17; 18] 不同,这些智能体通过行为级策略学习做出决策,目标是最大化预期奖励,构建能够运用认知能力获得游戏玩法基本洞察力的基于LLM的游戏智能体(LLMGAs)可能更贴近AGI的追求。 先前关于LLMs [19; 20; 21] 或LLMAs [22; 23; 24] 的综述论文主要关注审查行业和学术研究团队开发的现有LLMs,以及LLMAs的一般应用,较少关注游戏代理领域。同时期的综述论文 [25; 26] 显著强调了游戏开发,并涵盖了有限数量的LLMGAs出版物。为了弥补这一差距,本文试图对LLMGAs的最新发展进行全面和系统的综述。具体而言,本综述分为三个相辅相成的部分:首先,我们提供了一个统一的参考框架,在其中我们描述了构建LLMGAs所需的基本模块,涵盖六个核心功能组件:感知、记忆、思考、角色扮演、行动和学习。其次,我们介绍了一个将现有文献分类为六个游戏类别的分类法,包括冒险、竞争、合作、模拟和制作与探索。对于每个类别,我们描述了技术挑战、支持的游戏环境,以及常用的优化策略。在第三部分和最后一部分,我们设想LLMGAs未来进步的不同方向。
总之,这篇综述论文作为对LLMGAs文献的全面回顾,提供了六个游戏类别的分类,以增强理解并促进各种LLMGAs的开发和评估。它旨在促进这一新兴研究领域的进步,并激发LLMGAs的研究和开发中的进一步创新。鉴于这是一个新兴且蓬勃发展的研究领域,这篇综述论文将持续更新,以跟踪最新研究。维护并可访问的相关文献精选列表位于https://github.com/git-disl/awesome-LLM-game-agent-papers。
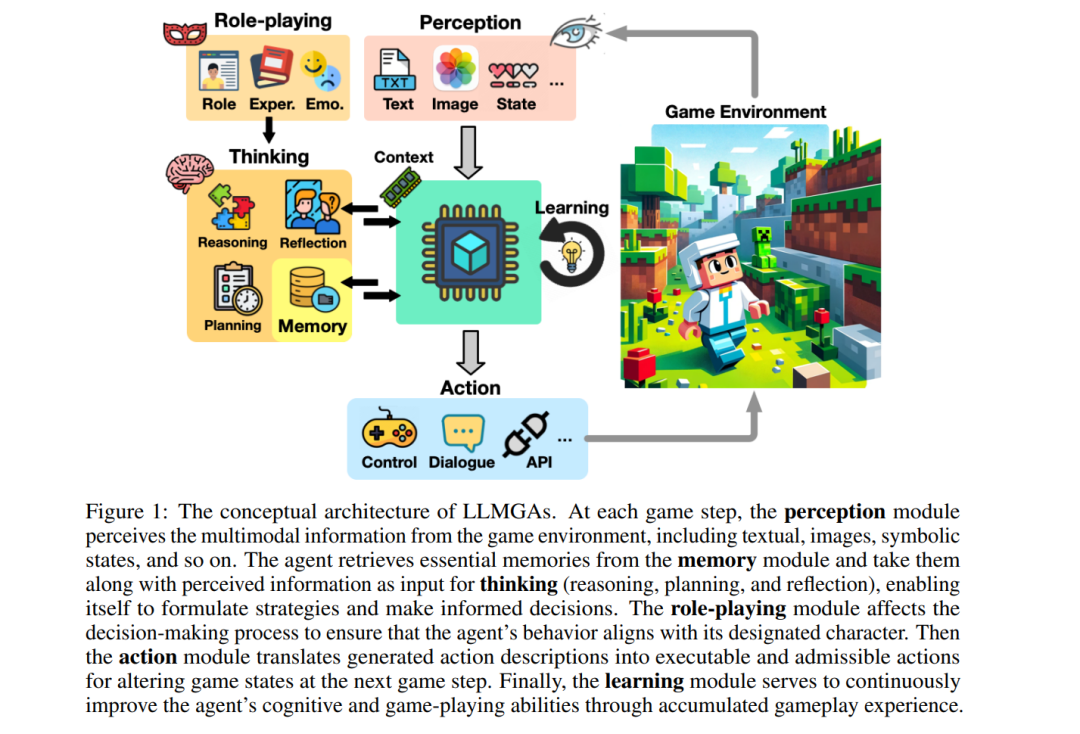
统一的LLMGAs架构
图1提供了LLMGAs的概念架构,包括六个基本功能组件及其工作流程:对于每个游戏步骤,感知模块捕获游戏状态信息,为智能体理解其当前环境提供必要的数据。思考模块处理感知到的信息,基于推理、规划和反思生成思考,以便做出明智的决策。记忆作为一个外部存储,过去的经验、知识和精心挑选的技能被保留,并可以为将来使用而检索。角色扮演模块使智能体能够在游戏中模拟特定角色,展示与每个角色的特征和目标一致的可信行为。行动模块将生成的文本决策转换为可执行的动作,允许智能体有效地与游戏元素互动和操纵。学习模块通过在游戏环境中积累的经验和互动,不断改善智能体的认知和游戏技能。
