

近期的人工智能(AI)系统在各种“大挑战”中达成了里程碑式的成果,范围从围棋到蛋白质折叠。具备获取医学知识、进行推理并能够与医生相媲美地回答医学问题的能力,长久以来被视为其中一个重大挑战。大型语言模型(LLM)在医学问题回答方面催生了显著的进步;MedPaLM是第一个在USMLE(美国医师执照考试)风格的问题上获得“及格”分数的模型,该模型在MedQA数据集上的得分为67.2%。然而,这项以及其他先前的工作表明,特别是在模型的答案与临床医生的答案相比时,还有相当大的提升空间。在此我们提出了Med-PaLM 2,该模型通过利用基础LLM的改进(PaLM 2)、医学领域的微调,以及包括一种新型的集成精炼方法在内的提示策略,来填补这些差距。Med-PaLM 2在MedQA数据集上的得分高达86.5%,比Med-PaLM提高了19%以上,刷新了最新的技术水平。我们还观察到其在MedMCQA、PubMedQA以及MMLU临床话题数据集中的表现接近或超过了最新的技术水平。我们对长篇问题进行了详细的人类评估,评估的多个维度都与临床应用相关。在对1066个消费者医疗问题的两两比较排名中,医生在九个与临床效用相关的评估维度中有八个更喜欢Med-PaLM 2的答案(p < 0.001)。我们也在新引入的用于探测LLM限制的240个长篇“对抗性”问题的数据集上,观察到与Med-PaLM相比,每一个评估维度都有显著的改进(p < 0.001)。尽管需要进行更多的研究来验证这些模型在实际环境中的有效性,但这些结果强调了在医学问题回答方面,我们正在迅速朝向医生级别的表现迈进。
https://www.zhuanzhi.ai/paper/e481cd1aa3ebd8aa84e958c97e905f12
1. 引言
语言是健康和医疗的核心,支撑着人们与护理提供者之间的互动。大型语言模型(LLMs)的进步使得我们能够在人工智能(AI)系统中探索医学领域的能力,这些系统能够理解并使用语言进行交流,这预示着更丰富的人机交互和协作。特别是,这些模型在多选研究基准测试[1-3]上展示了令人印象深刻的能力。
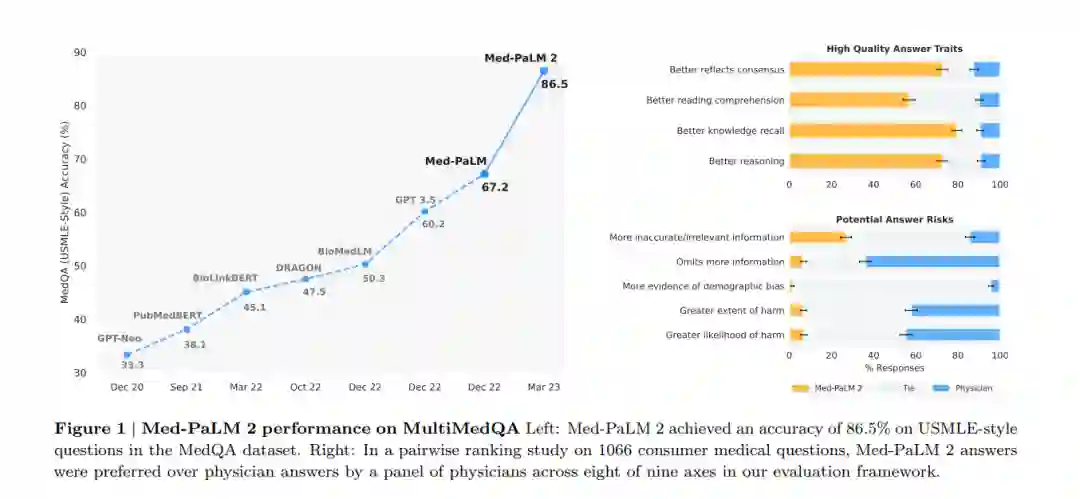
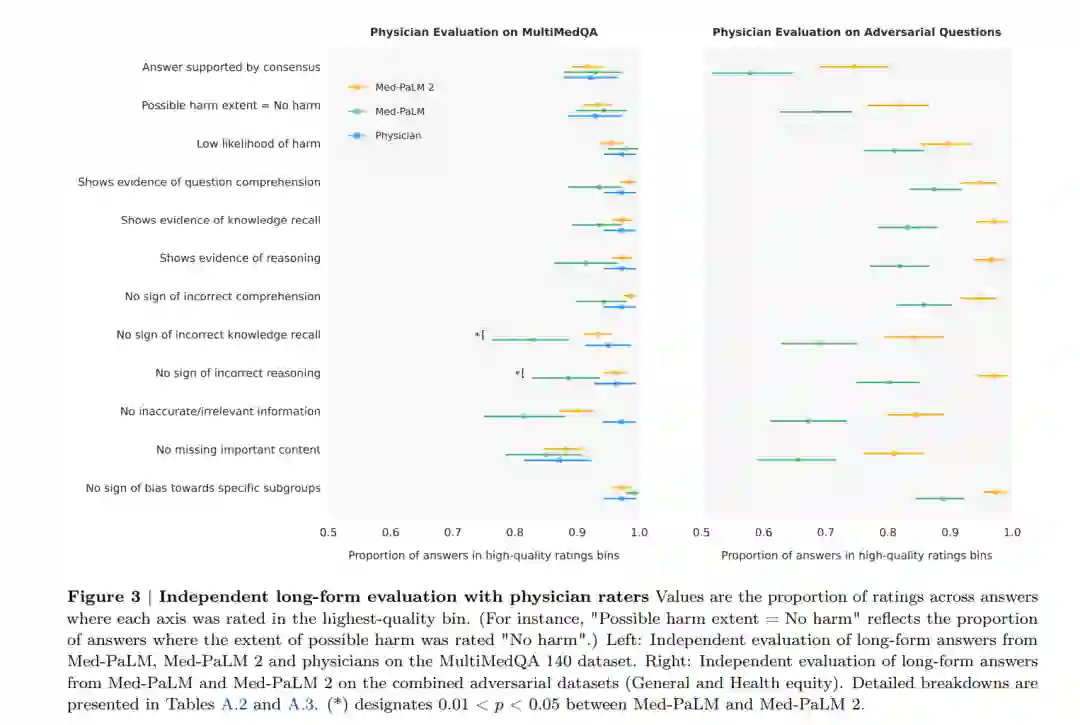
在我们之前关于Med-PaLM的工作中,我们展示了全面的医学问题回答基准测试、模型答案的人类评估以及医学领域的对齐策略的重要性[1]。我们引入了MultiMedQA,一个覆盖医学考试、消费者健康和医学研究的多元化医学问题回答基准测试。我们提出了一个人类评估量表,使医生和普通人能够进行模型答案的详细评估。我们的初始模型Flan-PaLM,是第一个在包含美国医生执照考试(USMLE)风格问题的MedQA数据集上超过常引用的及格分数的模型。然而,人类评估揭示,我们需要进一步努力,以确保AI输出,包括对开放性问题的长篇回答,是安全的,并符合这个关乎安全的领域中的人类价值观和期望(这个过程通常被称为“对齐”)。为了填补这一差距,我们利用指示提示调优开发了Med-PaLM,大大提高了医生对Flan-PaLM的评估。然而,与医生相比,模型答案的质量仍存在关键的不足。同样,虽然Med-PaLM在MultiMedQA中每一个多项选择基准测试上都达到了最新技术水平,但这些分数还有提升的空间。 在这里,我们通过Med-PaLM 2弥补了这些差距,并进一步推进了医学领域中LLM的能力。我们使用改进的基础LLM(PaLM 2 [4])、医学领域特定的微调以及一种新的提示策略来开发这个模型,这使得医学推理能力得到了提升。如图1(左)所示,Med-PaLM 2在MedQA上比Med-PaLM提高了19%以上。该模型也接近或超过了在MedMCQA、PubMedQA和MMLU临床话题数据集上的最新技术水平。虽然这些基准测试是衡量LLM编码的知识的有用工具,但它们并不能捕捉到模型生成针对需要微妙答案的问题的真实、安全反应的能力,这在现实世界的医学问题回答中很常见。我们通过应用我们以前发布的医生和普通人评估的量表来研究这一点[1]。此外,我们引入了两个额外的人类评估:首先,对模型和医生回答消费者医疗问题的成对排名评估,沿着九个与临床相关的轴进行;其次,医生对模型在两个新引入的设计用来探测LLM极限的对抗测试数据集上的反应的评估。我们的主要贡献可以总结如下: • 我们开发了Med-PaLM 2,这是一个新的医学LLM,使用新的基础模型(PaLM 2 [4])和针对医学领域的特定微调进行训练(第3.2节)。 • 我们引入了集成精修作为一种新的提示策略,以提高LLM的推理能力(第3.3节)。 • Med-PaLM 2在多个MultiMedQA基准测试上取得了最新技术水平的结果,包括MedQA的USMLE风格问题(第4.1节)。 • 长篇回答消费者医疗问题的人类评估显示,Med-PaLM 2的答案在与临床效用相关的九个轴中的八个轴上,比医生和Med-PaLM的答案更受欢迎,如事实性、医学推理能力和低可能性的伤害。例如,72.9%的时间里,Med-PaLM 2的答案被判断为更好地反映了医学共识(第4.2节和图1)。 最后,我们引入了两个对抗性问题数据集,以探测这些模型的安全性和限制。我们发现,Med-PaLM 2在每个轴上的表现都显著优于Med-PaLM,进一步强调了全面评估的重要性。例如,与Med-PaLM的79.4%相比,有90.6%的Med-PaLM 2的答案被评为具有低伤害风险(第4.2节、图5和表A.3)。
2. 方法
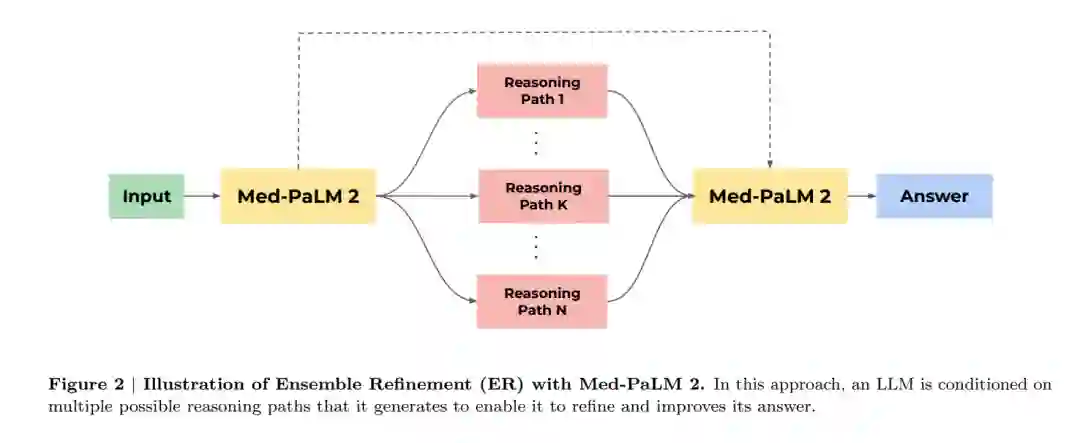
基础LLM 对于Med-PaLM,基础LLM是PaLM[20]。Med-PaLM 2基于PaLM 2[4],这是Google的大型语言模型的新版本,该模型在多个LLM基准任务上有显著的性能提升。 指令微调我们按照Chung等人[21]的协议对基础LLM进行了指令微调。使用的数据集包括MultiMedQA的训练部分,即MedQA、MedMCQA、HealthSearchQA、LiveQA和MedicationQA。我们训练了一个“统一”的模型,该模型在MultiMedQA的所有数据集上都经过优化,使用的数据集混合比率(每个数据集的比例)在表3中报告。这些混合比率和特定数据集的包含是经验性确定的。除非另有说明,Med-PaLM 2指的是这个统一模型。为了比较,我们还创建了一个只对多项选择问题进行微调的Med-PaLM 2变体,这提高了这些基准测试的结果。
3. 结果
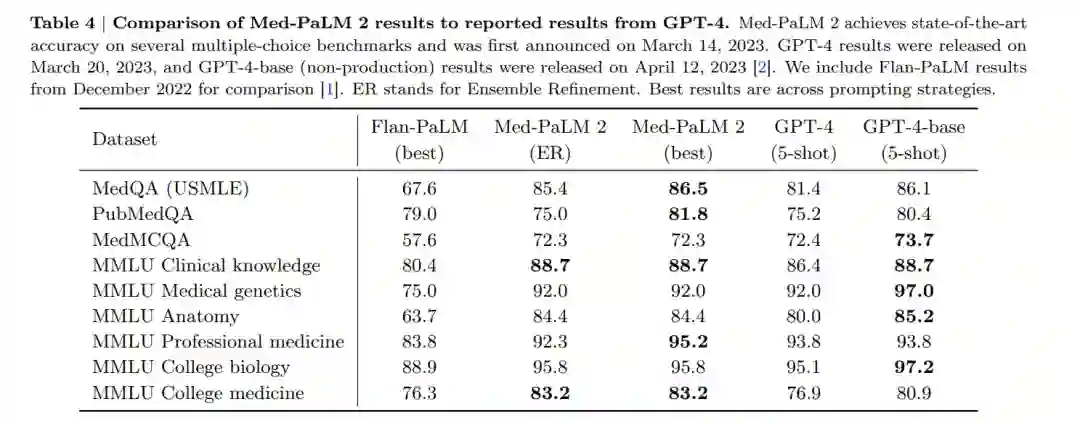
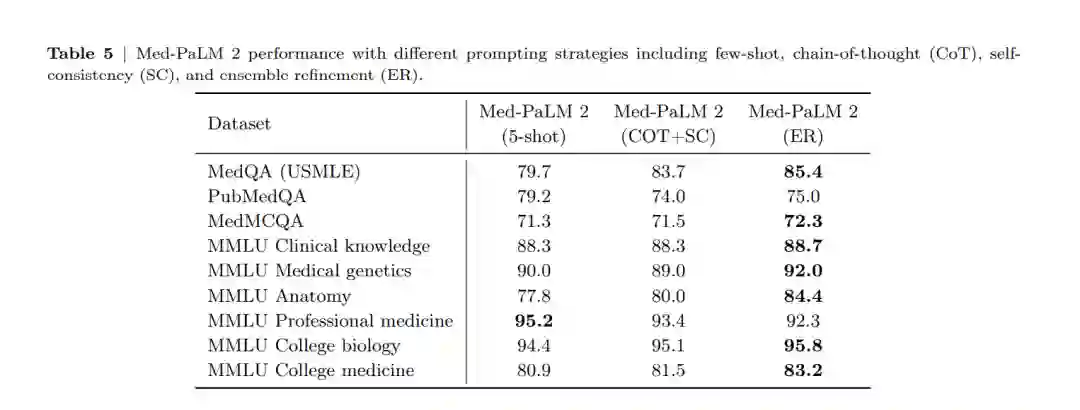
表4和表5总结了Med-PaLM 2在MultiMedQA多项选择基准测试上的结果。除非另有说明,否则Med-PaLM 2指的是在表3中的混合训练的统一模型。我们还包括与GPT-4 [2, 45]的比较。
4. 结论
这些结果展示了LLMs正在迅速向医生级别的医疗问题回答方向发展。然而,随着技术在现实应用中的广泛接纳,还需要进行进一步的验证、安全和伦理方面的工作。我们需要在不同的医疗问题回答和现实工作流程的背景下对LLMs进行仔细且严格的评估和优化,以确保这项技术对医学和健康产生积极的影响

