

为利用智能技术解决现代战争中的意图判断、威胁评估与指挥控制, 提高军事决策水平, 将军事问题转化为博弈问题, 综 合利用博弈论和人工智能(artificial intelligence, AI)技术寻求策略均衡解. 通过深入剖析游戏智能博弈的最新进展, 梳理美军人工 智能军事应用项目研究情况, 总结常用智能方法的优缺点, 分析军事博弈面临的挑战及应对措施, 为突破复杂战场环境下高动态 不确定的军事智能决策问题提供借鉴.
现代战争无疑是一场激烈博弈, 随着信息化程 度不断提高, 作战空间由物理域、信息域向认知域拓 展[1] , 快变的战场态势、紧凑的作战节奏以及跨域军事力量运用对作战指挥的时效性和精确性提出了更 高要求. 敌方意图判断、行动威胁评估、指挥决策与 控制的难度不断增加, 迫切需要利用智能技术延伸 人脑, 以提高军事决策的自动化和自主化水平, 决策 智能成为军事领域研究热点之一. 近年来, 诸多游戏博弈系统在边界和规则确定 的对抗中取得了显著成绩, 不仅极大推动了认知智 能发展, 更为军事决策智能研究指明了探索方向[2] . 智能博弈也称为机器博弈 (computer game), 主要研 究如何让机器像人一样在竞争环境下进行对抗, 属 于认知智能范畴. 众多知名学者很早便开始涉足该 领域研究, 如冯·诺依曼、香农、图灵和塞缪等[3] . 随着 计算机硬件不断升级, 智能博弈理论和技术迅猛发 展. IBM 于 1997 年开发“深蓝(deep blue)”系统, 以 绝对优势战胜了卡斯帕罗夫, 成为智能博弈系统“叫 板”人类的历史性里程碑[4] . Deep Mind 于 2016 年至 2017 年相继推出围棋 AlphaGo 系列 AI 系统, 成功解 决了有限状态零和完全信息两人博弈问题[5-7];美国 卡耐基梅隆大学分别于 2017 年和 2019 年开发了 Li原 bratus 系统和 Pluribus 系统[8-9] , 突破了多人游戏智能 博弈的壁垒. 继以围棋、德州扑克等序贯博弈之后, 以实时策略游戏为代表的同步博弈问题成为新的 研究热点, Deep Mind 在 2019 年公布的 AlphaStar 系 统的底层技术[10] , 对未来开发具有安全性、鲁棒性和 实用性的通用 AI 系统具有重要意义. 然而军事对抗 不同于游戏博弈, 两者存在显著区别[11] , 难以直接借 鉴应用.
本文阐述了军事智能博弈的概念及应用前景, 提出在博弈论框架下利用 AI 技术应寻找策略均衡 解, 而非传统求解最优解. 通过比较完全信息、不完 全信息和即时战略类游戏的特点, 深入剖析不同智 能博弈技术框架的原理, 梳理美军智能决策项目的 最新发展情况, 而后根据战争复杂性特征, 分析军事 博弈面临的主要困难以及智能技术军事应用的挑战. 有助于把握智能博弈最新进展, 为军事决策智能发展储备必要的理论与技术, 进而为利用 AI 技术突破 复杂战场环境下高动态不确定的决策问题提供借鉴.
1 军事智能博弈
军事智能博弈(military intelligence game, MIG), 是指将军事问题转化为博弈问题, 综合利用博弈论 (game theory)和 AI 技术寻求军事对抗中的策略均衡 解. 博弈论为解决军事问题提供了理论框架, AI 技术 为策略求解提供了高效方法. 随着智能理论与技术 的迅猛发展, 博弈论和 AI 技术在现实应用中结合的 更加紧密, 为突破军事决策智能发展瓶颈提供了新 思路. 军事智能博弈具有广阔的应用场景, 如图 1 所 示. 利用智能博弈技术构建虚拟蓝军, 为作战方案分 析、武器装备检验和人员技能训练提供逼真的作战 对手, 可获得更好的客观真实性;智能博弈系统可充 当“决策大脑”或“智能参谋”, 面向动态战场环境快 速生成博弈策略, 辅助指挥员开展对抗推演, 并在训 练中与人类共同学习, 不断提升指挥决策能力;构建 智能博弈对抗平台, 作战模拟仿真系统虽然大大降 低了实兵对抗训练组织难、消耗大的弊端, 但大规模 联合作战推演仍需上百人员协作, 智能博弈平台上 双方“智能体”自主对抗, 不仅能对作战方案进行快 速验证, 还能通过分析智能体行为发现新战法.

军事智能博弈主要有两大研究内容:一是军事博 弈规则构建. 局中人为最大化自身利益进行决策, 不 同的规则设计将会导致策略选择的不同, 如何设计 博弈规则以使最终均衡解达到整体利益最大化成为 首要问题. 二是博弈策略求解, 博弈论提供了问题建模 框架, 纳什定理证明了均衡解的存在性, 但现实问题 的求解通常面临状态决策空间大、信息不完备等问 题, 如何利用高效算法搜索最优策略成为关键问题.
2 智能博弈研究现状
梳理游戏智能博弈最新成果和美军智能决策项 目发展情况, 深入剖析所用理论方法和技术框架, 有 助于把握领域的研究进展和方向.
2.1 游戏智能博弈研究
研究人员一直热衷于将游戏作为测试和评估 AI 算法的平台, 从最初的 Atari 游戏到后来的围棋、德 州扑克和星际争霸等, 人类攻克了越来越复杂的游 戏堡垒, 其技术方法为解决现实问题和实现通用人 工智能奠定了基础.
2.1.1 完全信息博弈游戏
完全信息博弈中, 局中人可获取即时完整的决 策信息, 双方行动有先后顺序, 并能在有限步后得到 结果, 是研究成果最显著的领域, 如围棋、国际象棋. 该类问题通常采用博弈树搜素算法, 将博弈过程转 化为树的扩展过程. 博弈树的根节点为初始状态, 子 节点表示在根节点选择动作后达到的新状态(state), 从一个节点通向其他节点的边表示动作(action), 通 过评估叶节点来判断博弈结果. 树中每一层代表了 双方的状态, 同层中的所有边为局中人在状态下所 有可选动作, 局中人在不同层间交替执行动作, 允许 一次执行若干动作但只看作是一个动作. 博弈目的 就是寻找博弈树根节点的最优子节点, 而通往最优 子节点的动作即为最优动作.
2.1.2 不完全信息博弈游戏
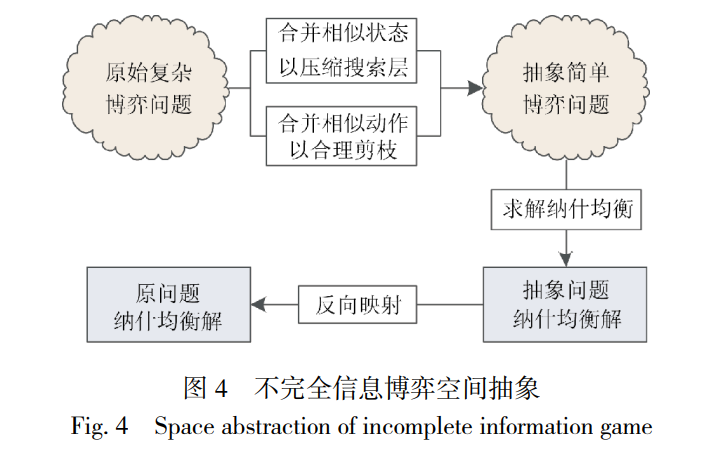
不完全信息博弈中, 局中人行动顺序虽有先后, 但无法完全获取其他局中人的特征、收益及策略空 间等决策信息, 如德州扑克、麻将等. 不完全信息博 弈更符合现实场景, 但求解纳什均衡解的复杂度和 难度也更大. 由于信息的非完备性和局势的动态变 化, 需对其他局中人的未知信息进行推理和猜测, 同 一状态下采取的行动可能有多种, 甚至可以利用信 息迷雾进行欺骗, 通常需要根据局势缩小博弈搜索 空间, 如图 4 所示.
2.1.3 即时战略博弈
即时战略游戏(real time strategy, RTS)具有以下 特点:局中人需同时决策是否采取行动以及采取何 种行动, 而非轮流决策;局中人需在短时间内进行一 系列决策并付诸实施, 以满足实时对抗要求, 而动作 可能需要持续一段时间, 完全不同于棋牌类游戏“决策的交替性和间断性、动作的瞬时性和突发性”;游 戏中存在各种功能角色, 如何发挥各角色作用和协 作效果, 是制定最优策略的关键问题;游戏中多角色 多任务、高度不确定性和不完备不完美信息等问题, 导致状态空间规模和决策可选动作十分巨大;由于 无法准确预测对手行为, 游戏并不存在理论上的最 优解. 因此, RTS 游戏研究对解决具有实时对抗、长 远规划、多角色多任务和信息不完备不完美等特点 的问题更具借鉴意义, 如军事决策、应急规划等.
2.2 美军智能博弈系统应用及进展
美军早已预见智能技术在军事领域的应用前景,力求在“第三次抵消战略”中凭借智能技术形成绝对 军事优势. 美军提出“马赛克战”概念, 希望构建一个 具有超强适应能力的弹性杀伤网络, 实现要素的快 速聚合与分解, 重塑在大国博弈中的竞争力[20] . 智能博 弈技术, 必将成为未来智能化战争条件下进行指挥 决策的基础.
3 智能博弈技术的军事应用展望
3.1 军事博弈面临的困难
战争具有非线性和不确定性, 军事博弈是一个 典型的面向不完美不完备信息的序贯决策和同步博 弈问题, 必须兼顾宏观策略规划和微观战术选择, 平 衡短期利益、长期目标以及意外情况处置能力. 现有 智能博弈技术难以直接利用, 主要因为军事博弈具 有以下突出特点。
3.1.1 战争充满“迷雾”和不确定性
在完全信息博弈中, 双方可以完全掌握棋局状 态, 即使是在德州扑克等非完全信息博弈中, 未知的 牌局信息也只发生在一定概率区间内, 通过多轮博 弈可进行概率判断. 而在真实战场中, 由于预警范围 和侦察注意力受限, 只能从战场环境中获取部分信 息, 而且敌方行动策略和作战企图无法完全知晓, 基 于部分可观察的态势估计是不可回避的. 指挥员需 要在一个非完全信息环境下进行决策, 必须具备高 效准确的侦察、探索、记忆和推测能力, 信息的缺失 导致以求解局部最优来获取全局最优的方式无法完 成策略回溯. 战场各类侦察系统获取的信息可能是随机模糊 的, 敌我双方为隐藏企图而采取各种欺骗行为和佯 装动作, 导致获取的信息不一定准确, 产生“信息获 取的不确定性”;信息在各层级传播和融合过程中, 会出现衰减、丢失和出错等现象, 产生“信息融合的 不确定性”;事物的描述和表示会因知识表示方法不 同而不同, 产生“知识表示的不确定性”;利用证据信 息与军事知识进行战场态势和敌方策略行动推理时, 不同的推理算法会产生不同的估计结果, 产生“推理 结果的不确定性”. 战争信息的高度不确定性, 导致 基于先验知识推理未知领域的方式难以奏效.
3.1.2 军事博弈对抗激烈、连续且非零和
战争博弈日趋激烈. 无论战前还是战中, 博弈发 生在时时刻刻、方方面面, 双方意图互为对抗且此消 彼长. 战争节奏紧张, 战场态势剧变, 双方需要更快速 更准确地进行决策. 决策过程不仅要考虑作战目的和 战场态势, 还要持续判断敌方可能采取的战法和行 动, 更需要在交战过程中反复迭代更新策略, 以掌握 战争主动权. 为保证自身方案计划顺利实施, 达成“出 其不意攻其不备”的效果, 还要巧妙地利用佯装行动 诱骗敌方;相反, 为避免被敌方牵着鼻子走, 也需通过 有效的信息推理来识别和预测敌方的真实意图. 军事决策是动态连续的. 与棋牌类游戏的轮次 博弈不同, 战争态势连续演进, 交战双方决策无顺序 约束, 任何时刻既要决策是否采取行动, 还需决策采 取哪些行动, 决策的速度和准确度共同决定了指挥 效率. 从理论上讲, 可将动态连续决策过程离散为更 精细的时间片段, 而后采用轮次博弈的静态解决方 法. 但战争系统具有整体性和不确定性, 以离散方式 进行抽象建模, 必然需要解决时间尺度、模型精确度 和问题求解复杂度三者之间的关系. 军事博弈具有典型的“非零和”特性. 战争开始 及结束时机, 需要综合考虑政治意图、战略目的、敌 我能力变化和国际环境等, 以实现国家利益最大化. 达成国家利益最大化时, 有可能是双方军事作战在 某一阶段的“双输”“/ 双赢”局势, 也可能是在实现政 治、经济等目的后的“僵持”局势. 这种模糊、复杂、 稀疏及非零和的博弈收益, 无法依靠单一指标的价 值网络来评价。
3.1.3 策略空间巨大且难以达成均衡解
军事博弈具有异常庞大的状态策略空间, 难以 依靠遍历求解或模拟仿真等传统方法进行求解. 指 挥员每次决策都会涉及任务类型、执行单位、空间 和时间的选择, 不同作战单位和作战行动之间的时 间协同、效果协同和任务协同进一步增大了策略空 间. 棋牌类游戏的状态空间复杂度均是有限的, 星际 争霸游戏的状态空间仍在现有算法算力解决范围内. 而解决拥有巨大状态策略空间的军事博弈问题, 不 仅对构建战争抽象模型提出了挑战, 更对软硬件运 算能力提出了要求. 军事博弈策略求解面临三大难题. 一是多方博 弈增大了达成纳什均衡的难度. 在当今全球一体化 现状下, 各国在政治、经济、文化和军事等多方面密 切相连, 战争不仅仅是两国之事, 更多情况下会涉及多国利益. 在多方博弈问题中, 纳什均衡求解的复杂 度随着局中人数量的增加呈指数上升. 二是多军兵 种参战增加了协同难度. 作战力量多元化是联合作 战一大特征, 不同领域作战力量的合理利用和协同 互补是拟制作战方案计划的重要内容, 这也是实现 决策智能无法回避的内容. 三是不存在最优策略能 稳定胜过其他策略. 在策略学习与探索过程中, 策略 之间相互克制和历史遗忘的特性十分明显, 单纯采 用自博弈训练方式, 可能会陷入在不同策略间游移 但水平停滞不前的境地. 由于难以推理敌方策略行 动, 需要在不同子博弈之间寻找平衡. 战争规则的多样性、创新性和复杂性, 进一步增 大了状态策略空间的规模和纳什均衡的求解难度. 战争参与者都试图通过作战行动来达成作战目的, 策略会因战场态势的不断更新而时刻变化, 出奇制 胜和另辟蹊径的战法创新为各方所推崇追寻. 面对 同一战场态势, 各方可能采取不同的响应动作, 而指 挥员的决策风格也不尽相同.
3.1.4 面向任务使命的长程规划难以实现
现代作战已从传统的由外及内逐层消灭敌人的 线性作战, 转变为集中全域力量进行全纵深整体打 击的非线性作战. 战争事件因果关系复杂, 通常难以 在短时间内呈现, 作战行动的执行效果可能在长时 间后才会有所体现. 方案计划的制定要始终围绕使 命任务进行主动筹划和战争设计, 研究作战行动与 作战效果之间的非线性关系. 这种长远且全局的规划视野, 体现了人类指挥 员的指挥艺术和大局观. 美军率先提出基于效果作 战(effect based operation, EBO)概念, 通过逆向规 划将目标分解为具体预期效果. EBO 理论从逻辑上 讲难以实现, 因为在不确定环境中无法确定某一行 动的结果, 同时也忽视了对抗性这一战争本质[23] . 中 外学者通常使用影响网进行研究, 结合博弈论实 现对抗条件下作战方案计划的生成[24] . 强化学习天生 具有“行动-效果”的探索能力, 为解决 EBO 提供了新 思路. 长程规划应能够体现战争设计的前瞻性、各领 域各层级的协同性以及指挥艺术性. 一是主动筹划 行动以掌握战场主动权, 瞄准作战目的, 确保作战进 程朝着终止态势发展而不“走偏”, 优先完成“观察判断-决策-行动”循环;二是适应性调整方案以应对 战场中的不确定干扰, 确保己方作战过程持续进行 而不会“中断”, 具有较强的学习能力和泛化性. 为此, 策略学习应具有记忆功能, 以判断什么样的行动产 生了好的效果、什么样的策略更具有获胜的可能性. 正如 AlphaStar 使用长短时记忆网络捕捉历史信息, 构建虚拟竞技场保持策略稳定, 并采用持续强化学 习实现策略不断更新进化.
3.2 智能博弈应用展望
3.2.1 基于知识规则的智能技术
知识来源于实践, 人类在解决问题时更倾向于 遵循成熟规则. 机器还难以模仿人类大脑的复杂学 习能力, 智能博弈水平需要漫长的成长过程. 传统基 于知识的专家系统, 利用人类经验和专家知识, 便可 解决各领域复杂问题. 在深度学习盛行之后, 基于知 识规则的智能技术依旧取得了不凡成绩. 例如, 东京 大学日麻 AI 系统利用 9.6 万多条规则进行监督学习, 达到了专业六段水平;韩国三星的 SAIDA 系统完全 凭借职业玩家总结的规则知识, 在 2018 年 IEEE 举 办的星际争霸比赛中获得第一. 即便是融合了深层 神经网络的 AlphaGo 和 AlphaStar, 依然需要在预训 练中使用大量人类对局数据进行模仿学习. 虽然 AlphaZero 和 Muzero 能够完全通过自主学 习实现成长[25] , 但围棋游戏与战争对抗存在天壤之 别, 难以直接应用于军事领域. 强化学习算法还难以 实现从基本策略中总结出高层策略, 现有的条令条 例、规划流程、作战规则等大量知识可转化为知识 网络以引导 AI 系统决策.
3.2.2 人机融合实现决策智能
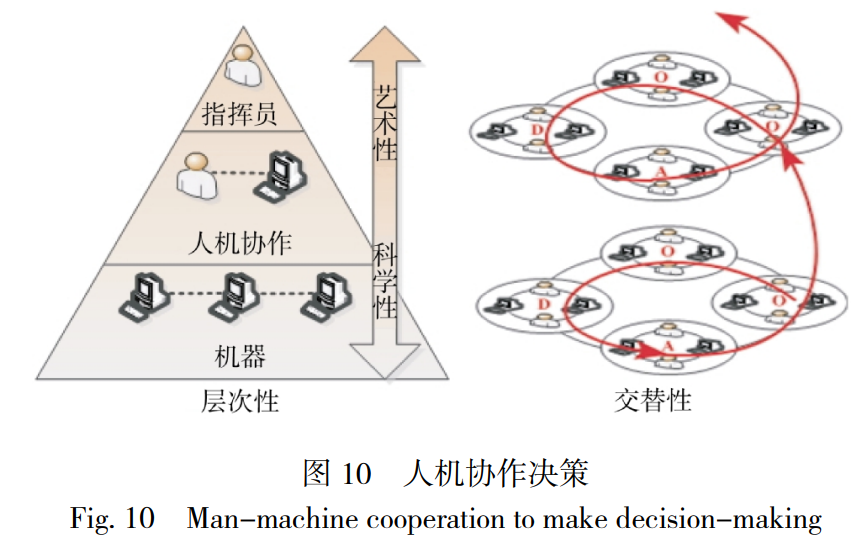
战争的非透明性和不确定性, 使得作战筹划及 指挥控制过程极其复杂, 单纯依靠人类大脑难以满 足决策速度和精度要求, 而完全依赖机器又难以满 足决策的可解释性. 人机融合决策具有两个明显特 性, 如图 10 所示. 一是层次性, 指挥决策具有科学性 和艺术性, 科学性随指挥层次提升而降低, 艺术性与 之相反. 低层级指挥决策可采用传统运筹学、贝叶斯 网络、机器学习等科学方法, 这是实现决策智能的基 础;中间层级指挥决策采用不同程度的人机协作决 策, 重点研究人机协作的时机、场合和方式等;而高 层级指挥决策需要由指挥员及参谋机构拟制. 二是 交替性, 传统的 OODA 环已转化为具有学习机制的 OODA 螺旋[11] , 指挥决策成为一个滚动迭代、不断优 化的过程. 人与机器在各环节都有擅长与不足之处, 例如:态势理解环节, 机器善于处理海量数据、提取 态势特征和简单战斗战术级态势理解, 人来负责复 杂战术战役级态势理解及意图判断;行动决策环节, 机器善于快速运筹计算和基于数据挖掘关联关系, 人来负责基于因果关系进行非即时反馈决策. 在 OODA 循环中, 人与机器交替进行智能决策, 并推进 其螺旋上升.
3.2.3 混合技术突破军事智能瓶颈
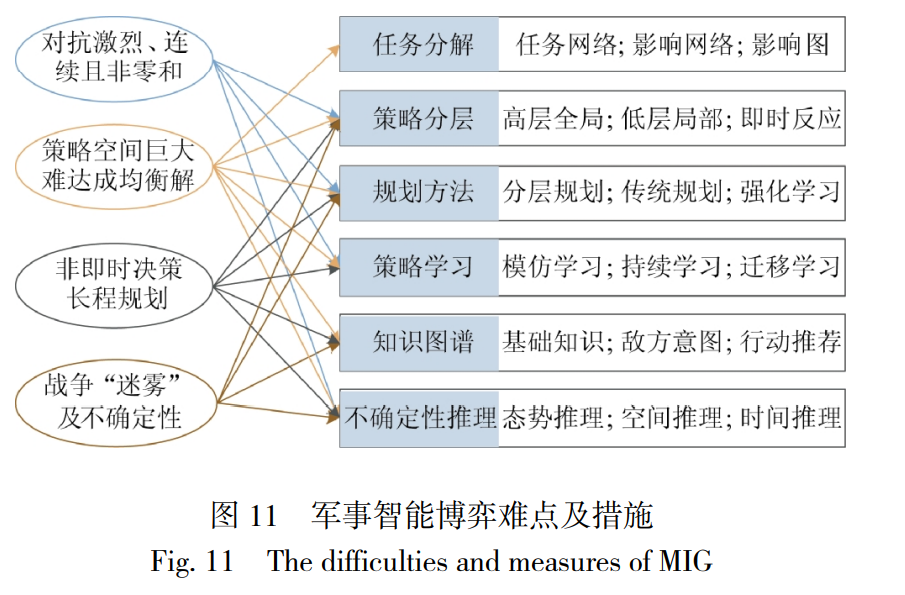
军事博弈的复杂性决定了需要依靠多种技术手 段, AlphaStar 结合了神经网络、多智能体、强化学 习、模仿学习、联盟机制以及各种网络结构和参数 的巧妙设计, 才实现了最终效果. ONTANON 等总结 了多智能体 RTS 游戏的难点及应对措施[26] , 为军事 智能博弈研究发展提供了很好借鉴. 如图 11 所示, 军事智能博弈需重点关注以下几点: 1)任务分解. 采用分层任务网络、影响网络和 影响图等技术, 将战役任务按时间、因果和逻辑等关 系进行分解, 降低整体求解难度. 2)策略分层. 模拟人类思维流程进行分层决策 和多尺度规划, 上层策略为下层规划目标, 而下层策 略的执行支撑了上层策略, 如高层策略关注战役全 局问题、底层策略聚焦短期利益、即时策略控制反 应式动作. 3)规划方法. 灵活运用多种规划方法:低层次局 部任务规划与高层次全局作战规划的一致性耦合;复 杂多目标问题求解的优化与效率的均衡;在理论和技 术条件下, 若能基于知识规则进行规划, 则应避免使 用强化学习. 4)策略学习. 一是基于历史或仿真数据的策略 模仿学习, 解决复杂问题从零学习的困境;二是基于 联盟机制的策略持续学习, 解决策略持续优化、避免 陷入死循环的困境;三是基于通用 AI 技术的策略迁 移学习, 解决知识经验和学习机制在不同场景下的 共享问题. 5)不确定性推理. 针对战场信息不完全性增加 侦察策略, 构建预测模型对战场态势、敌方意图及行 动策略进行推理;针对广阔战场空间和作战单位功能 各异, 需要合理安排力量跨域作战、资源空间转移和 行动空间协同等问题, 进行空间不确定性推理;针对 战争非即时反馈特点, 既需要解决当前危机, 又要长 远地规划资源利用和策略转换等问题, 进行时间不 确定推理. 6)知识图谱. 以图谱形式组织军事领域知识, 构 建基础知识图谱;基于历史数据及专家经验, 构建敌 方意图图谱;针对不同决策场景, 结合指挥员经验总 结, 构建我方行动推荐图谱.
**3.2.4 对抗博弈用于强化训练和战法研究 **
战争谋略是长期作战实践的经验总结. 通过对 抗博弈, 机器学习人类已有经验知识, 人类从机器行 为表现中得到启发, 实现人类决策能力与机器智能 水平的共同提升. 以战役级计算机兵棋系统为训练 平台, 基于敌军战法规则构建智能对手, 通过人机博 弈对抗进行战法研究和方案检验, 持续提升指挥员 的决策能力和战场大局观. 借鉴 AlphaStar 的虚拟竞 技场思路, 通过机器自博弈探索不同行动方案并进 行评估, 从而克服指挥员传统思维禁锢, 寻找好招、 奇招与妙招. 面向未来无人作战领域, 大力发展多智 能体博弈策略生成的关键技术[27] .
4 结论
通过梳理经典智能博弈理论方法和军事博弈特 征, 得出以下结论:1)军事博弈与游戏存在显著区 别, 战争注重指挥艺术性和决策科学性的结合, 强调 战争设计和“运筹帷幄”;2)军事博弈更加强调面向 战役使命进行长远规划, 而非游戏的反应式规划, 必 须兼顾宏观策略规划和微观战术选择;3)军事博弈 问题规模远远大于游戏场景, 种种不确定性因素和 动态连续的激烈对抗, 增大了均衡策略的求解难度. 因此, 智能博弈相关技术方法还难以完全用于解决 战争问题. 面对复杂的战争系统, 长期积累的军事知 识和作战经验能够引导机器减少盲目搜索, 并避免 犯下违背军事常识的错误;人机交互式决策在保证速 度和精度的同时, 还可通过“人在回路”提高决策的 适应性;如何利用已有技术手段解决现有复杂问题, 聚焦于智能技术混合使用方式, 是亟需研究的内容.




