

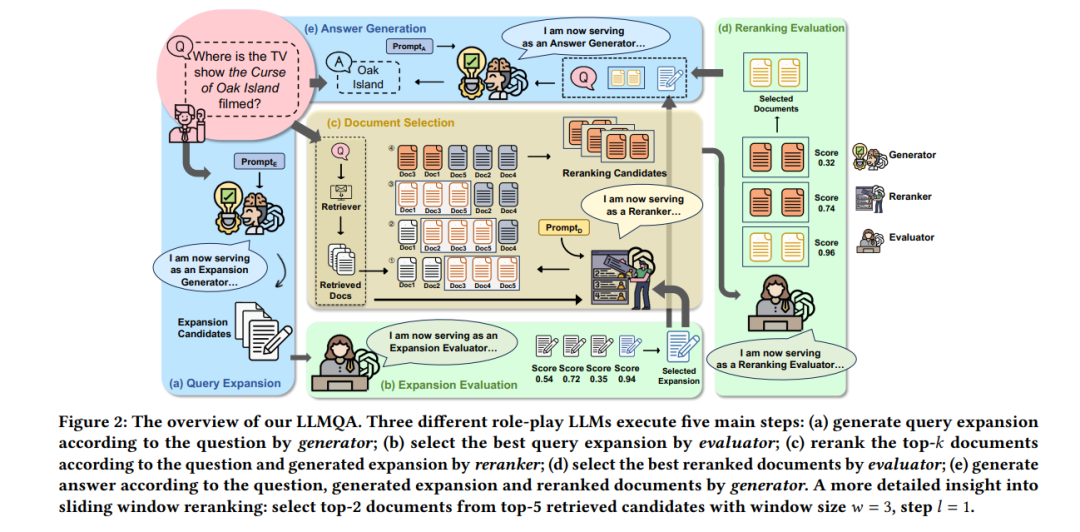
开放领域问答(ODQA)已成为信息系统研究的一个关键焦点。现有方法主要遵循两种范式来收集证据:(1)“检索-阅读”范式从外部语料库检索相关文档;(2)“生成-阅读”范式利用大型语言模型(LLMs)生成相关文档。然而,这两种方法都无法完全满足证据的多方面需求。为此,我们提出了LLMQA,一个通用框架,将ODQA过程划分为三个基本步骤:查询扩展、文档选择和答案生成,结合了基于检索和基于生成的证据的优势。由于LLMs展现出在完成各种任务上的出色能力,我们指导LLMs在我们的框架中扮演生成器、重新排序者和评估者等多重角色,将它们整合在ODQA过程中协同工作。此外,我们引入了一种新颖的提示优化算法来细化角色扮演提示,并指导LLMs产生更高质量的证据和答案。在广泛使用的基准测试(NQ, WebQ, 和 TriviaQA)上的大量实验结果表明,LLMQA在答案准确性和证据质量方面都取得了最佳性能,展示了其推进ODQA研究和应用的潜力。
成为VIP会员查看完整内容
相关内容
Arxiv
224+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日