作为人工智能中最先进的技术之一,检索增强生成(RAG)技术可以提供可靠且最新的外部知识,为众多任务提供巨大便利。特别是在人工智能生成内容(AIGC)的时代,RAG在提供额外知识方面的强大检索能力使得检索增强生成能够协助现有的生成型AI产出高质量的输出。近期,大型语言模型(LLMs)在语言理解和生成方面展示了革命性的能力,但仍然面临固有的限制,如幻觉和过时的内部知识。鉴于RAG在提供最新且有用的辅助信息方面的强大能力,检索增强的大型语言模型已经出现,它们利用外部和权威的知识库,而不仅仅依赖于模型的内部知识,以提高LLMs的生成质量。在这份综述中,我们全面回顾了检索增强大型语言模型(RA-LLMs)的现有研究,涵盖了三个主要的技术视角:架构、训练策略和应用。作为初步知识,我们简要介绍了LLMs的基础和最近的进展。然后,为了阐述RAG对LLMs的实际意义,我们按应用领域分类主流相关工作,具体详述了每个领域的挑战及RA-LLMs的相应能力。最后,为了提供更深入的见解,我们讨论了当前的限制和未来研究的几个有希望的方向。
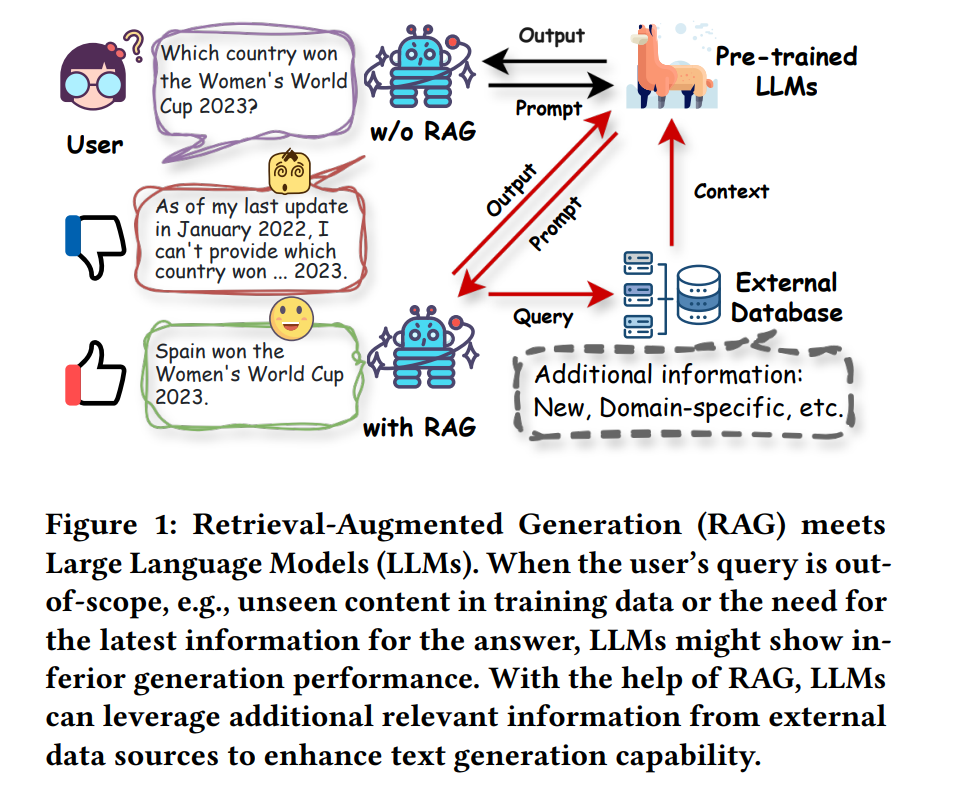
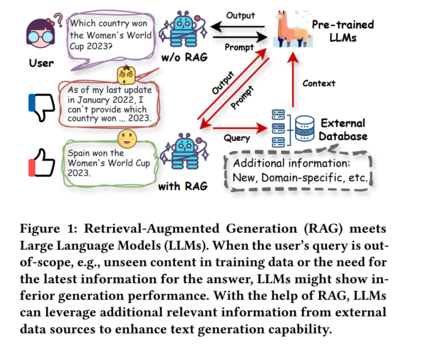
作为最基本的数据挖掘技术之一,检索旨在理解输入查询并从外部数据源提取相关信息[62, 132]。它在各个领域得到了广泛的应用[8, 100, 170],例如搜索、问答和推荐系统。例如,搜索引擎(如 Google、Bing 和 Baidu)是检索在行业中最成功的应用之一;它们可以筛选并检索最相关的网页或文档以匹配用户的查询[19, 170],使用户能够有效地找到所需信息。同时,通过在外部数据库中有效地维护数据,检索模型可以提供可靠且及时的外部知识,从而在各种知识密集型任务中发挥至关重要的作用。由于其强大的能力,检索技术已成功地融入到人工智能生成内容(AIGC)时代的先进生成模型中[72, 126, 155, 181]。值得注意的是,检索模型与语言模型的整合催生了检索增强生成(RAG)[69],它已成为生成人工智能领域最具代表性的技术之一,旨在提高文本内容的生成质量[6, 69, 72]。 为了推进生成模型并增强生成结果,RAG将信息或知识从外部数据源整合进来,作为输入查询或生成输出的补充[57, 97]。具体来说,RAG首先调用检索器从外部数据库中搜索并提取相关文档,然后利用这些文档作为上下文以增强生成过程[49]。在实践中,RAG技术在各种生成任务中的应用是可行且高效的,对检索组件进行简单的调整,几乎不需要或完全不需要额外的训练[111]。最近的研究表明,RAG不仅在开放领域问答(OpenQA)[6, 42, 103]等知识密集型任务中具有巨大潜力,而且也适用于一般语言任务[44, 57, 162]和各种下游应用[84, 155]。 近年来,预训练基础模型特别是大型语言模型(LLMs)的快速发展,表现出在各种任务上的卓越性能[1, 18],包括推荐系统[187]、分子发现[72]和报告生成[26]。LLMs的巨大成功技术上归功于拥有数十亿级参数的先进架构,在来自各种来源的大量训练语料上进行预训练。这些技术改进使得LLMs在语言理解和生成、上下文学习等方面展现出显著的能力[186, 187]。例如,GPT-FAR通过详细的提示教授GPT-4进行图像标记、统计分析和多模态时尚报告生成的文本分析[26]。LLMs还在通过理解用户对项目的偏好来实现推荐系统中的有希望的性能[146, 187]。尽管取得了成功,LLMs仍然受到固有限制的困扰[186, 187],如缺乏特定领域知识、“幻觉”问题以及更新模型所需的大量计算资源。这些问题在医学和法律等特定领域尤为明显。例如,最近的一项研究表明,法律幻觉普遍且令人不安,针对最先进LLMs的特定法律查询的幻觉率在69%至88%之间[21]。此外,由于进行微调LLMs以适应特定领域或最新数据所需的大量计算资源,解决幻觉问题的挑战变得更加艰巨,这反过来显著阻碍了LLMs在各种实际应用中的广泛采用。 为了解决这些限制,最近的努力旨在利用RAG增强LLMs在各种任务中的能力[6, 48, 57, 128],特别是那些对最新和可靠知识要求很高的任务,如问答(QA)、AI4Science和软件工程。例如,Lozano等人[86]引入了一种基于动态检索科学文献的科学特定问答系统。MolReGPT利用RAG增强ChatGPT在分子发现中的上下文学习能力[72]。如图1所示,基于LLM的对话系统无法很好地回答超出范围的查询。相比之下,借助RAG从外部数据来源检索相关知识并将其整合到生成过程中,对话系统成功地向用户提供了正确的答案。鉴于通过RAG推进LLMs的显著进展,迫切需要对检索增强大型语言模型(RA-LLM)的最新进展进行系统综述。 这份综述旨在通过总结RA-LLMs的代表性方法从架构、训练和应用方面提供检索增强大型语言模型的全面概述。更具体地说,继第2节简要介绍LLMs的背景知识后,我们在第3节从检索、生成和增强的主要视角回顾现有研究,并讨论了在RAG中检索的必要性和应用频率。然后,在第4节我们总结RA-LLMs的主要训练技术,在第5节讨论各种RA-LLMs应用。最后,在第6节,我们讨论关键挑战和未来探索的潜在方向。与我们的综述同时进行的几项相关综述具有不同的关注点,例如,赵等人[185]专门回顾了基于多模态信息的RAG技术,赵等人[184]讨论了针对AIGC的RAG。高等[37]对RAG用于LLMs进行了相对全面的概述。我们的综述与这些综述不同,侧重于技术视角并系统地按照RA-LLMs的架构和训练范式以及应用任务回顾模型。
检索增强的大型语言模型(RA-LLMs)
在LLMs时代的RAG框架通常包括三个主要过程:检索、生成和增强,以及确定是否需要检索的机制。在本节中,我们将介绍每个组成部分涉及的重要技术。检索根据LLMs输入的查询,RAG中的检索过程旨在从外部知识源提供相关信息,这些知识源可以是开源的也可以是封闭的,如图2所示。关键组件检索器,如图3进一步详细说明,包括几个程序,整体功能是衡量查询与数据库中文档之间的相关性,以有效检索信息。检索的具体流程还取决于是否包括预检索和后检索过程。在本小节中,我们将介绍传统和基于LLM的RAG检索中涉及的主要技术,包括检索器类型、检索粒度、预检索和后检索增强以及数据库构建。
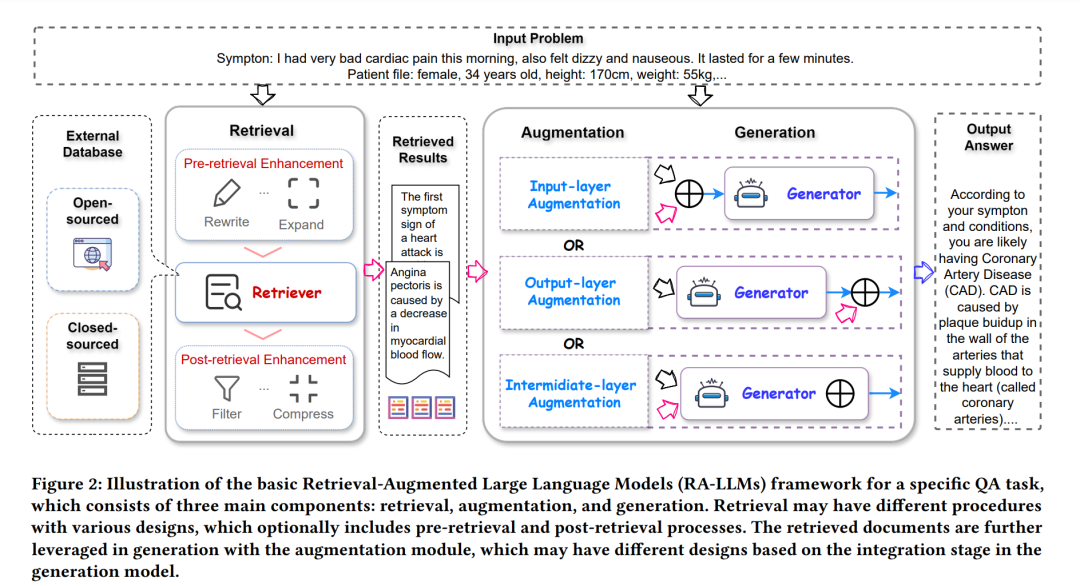
生成生成器的设计在很大程度上依赖于下游任务。对于大多数文本生成任务,仅解码器和编码器-解码器是两种主导结构[186]。商业闭源的大型基础模型的最近发展使得黑箱生成模型在RA-LLMs中成为主流。在这部分中,我们将简要回顾这两种类型的生成器的研究:可访问参数(白箱)和不可访问参数(黑箱)。增强描述了集成检索和生成部分的技术过程,这是 RA-LLMs 的核心部分。在本小节中,我们介绍了三种主要的增强设计,分别在生成器的输入、输出和中间层进行,如图 2 所示。
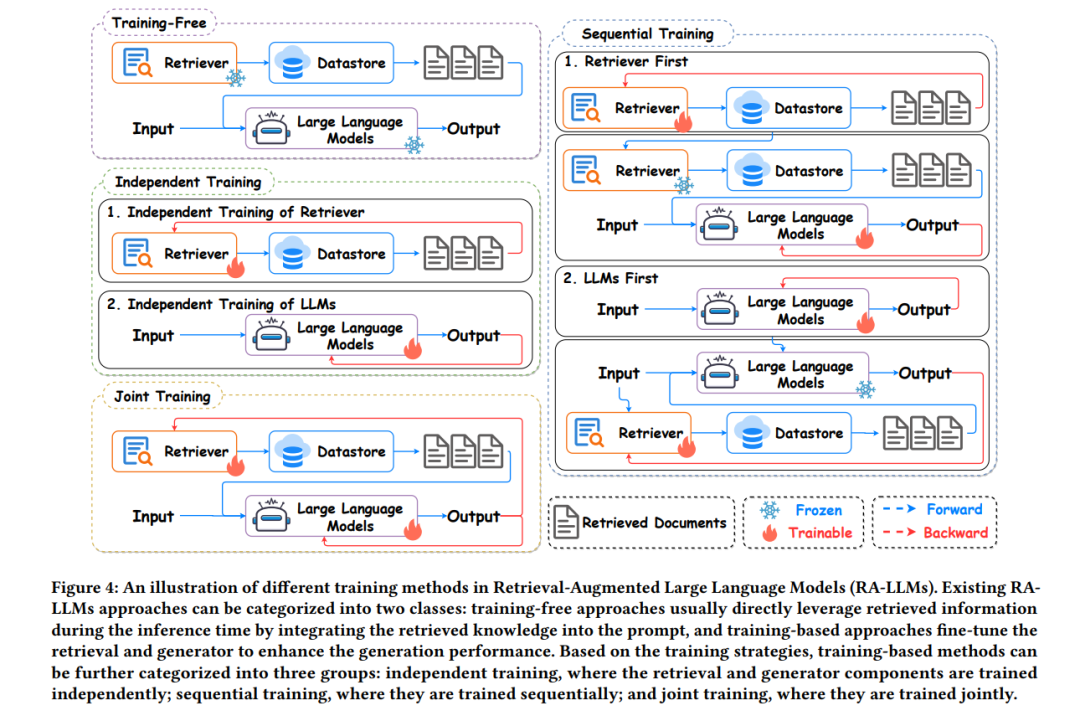
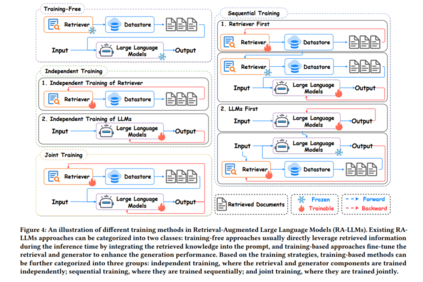
根据是否需要训练,现有的 RAG 方法可以分为两大类:无需训练的方法和基于训练的方法。无需训练的方法通常在推理时直接利用检索到的知识,通过将检索到的文本插入到提示中,无需引入额外训练,这在计算上是高效的。然而,一个潜在的挑战是,检索器和生成器组件没有针对下游任务进行特别优化,这可能导致检索知识的次优利用。为了充分利用外部知识,提出了广泛的方法来微调检索器和生成器,从而指导大型语言模型有效地适应和整合检索到的信息[121, 122, 124, 128, 145, 191]。
根据训练策略,我们将这些基于训练的方法分为三类:1) 独立训练方法独立训练 RAG 流程中的每个组件,2) 顺序训练方法先训练一个模块,然后冻结训练良好的组件来指导其他部分的调整过程,3) 联合训练方法同时训练检索器和生成器。在接下来的部分中,我们将全面回顾无需训练、独立训练、顺序训练和联合训练方法。这些不同训练方法的比较如图 4 所示。