虽然强化学习(RL)在许多领域的连续决策问题上取得了巨大的成功,但它仍然面临着数据效率低下和缺乏可解释性的关键挑战。有趣的是,近年来,许多研究人员利用因果关系文献的见解,提出了大量统一因果关系优点的著作,并很好地解决了RL带来的挑战。因此,整理这些因果强化学习(CRL)著作,回顾CRL方法,研究因果强化学习的潜在功能是非常必要和有意义的。**特别是,我们根据现有CRL方法是否预先给出基于因果关系的信息,将其分为两类。我们从不同模型的形式化方面进一步分析了每个类别,包括马尔可夫决策过程(MDP)、部分观察马尔可夫决策过程(POMDP)、多臂赌博机(MAB)和动态处理制度(DTR)。**此外,我们总结了评估矩阵和开源,同时我们讨论了新兴的应用程序。
https://www.zhuanzhi.ai/paper/2831beac5d3d0e0e8a42fa338f171c62
强化学习(RL)是智能体在[1]-[3]环境中学习最大化期望奖励的策略(从状态到动作的映射函数)的通用框架。当智能体与环境交互时,它试图通过试错方案来解决序列决策问题。由于其在性能上的显著成功,已在各种真实世界应用中得到快速开发和部署,包括游戏[4]-[6]、机器人控制[7]、[8],以及推荐系统[9]、[10]等,受到不同学科研究人员的越来越多的关注。
然而,强化学习仍有一些关键挑战需要解决。例如,**(一)数据效率低下。以前的方法大多需要交互数据,而在现实世界中,例如在医疗或医疗健康[11]中,只有少量记录数据可用,这主要是由于昂贵、不道德或困难的收集过程。(二)缺乏可解释性。**现有的方法往往通过深度神经网络将强化学习问题形式化,将序列数据作为输入,策略作为输出,属于黑盒理论。它们很难揭示数据背后的状态、动作或奖励之间的内部关系,也很难提供关于策略特征的直觉。这种挑战将阻碍其在工业工程中的实际应用。有趣的是,因果关系可能在处理上述强化学习[12],[13]的挑战中发挥着不可或缺的作用。因果关系考虑两个基本问题[14]:(1)因果关系的合法推断需要什么经验证据?利用证据发现因果关系的过程简称为因果发现。(2)给定一个现象的公认的因果信息,我们可以从这些信息中得出什么推论,如何推断?这种推断因果效果或其他利益的过程称为因果推断。因果关系可以授权智能体进行干预或通过因果阶梯进行反事实推理,放松了对大量训练数据的要求;它还能够描述世界模型,可能为智能体如何与环境交互提供可解释性。
**在过去的几十年里,因果学习和强化学习各自取得了巨大的理论和技术发展,而它们本可以相互融合。**Bareinboim[15]通过将它们放在相同的概念和理论框架下,开发了一个名为因果强化学习的统一框架,并提供了一个在线介绍教程;Lu[16]受当前医疗健康和医学发展的启发,将因果强化学习与强化学习相结合,引入因果强化学习并强调其潜在的适用性。近年来,一系列与因果强化学习相关的研究相继提出,需要对其发展和应用进行全面的综述。本文致力于为读者提供关于因果强化学习的概念、类别和实际问题的良好知识。 尽管已有相关综述,如Grimbly等人对[17]因果多智能体强化学习进行了综述;Bannon等人,[18]关于批量强化学习中的因果效应估计和策略外评估,本文考虑了但不限于多智能体或策略外评估的情况。最近,Kaddour等人,[19]在arXiv上上传了一篇关于因果机器学习的综述,其中包括一章关于因果强化学习的内容。他们根据因果关系可以带来的不同强化学习问题总结了一些方法,例如因果匪类、基于模型的强化学习、off-policy策略评估等。这种分类方法可能不完整或不完整,从而遗漏了其他一些强化学习问题,例如多智能体强化学习[18]。本文只是但完整地为这些因果强化学习方法构建了一个分类框架。我们对这份调研综述的贡献如下:
**本文正式定义了因果强化学习,并首次从因果性的角度将现有方法分为两类。**第一类是基于先验因果信息,通常这样的方法假设关于环境或任务的因果结构是由专家给出的先验信息,而第二类是基于未知的因果信息,其中相对的因果信息必须为策略学习。对每个类别上的当前方法进行了全面的回顾,并有系统的描述(和草图)。针对第一类,CRL方法充分利用了策略学习中的先验因果信息,以提高样本效率、因果解释能力或泛化能力。对于因果信息未知的CRL,这些方法通常包含因果信息学习和策略学习两个阶段,迭代或依次进行。进一步分析和讨论了CRL的应用、评估指标、开源以及未来方向。
因果强化学习
定义18(因果强化学习,CRL): CRL是一套算法,旨在将因果知识嵌入到RL中,以实现更高效的模型学习、策略评估或策略优化。它被形式化为元组(M, G),其中M代表RL模型设置,如MDP、POMDP、MAB等,G代表关于环境或任务的基于因果的信息,如因果结构、因果表示或特征、潜在混杂因素等。
根据因果信息是否由经验提供,因果强化学习方法大致分为两类:(i)基于已知或假设的因果信息的方法;(2)基于技术学习的未知因果信息的方法。因果信息主要包括因果结构、因果表示或因果特征、潜在混淆因素等。
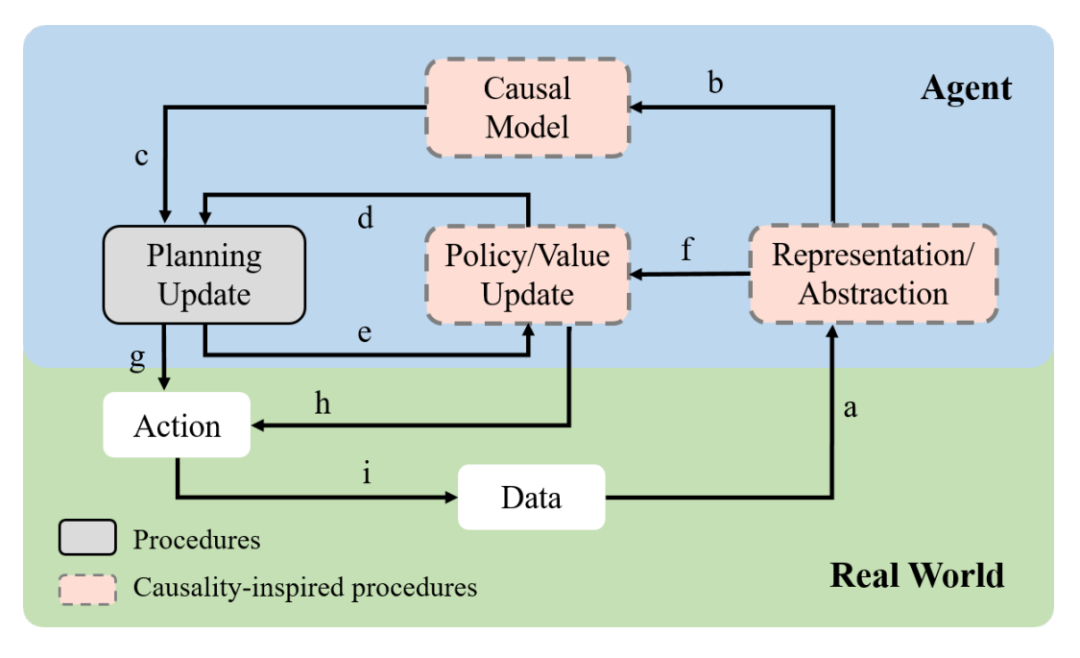
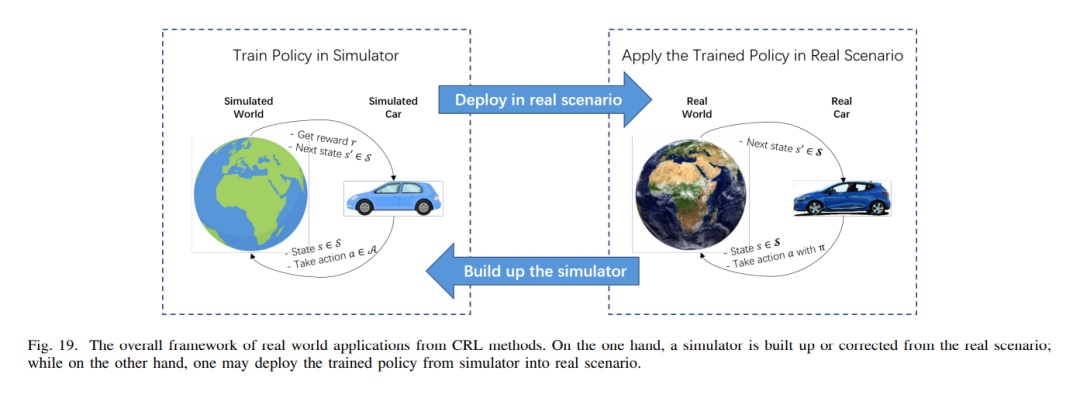
CRL框架的示意图如上图所示,概述了规划和因果启发学习程序之间可能的算法联系。因果关系启发的学习可以发生在三个地方:在学习因果表示或抽象(箭头a),学习动态因果模型(箭头b),以及学习策略或值函数(箭头e和f)。大多数CRL算法只实现与因果关系的可能联系的子集,在数据效率、可解释性、鲁棒性或模型或策略的泛化方面享受潜在好处。例如,t时刻的所有状态会影响(t + 1)时刻的所有状态。对于离线策略的学习和评估,因果信息未知的CRL会评估不同行为的影响,而因果信息已知的CRL通常通过敏感性分析来研究混淆对策略的影响。传统的强化学习不会对混淆效应进行建模。对于数据增强问题,经典RL有时基于基于模型的RL,而CRL基于结构因果模型。CRL在学习到这样的模型后,可以进行反事实推理来实现数据增强。在泛化方面,经典RL试图探索不变性,而CRL试图利用因果信息来产生因果不变性,例如结构不变性、模型不变性等。在理论分析方面,经典强化学习通常关注收敛性问题,包括学习策略的样本复杂度、后悔界或模型误差;CRL关注的是收敛性,但关注的是因果信息,侧重于因果结构的可识别性分析。