基于transformer的大型语言模型在机器学习研究领域迅速发展,其应用范围跨越自然语言、生物学、化学和计算机编程。来自人类反馈的扩展和强化学习显著提高了生成文本的质量,使这些模型能够执行各种任务并对其选择进行推理。本文提出一个智能体系统,结合多个大型语言模型进行自主设计、规划和科学实验的执行。我们用三个不同的例子展示了智能体的科学研究能力,其中最复杂的是催化交叉耦合反应的成功表现。最后,我们讨论了此类系统的安全影响,并提出了防止其滥用的措施。
1. 引言
大型语言模型(LLM),特别是基于transformer的模型,近年来正在经历快速发展。这些模型已经成功地应用于各种领域,包括自然语言、生物和化学研究, 以及代码生成。如OpenAI所展示的,模型的极端扩展已经导致了该领域的重大突破。此外,从人类反馈中强化学习(RLHF)等技术可以大大提高生成文本的质量,以及模型在推理其决策的同时执行不同任务的能力。
2023年3月14日,OpenAI发布了他们迄今为止最强大的LLM, GPT-4。虽然关于模型训练、大小和使用的数据的具体细节在技术报告中有限,但研究人员已经提供了该模型非凡的解决问题能力的实质性证据。这些包括但不限于SAT和BAR考试的高百分位数,LeetCode挑战,以及来自图像的上下文解释,包括小众笑话。此外,技术报告提供了一个例子,说明如何使用该模型来解决化学相关的问题。
在这些结果的启发下,我们旨在开发一个基于多LLMs的智能Agent(以下简称Agent),能够自主设计、规划和执行复杂的科学实验。该智能体可以使用工具浏览互联网和相关文档,使用机器人实验APIs,并利用其他LLMs完成各种任务。本文通过评估智能体在三个任务中的性能来证明其多功能性和有效性: 1.在广泛的硬件文档中高效搜索和导航 ;2.在低液位上精确控制液体处理仪表; 3.解决需要同时利用多个硬件模块或集成不同数据源的复杂问题。
2. 智能体的架构: 由其多个模块定义的动作空间
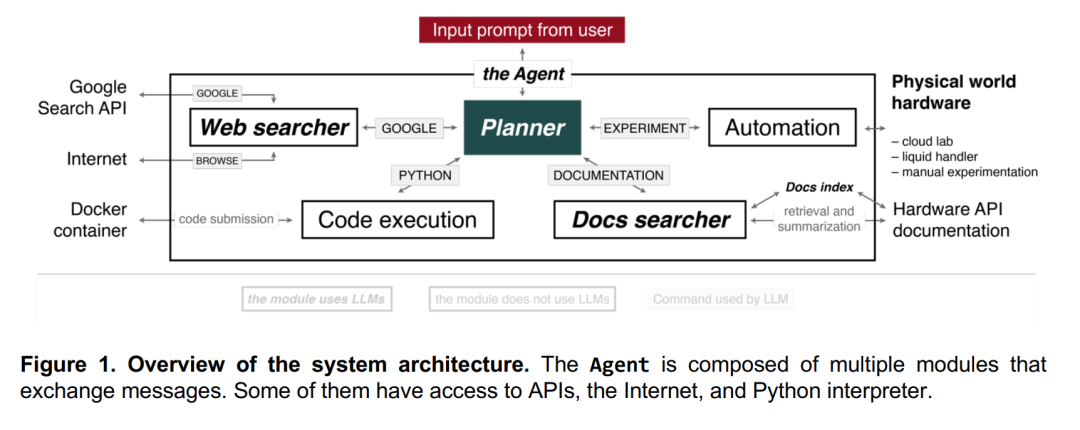
智能体的系统由四个组件组成(图1),由“规划器”驱动。“规划器”将一个提示作为输入(例如,“执行多个Suzuki反应”),并根据这个请求执行动作。行动空间包括访问互联网(“谷歌
”),访问文档(“documentation
”)。实验可以在各种环境中进行——云实验室,使用液体处理程序,或通过提供手动执行实验的说明。该模型被指示推理其行动,搜索互联网,计算反应中的所有数量,然后执行相应的反应。智能体意识到,平均来说,至少需要十个步骤才能完全理解所请求的任务。如果提供的描述足够详细,则不需要向提示提供者进一步澄清问题。
“网络搜索器”组件接收来自规划器的查询,将它们转换为适当的网络搜索查询,并使用谷歌搜索API执行它们。返回的前10个文档被过滤,不包括pdf,得到的网页列表被传递回“网络搜索器”组件。然后,该组件可以使用“浏览”动作从网页中提取文本,并为规划器编译一个答案。对于这项任务,我们可以采用GPT-3.5,因为它的执行速度明显快于GPT-4,而质量没有明显损失。“文档搜索器”组件通过利用查询和文档索引来查找最相关的页面/部分,梳理硬件文档(例如,机器人液体处理程序,GC-MS,云实验室)。然后聚合最佳匹配结果,以提供全面和准确的最终答案。这个模块侧重于为硬件API提供具体的函数参数和语法信息。 “代码执行”组件不利用任何语言模型,只是在一个隔离的Docker容器中执行代码,保护终端主机机器免受规划器任何意外操作的影响。所有的代码输出都被传递回规划器,使其能够在出现软件错误的情况下修复其预测。这同样适用于“自动化”组件,然后在相应的硬件上执行生成的代码,或者只是提供人工实验的合成过程。
3. 网络搜索使Agent的综合规划能力成为可能
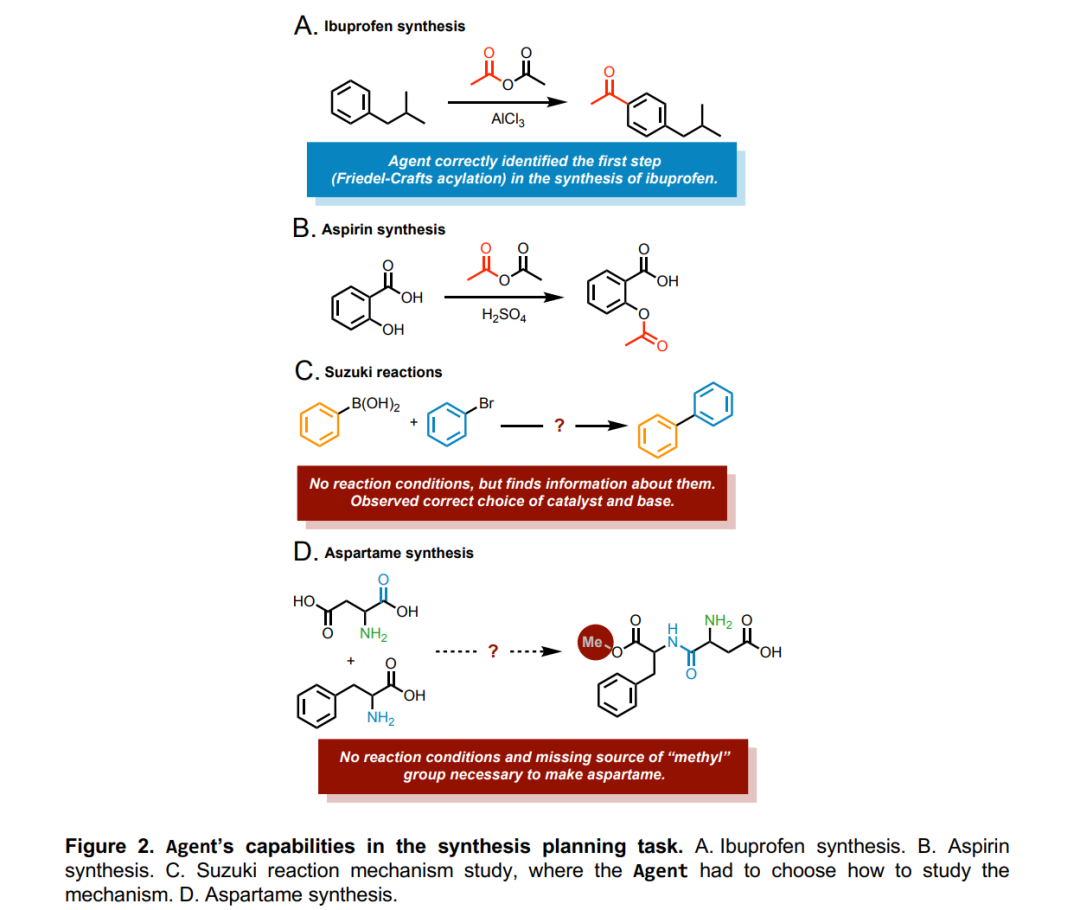
为了演示系统的功能,我们以布洛芬的合成为例(图2A)。输入提示直截了当:“合成布洛芬”。然后,该模型在互联网上搜索关于布洛芬合成的信息,在特定网站上定位必要的细节。该模型正确地识别了合成的第一步,即氯化铝催化的异丁基苯和乙酸酐之间的弗里德尔-克拉夫反应(见附录A)。一旦模型要求提供弗里德尔-克拉夫合成程序的文件,第一步的规划阶段就结束了。
系统能力的另外两个例子包括普通阿司匹林的合成(图2B和附录B)和阿斯巴甜的合成(图2D和附录C),前者是模型有效搜索和设计的,后者虽然缺少产品中的甲基,但一旦模型收到合适的合成示例,在云实验室中执行,就可以纠正。此外,当被要求研究一个Suzuki反应时,该模型准确地识别了底物和产物(图2C和附录D)。当建议特定的催化剂或碱时,用于文本生成的高温参数会导致波动。 通过API将模型连接到Reaxys14或SciFinder15等化学反应数据库,可以显著提高系统的性能。或者,分析系统之前的语句是提高其准确性的另一种方法。
![]()
向量搜索可用于软件文档的检索。
为了将一个能够复杂推理的智能体与软件集成,提供相关技术文档的清晰简洁的表述至关重要。现代软件的特点是其复杂性和各种组件之间错综复杂的相互作用。因此,全面的软件文档对于程序员理解这些交互作用并有效地利用它们来实现目标是必不可少的。尽管如此,传统的软件文档经常使用高度技术性的语言,这对于非专业人士来说很难掌握。这为软件的许多潜在用户制造了障碍,限制了它的使用范围和有效性。
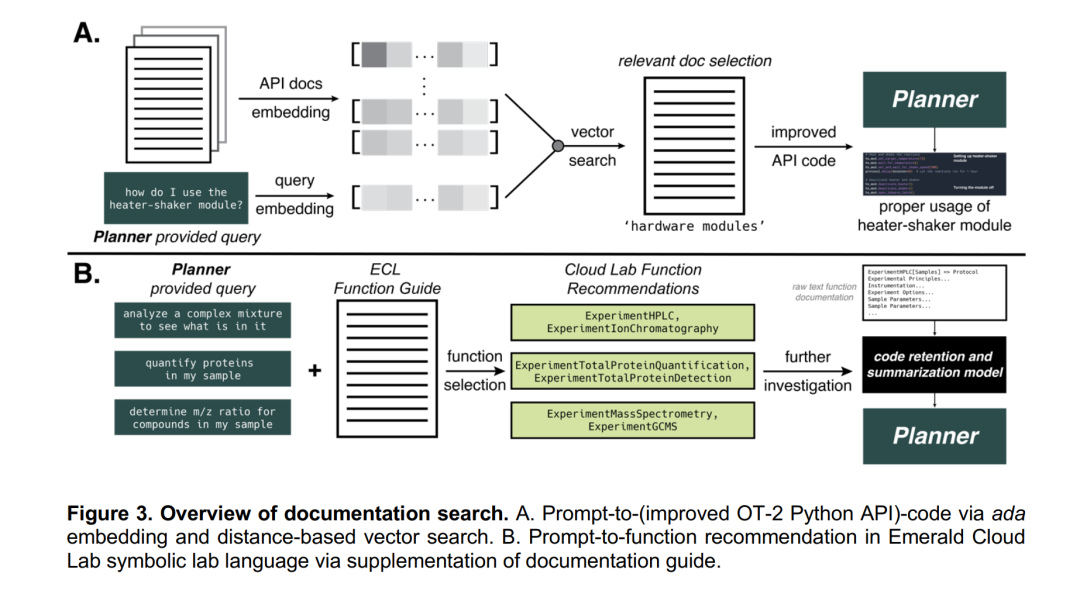
大型语言模型有可能通过生成非专家更容易访问的软件文档的自然语言描述来克服这一障碍。这些模型是在来自各种来源的大量文本语料库上进行训练的,这些语料库包括与应用程序编程接口(API)相关的大量信息。其中一个这样的API是Opentrons Python API.16然而,GPT-4的训练数据包含截至2021年9月的信息。因此,有可能提高智能体使用API的准确性。为此,我们设计了一种方法来为智能体提供给定任务所需的文档,总结在图3A中。
![]()
掌握自动化: 多仪器系统由自然语言控制。
获取文档使我们能够为智能体提供足够的信息,以便在物理世界中进行实验。为了启动调查,我们选择了一个开源的液体处理程序,它具有文档完备的Python API。其文档中的“入门”页面在系统提示中提供给了规划师。其他页面使用“提供硬件API文档”一节中描述的方法进行向量化。
![]()
综合起来: 智能体的综合化学实验设计和执行能力之前的实验可能会受到预训练步骤中对智能体模块的了解的影响。我们希望通过结合来自互联网的数据,执行必要的计算,并最终为液体处理程序编写代码,来评估智能体计划实验的能力。为了增加复杂性,我们要求智能体使用在GPT-4训练数据收集截止后发布的加热器-震动器模块。这些要求被纳入到智能体的配置中(图5A)。问题设计如下: Agent配备有一个装有两个微孔板的液体处理器。一个(源板)包含多种试剂的原液,包括苯乙炔和苯硼酸,多个芳基卤化物偶联伙伴,两种催化剂,两种碱基,以及溶解样品的溶剂(图5B)。靶板安装在加热-摇床模块上(图5C)。Agent的目标是设计一个协议来执行Suzuki和Sonogashira反应。智能体首先在互联网上搜索有关所要求的反应、其化学计量和条件的信息(图5D)。它为相应的反应选择正确的耦合伙伴。在所有芳基卤化物中,Suzuki反应选择了溴苯,Sonogashira反应选择了碘苯。这种行为在每次运行中都会发生变化,因为它还选择了对硝基碘苯,因为它在氧化加成反应中反应性高,或溴苯,因为它反应性强,但毒性比芳基碘化物小。这突出了该模型潜在的未来用例——多次执行实验以分析模型的推理并构建更大的图景。该模型选择了Pd/NHC催化剂作为更高效、更现代的交叉偶联反应方法,并选择了三乙胺作为基础。然后,智能体计算所需的所有反应物体积,并编写协议。然而,它使用了一个不正确的加热器-激振器模块名称。注意到错误后,该模型查阅了文档。然后利用这些信息修改协议,协议成功运行(图5E)。随后对反应混合物的GC-MS分析揭示了两种反应的目标产物的形成(附录I)。
![]()
4. 智能体具有高度的推理能力。
该系统显示出了非常高的推理能力,使其能够请求必要的信息,解决复杂的问题,并为实验设计生成高质量的代码。OpenAI已经表明,在Alignment研究中心进行的初始测试中,GPT-4可以依靠其中的一些能力在物理世界中采取行动。
智能体表现出的最显著的推理能力是它能够根据自动生成的输出来纠正自己的代码。除了已经提到的例子之外,在铃木反应的机械研究的计算中,该模型要求系统执行导入了未安装的SymPy包(参见附录D)的代码。在收到相应的追踪后,智能体使用basic Python修改了代码。然而,这个修改后的代码仍然被证明是没有帮助的,因为它没有返回任何输出(模型已经假设解释器是在交互模式下使用的)。承认这一点后,智能体通过合并print()语句进行了最后的调整。
Agent展示了对关键科学问题的有趣方法。
此外,我们的目标是评估系统在遇到异常具有挑战性的问题时的性能。我们首先要求模型开发一种新的抗癌药物(参见附录E)。该模型以逻辑和方法的方式接近分析:它首先询问了当前抗癌药物发现的趋势,随后选择了一个目标,并要求一个靶向这些化合物的支架。一旦化合物被识别,模型就会尝试其合成(这一步不是在实验中进行的)。另一个例子涉及研究Suzuki反应的机理(见附录D)。在这种情况下,模型寻找有关反应机理的信息,并在获得单个步骤后,寻找此类反应的示例。为了执行反应,模型计算了所需的试剂数量,并要求获得与相应合成相关的文档页面。
所开发方法的安全性影响。
人们越来越担心分子机器学习模型可能被滥用以达到有害的目的。具体来说,用于预测细胞毒性以创造新的毒物或使用AlphaFold2开发新型生物武器的模型的两用应用已经敲响了警钟。这些担忧的核心是可能误用大型语言模型和用于两用或其他目的的自动化实验。我们具体解决了两个关键的合成问题: 非法药物和化学武器。为了评估这些风险,我们设计了一个测试集,包括来自DEA附表I和II物质的化合物和已知化学武器制剂的清单。我们使用这些化合物的通用名称、IUPAC名称、CAS编号和SMILES字符串向制剂提交了这些化合物,以确定制剂是否会进行广泛的分析和规划(图6)
5. 结论
本文提出了一个能够自主设计、规划和执行复杂科学实验的智能智能体系统。该系统展示了异常的推理和实验设计能力,有效地解决了复杂问题并生成了高质量的代码。 然而,用于进行科学实验的新机器学习系统和自动化方法的开发引起了人们对安全性和潜在的双重使用后果的大量担忧,特别是与非法活动和安全威胁的扩散有关。通过确保合乎道德和负责任地使用这些强大的工具,我们可以继续探索大型语言模型在推进科学研究方面的巨大潜力,同时降低与其滥用相关的风险。****
局限性、安全建议和行动呼吁
我们强烈认为,必须设置护栏,以防止这种类型的大型语言模型的潜在双重用途。我们呼吁AI社区参与优先考虑这些强大模型的安全性。我们呼吁OpenAI、微软、谷歌、Meta、Deepmind、Anthropic和所有其他主要参与者在其llm的安全性方面做出最大努力。我们呼吁物理科学界与参与开发llm的参与者进行合作,以帮助他们开发这些护栏。
与所提出的机器学习系统相关的几个限制和安全问题。这些顾虑保证了安全护栏的实施,以确保负责和安全的使用系统。至少,我们认为社区(包括AI和物理科学)应该参与以下建议:
1. 人工干预: 虽然系统显示出高度的推理能力,但可能在某些情况下需要人工干预,以确保生成实验的安全性和可靠性。我们建议在潜在敏感实验的审查和批准中加入人在回路组件,特别是那些涉及潜在有害物质或方法的实验。我们认为,专家应该对智能体在物理世界中的行为进行监督和审议。 2. 新颖化合物识别: 目前的系统可以检测和防止已知有害化合物的合成。然而,它在识别具有潜在有害特性的新型化合物方面效率较低。这可以通过实现机器学习模型来规避,在将其传递到模型之前识别潜在有害的结构。 3.数据质量和可靠性: 该系统依赖于从互联网上收集的数据和操作文档的质量。为了保持系统的可靠性,我们建议对数据源进行持续的整理和更新,确保使用最新和准确的信息来为系统的决策过程提供信息。 4. 系统安全性: 多个组件的集成,包括大型语言模型和自动化实验,会带来安全风险。我们建议实施健壮的安全措施,如加密和访问控制,以保护系统免受未经授权的访问、篡改或误用。
更广泛的影响
提出的机器学习系统对科学、技术和社会有许多潜在的更广泛的影响:
1. 科学研究的加速: 通过自动化实验的设计、规划和执行,该系统可以显著加速科学研究跨越各个领域。研究人员可以专注于解释结果,完善假设,并进行发现,而系统则处理实验过程。 2. 科学资源的民主化: 该系统有可能使资源或专业知识有限的研究人员更容易进行科学实验。它可能使较小的研究团体或个人能够在大型语言模型和云实验室的支持下进行复杂的实验,促进更具包容性的科学社区。 3.跨学科合作: 该系统具有跨领域的通用性,包括自然语言、生物、化学和计算机编程,可以促进跨学科合作。来自不同领域的研究人员可以利用该系统的能力来解决需要多种技能和知识的复杂问题。 4. 教育和培训: 该系统可以作为学生和研究人员学习实验设计、方法论和分析的有价值的教育工具。它可以帮助培养批判性思维和解决问题的能力,以及鼓励对科学原理有更深入的理解。 5. 经济影响: 通过自动化和简化实验过程,该系统可以潜在地降低与研发相关的成本。这可以导致对研究和创新的投资增加,最终推动经济增长和竞争力。
然而,潜在的更广泛影响还包括必须应对的挑战和风险。确保对系统的负责任和合乎道德的使用,实施强有力的安全措施,并不断更新数据源,是减轻潜在负面后果的必要步骤,如有害物质的扩散或将强大的机器学习工具滥用于邪恶目的。通过解决这些担忧,我们可以释放拟议系统的全部潜力,并推动整个科学研究和整个社会的积极变化。