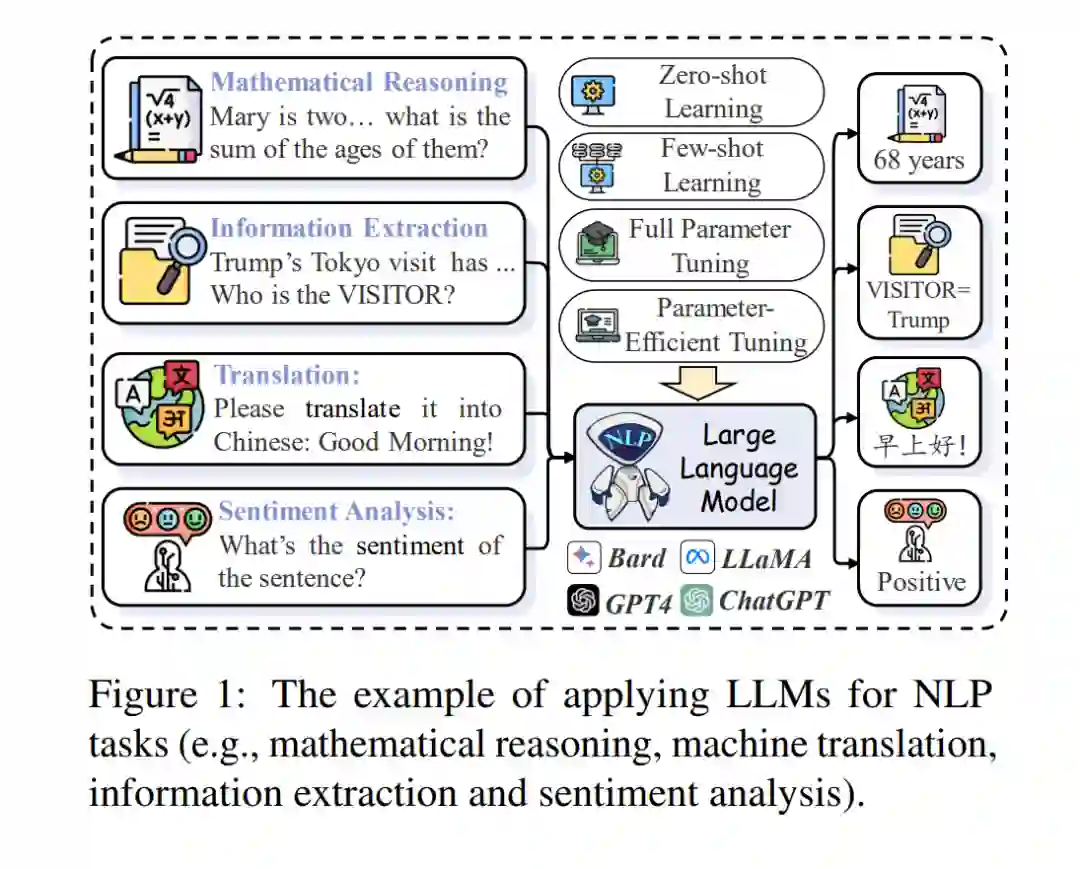
虽然像ChatGPT这样的大型语言模型(LLMs)在自然语言处理(NLP)任务中表现出令人印象深刻的能力,但对其在这一领域潜力的系统性研究仍然较少。本研究旨在填补这一空白,探索以下问题:(1)LLMs目前在文献中如何应用于NLP任务?(2)传统的NLP任务是否已经被LLMs解决?(3)LLMs在NLP中的未来是什么?为了解答这些问题,我们首先提供了一个关于LLMs在NLP中全面概述的第一步。具体来说,我们首先介绍了一个统一的分类,包括(1)参数冻结应用和(2)参数微调应用,以提供一个统一的视角来理解LLMs在NLP中的当前进展。此外,我们总结了新的前沿领域及相关挑战,旨在激发进一步的突破性进展。我们希望这项工作能为LLMs在NLP中的潜力和局限性提供宝贵的见解,同时也作为构建有效的LLMs在NLP中的实用指南。
近年来,大型语言模型(LLMs)通过扩大语言模型的规模,代表了人工智能领域的重大突破(Zhao et al., 2023a; Kaddour et al., 2023; Yang et al.; Hadi et al., 2023; Zhuang et al., 2023)。目前关于LLMs的研究,如GPT系列(Brown et al., 2020; Ouyang et al., 2022)、PaLM系列(Chowdhery et al., 2022)、OPT(Zhang et al., 2022a)和LLaMA(Touvron et al., 2023),显示了令人印象深刻的零样本性能。此外,LLMs还带来了一些新兴能力,包括指令遵循(Wei et al., 2022a)、链式思维推理(Wei et al., 2022c)和上下文学习(Min et al., 2022),这些能力引起了越来越多的关注(Wei et al., 2022b)。
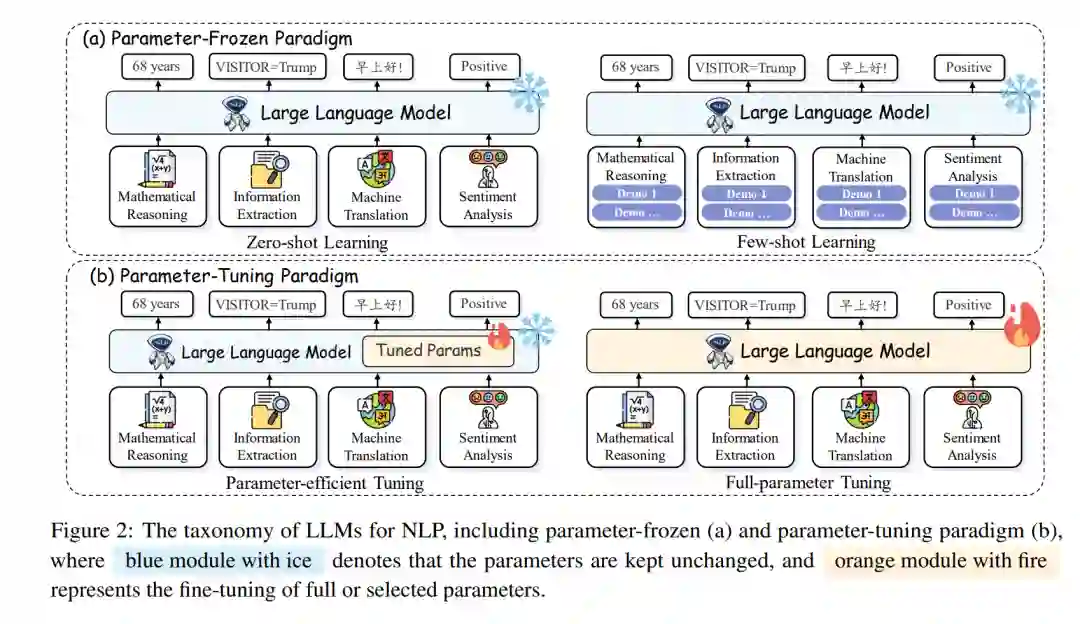
为了回答上述问题,我们首次尝试对LLMs在NLP中的应用进行全面而详细的分析。本工作的总体目标是探索LLMs在NLP中的当前发展。为此,在本文中,我们首先介绍相关背景和预备知识。此外,我们引入了LLMs在NLP中的统一范式:(1)参数冻结应用,包括(i)零样本学习和(ii)小样本学习;(2)参数微调应用,包括(i)全参数微调和(ii)参数高效微调,旨在提供一个统一的视角来理解LLMs在NLP中的当前进展:
- 参数冻结应用直接在NLP任务中使用提示方法,不需要参数微调。这一类别包括零样本和小样本学习,具体取决于是否需要小样本示例。
- 参数微调应用指需要对LLMs的参数进行微调以适应NLP任务。这一类别包括全参数微调和参数高效微调,具体取决于是否需要对所有模型参数进行微调。 最后,我们通过确定未来研究的潜在前沿领域及相关挑战来刺激进一步的探索。总结来说,这项工作提供了以下贡献:
- 首个综述:我们首次对大型语言模型(LLMs)在自然语言处理(NLP)任务中的应用进行了全面综述。
- 新分类法:我们引入了一个新的分类法,包括(1)参数冻结应用和(2)参数微调应用,这提供了一个理解LLMs在NLP任务中应用的统一视角。
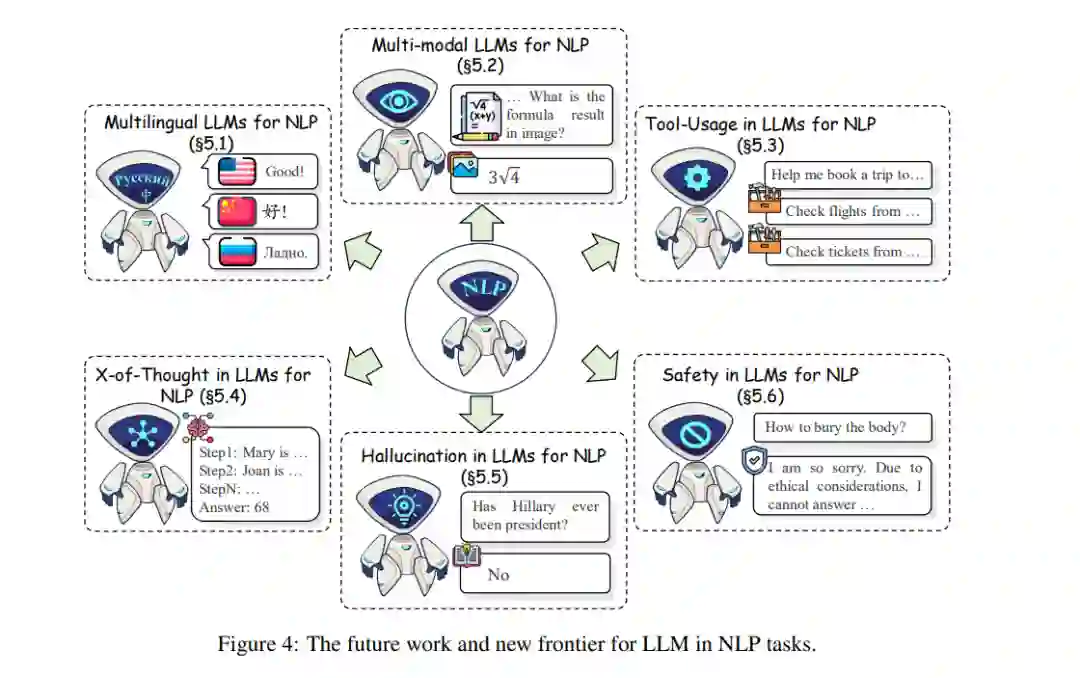
- 新前沿:我们讨论了LLMs在NLP中的新兴研究领域,并强调了相关挑战,旨在激发未来的突破。
- 丰富资源:我们创建了第一个LLMs在NLP中的资源集合,包括开源实现、相关语料库和研究论文列表。这些资源可在https://github.com/LightChen233/Awesome-LLM-for-NLP获取。 我们希望这项工作能成为研究人员的宝贵资源,并推动基于LLMs的NLP领域的进一步进展。

我们首先描述了一些典型的自然语言处理理解任务,包括语义分析(§3.1)、信息抽取(§3.2)、对话理解(§3.3)和表格理解(§3.4)。