从起源到具体算法,这篇深度学习综述论文送给你
来源:机器之心
本文共4602字,建议阅读8分钟。
本文为大家从最基础的角度来为大家解读什么是深度学习,以及深度学习的一些前沿发展。
自 2012 年多伦多大学 Alex Krizhevsky 等人提出 AlexNet 以来,深度学习作为一种机器学习的强大方法逐渐引发了今天的 AI 热潮。随着这种技术被应用到各种不同领域,人们已经开发出了大量新模型与架构,以至于我们无法理清网络类型之间的关系。近日,来自 University of Dayton 的研究者们对深度学习近年来的发展历程进行了全面的梳理与总结,并指出了目前人们面临的主要技术挑战。小编觉得这是一份非常详细的综述论文,既适合从零开始了解深度学习的人,又适合有基础的学习者。
论文地址:https://arxiv.org/abs/1803.01164
近年来,深度学习作为机器学习的新分支,其应用在多个领域取得巨大成功,并一直在快速发展,不断开创新的应用模式,创造新机会。深度学习方法根据训练数据是否拥有标记信息被划分为监督学习、半监督学习和无监督学习。实验结果显示了上述方法在图像处理、计算机视觉、语音识别、机器翻译、艺术、医学成像、医疗信息处理、机器人控制和生物、自然语言处理(NLP)、网络安全等领域的最新成果。本报告简要概述了深度学习方法的发展,包括深度神经网络(DNN)、卷积神经网络(CNN)、循环神经网络(RNN)(包括长短期记忆(LSTM)和门控循环单元(GRU))、自 编码器(AE)、深度信念网络(DBN),生成对抗网络(GAN)和深度强化学习(DRL)。此外,本文也涵盖了深度学习方法前沿发展和高级变体深度学习技术。此外,深度学习方法在各个应用领域进行的探索和评估也包含在本次调查中。我们还会谈到最新开发的框架、SDK 和用于评估深度学习方法的基准数据集。然而,这些论文并没有讨论某些大型深度学习模型和最新开发的生成模型方法 。
介绍
自 20 世纪 50 年代以来,作为人工智能子领域的机器学习已经开始革新若干个领域,而诞生自机器学习的深度学习实现了迄今为止最大的原创性突破,几乎在每个应用领域取得了显著成功。图 1 给出了 AI 的谱系。深度学习(学习或分层学习方法的深层架构)是从 2006 年兴起的一类机器学习技术。在深度学习中,学习即是评估模型参数,使学习模型(算法)可执行特定任务。例如,在人工神经网络(ANN)中,参数是权重矩阵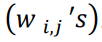
深度学习方法的类型
像机器学习一样,深度学习方法可以分为以下几类:监督、半监督、部分监督以及无监督。此外,还有另一类学习方法称为强化学习(Reinforcement Learning)或深度强化学习(Deep Reinforcement Learning),它们经常在半监督或非监督学习方法的范围内讨论。
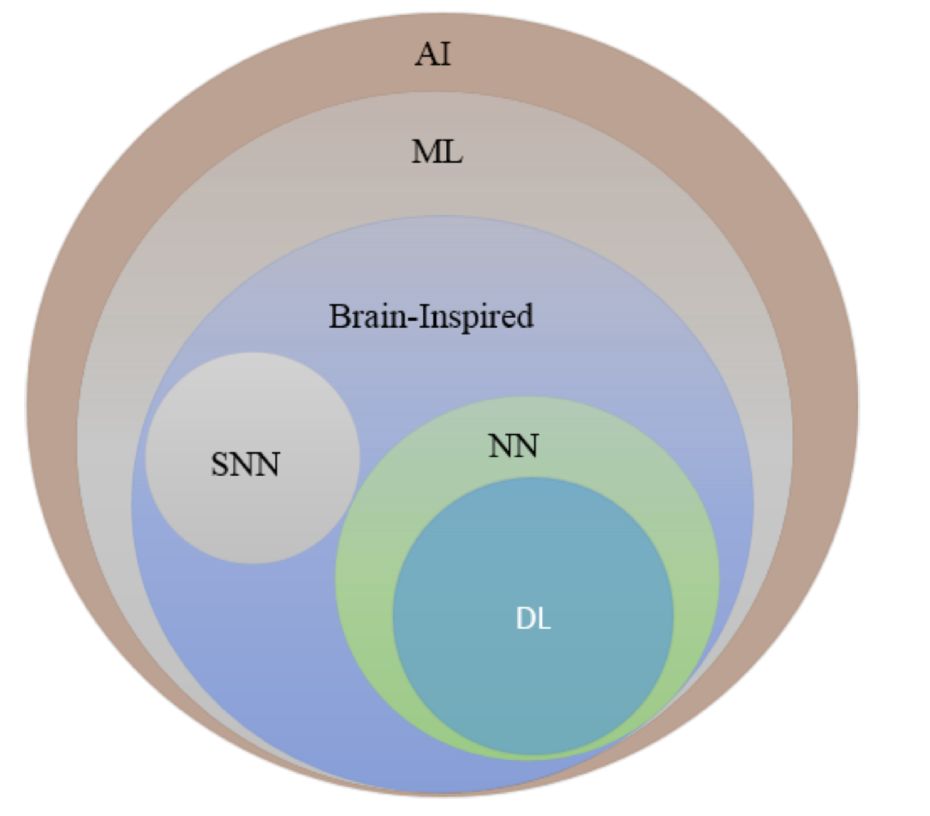
图 1:人工智能谱系:AI、机器学习、神经网络、深度学习和脉冲神经网络(SNN)。
1. 监督学习
一种使用标注数据的学习技术。在其案例中,环境包含一组对应的输入输出 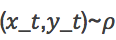
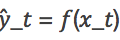
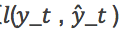
2. 半监督学习
一种使用部分标注数据的学习技术(通常被称之为强化学习)。本文第 8 节调查了其方法。在一些案例中,深度强化学习(DRL)和生成对抗网络(GAN)常被用作半监督学习技术。此外,包含 LSTM 的 RNN 和 GRU 也可划分为半监督学习。GAN 将在第 7 节讨论。
3. 无监督学习
一种不使用标注数据的学习技术。在这种情况下,智能体学习内部表示或重要特征以发现输入数据中的未知关系或结构。无监督学习方法通常有聚类、降维和生成技术等。有些深度学习技术擅长聚类和非线性降维,如自编码器(AE)、受限玻尔兹曼机(RBM)和 GAN。此外,RNN(比如 LSTM)和 RL 也被用作半监督学习 [243]。本文第 6、7 节将分别详述 RNN 和 LSTM。
4. 深度强化学习(DRL)
一种适用于未知环境的学习技术。DRL 始于 2013 年谷歌 Deep Mind。从此,人们基于 RL 提出了几种先进的方法,例如:如果环境样本输入:agent〜ρ,agentpredict: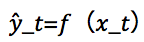
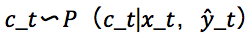
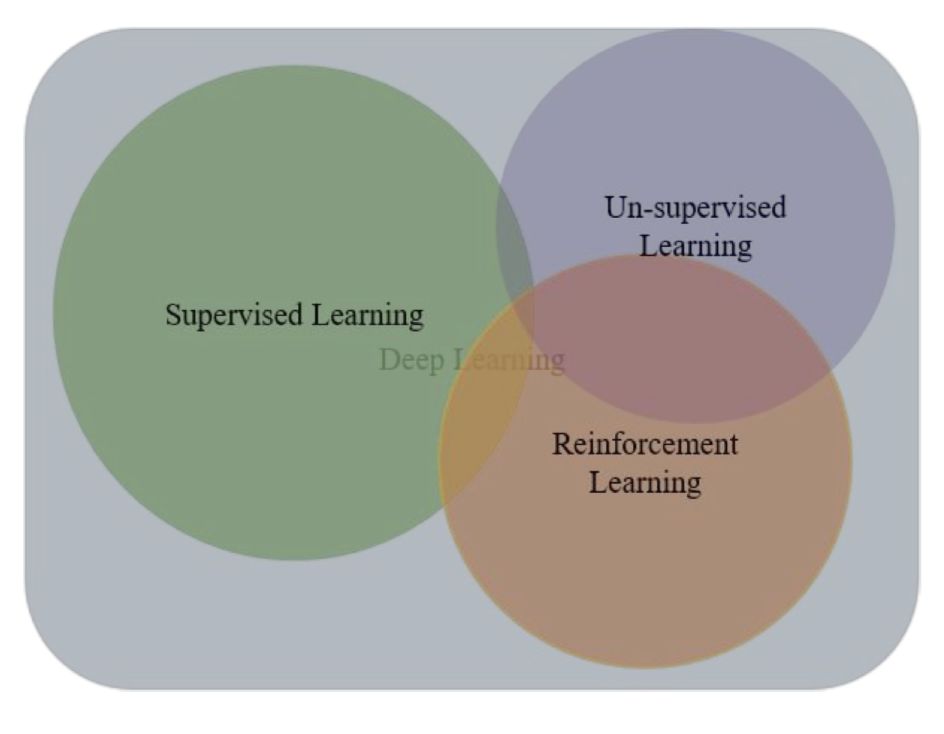
图 2:深度学习方法的分类
特征学习
传统机器学习和深度学习之间的关键区别在于如何提取特征。传统机器学习方法通过应用几种特征提取算法,包括尺度不变特征变换(SIFT)、加速鲁棒特征(SURF)、GIST、RANSAC、直方图方向梯度(HOG)、局部二元模式(LBP)、经验模式分解(EMD)语音分析等等。最后,包括支持向量机(SVM)、随机森林(RF)、主成分分析(PCA)、核主成分分析(KPCA)、线性递减分析(LDA)、Fisher 递减分析(FDA)等很多学习算法都被人们应用于分类和提取特征的任务。此外,其他增强方法通常多个应用于单个任务或数据集特征的学习算法,并根据不同算法的多个结果进行决策。
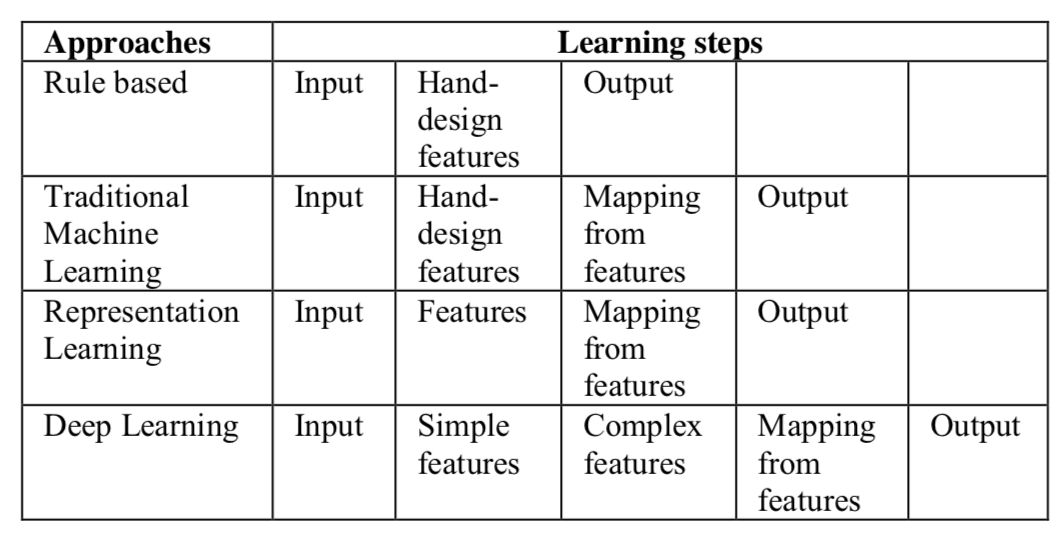
表 1:不同的特征学习方法
另一方面,在深度学习中,这些特征会被自动学习并在多个层上分层表示。这是深度学习超越传统机器学习方法的原因。上表展示了不同特征学习方法与不同学习步骤之间的关系。
用深度学习的时机和领域
人工智能在以下领域十分有用,深度学习在其中扮演重要角色:
缺乏人类专家(火星导航);
人们尚无法解释的专业知识(演讲、认知、视觉和语言理解);
问题的解决方案随时间不断变化(追踪、天气预报、偏好、股票、价格预测);
解决方案需要适应特定情况(生物统计学、个性化);
人类的推理能力有限,而问题的规模却很大(计算网页排名、将广告匹配到 Facebook、情感分析)。
目前,深度学习几乎在各个领域都有应用。因此,这种方法有时也被称为通用学习方法。图 4 显示了一些示例应用程序。

图 4:成功应用深度学习并取得顶级结果的示例图
深度学习的前沿发展
深度学习在计算机视觉和语音识别领域有一些突出的成就,如下所述:
1. ImageNet 数据集上的图像分类
深度学习在图像分类领域的应用基准被称为大规模视觉识别挑战(LSVRC)。基于深度学习和卷积神经网络技术,深度学习在 ImageNet 测量精确度中有很好的表现 。近日,Russakovsky 等人发表了一篇关于 ImageNet 数据集的文章及近年来研究者们实现的最高精确度 。下图显示了 2012 年深度学习技术的发展历程。时至今日,我们开发的方法在 ResNet-152 上只有 3.57%的误差,低于人类约 5% 的误差。
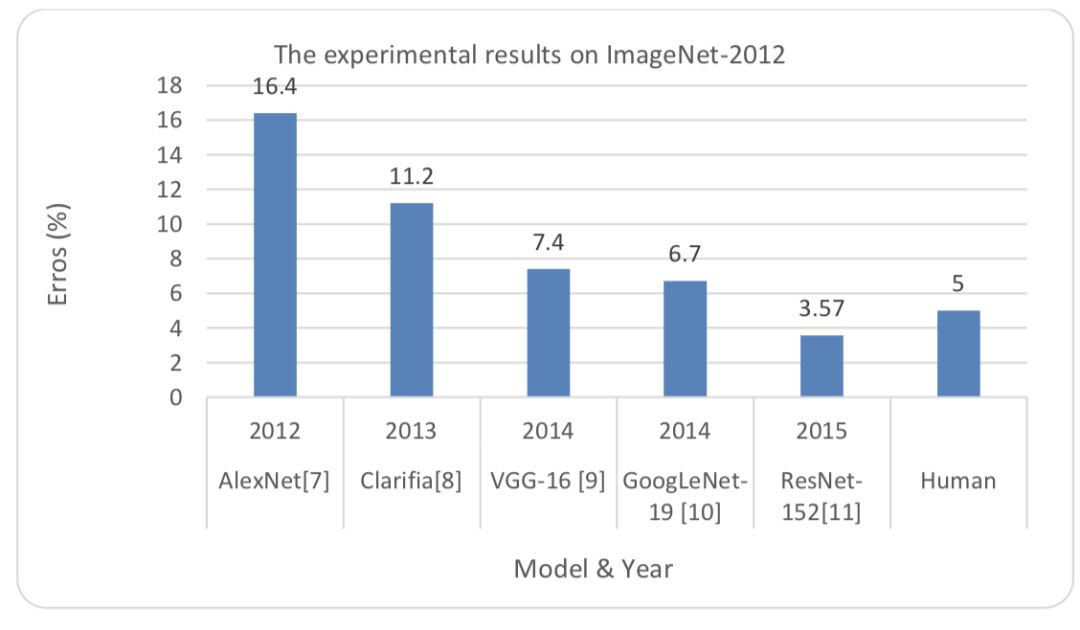
图 5:使用不同深度学习模型在 ImageNet 测试的准确性。
2. 自动语音识别
深度学习通过 TIMIT 数据集(通用数据集通常用于评估)完成的小规模识别任务是深度学习在语音识别领域的初次成功体现。TIMIT 连续声音 - 语音语料库包含 630 位来自美国的八种主要英语口音使用者,每位发言人读取 10 个句子。下图总结了包括早期结果在内的错误率,并以过去 20 年的电话错误率(PER)来衡量。条形图清楚地表明,与 TIMIT 数据集上以前的机器学习方法相比,最近开发的深度学习方法(图顶部)表现更好。
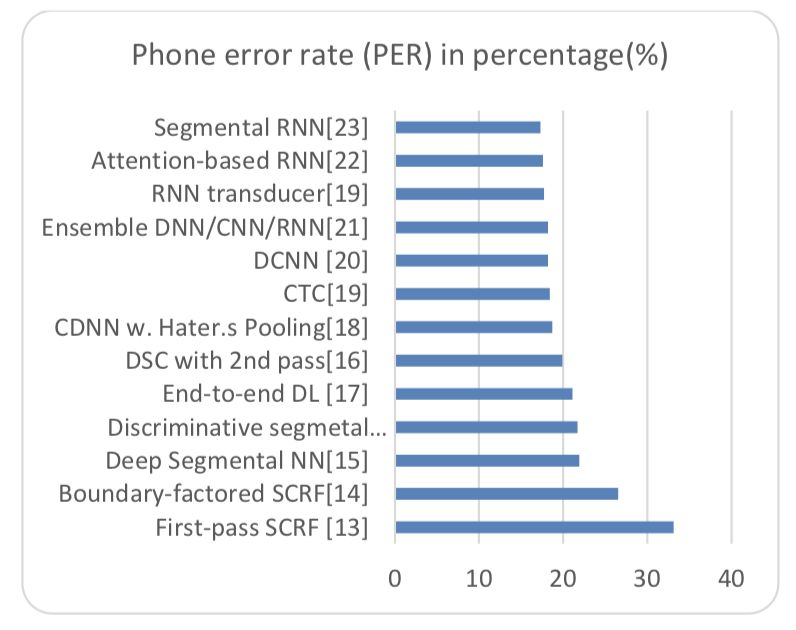
图 6:TIMIT 数据集的电话错误率(PER)
为什么要使用深度学习
1. 通用学习方法
深度学习有时被称为通用学习,因为它几乎可以应用于任何领域。
2. 鲁棒性
深度学习方法不需要提前设计功能。其自动学习的功能对于当前的任务来说是最佳的。结果是,任务自动获得对抗数据自然变化的鲁棒性。
3. 泛化
相同的深度学习方法可以用于不同的应用程序或不同的数据类型,这种方法通常被称为迁移学习。另外,这种方法在可用数据不足时很有用。根据这个概念研究学者已经发表了多篇论文(在第 4 节中会有更详细地讨论)。
4. 可扩展性
深度学习方法具有高度可扩展性。在 2015 年的一篇论文中,微软描述了一个名为 ResNet 的网络 。该网络包含 1202 个层,并且通常由超级计算规模部署。美国的劳伦斯利弗莫尔国家实验室(LLNL)正在为这样的网络开发框架,该框架可以实现数千个节点 [24]。
深度学习面临的挑战:
使用深度学习进行大数据分析
深度学习方法要有可扩展性
在数据不可用于学习系统的情况下(尤其是对于计算机视觉任务,例如反向图形),生成数据的能力非常重要。
特殊用途设备的低能耗技术,如移动端智能,FPGA 等。
多任务和迁移学习(泛化)或多模块学习。这意味着要从不同的领域或不同的模型一起学习。
在学习中处理因果关系。
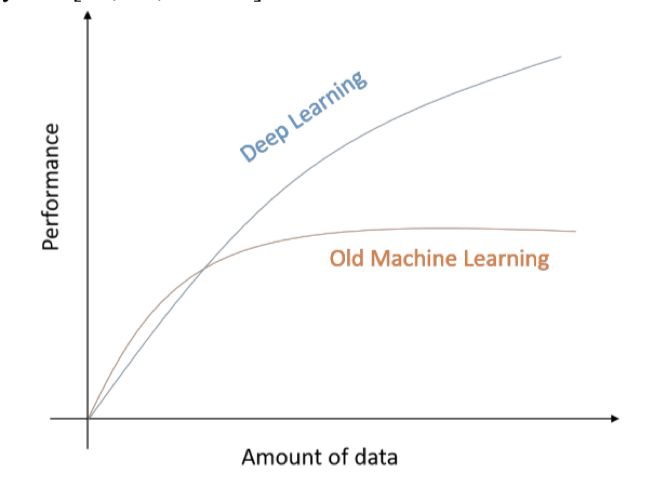
图 7:深度学习的性能与数据数量之间的关系。
其次,大部分针对大规模问题的案例,其解决方案正在高性能计算机(HPC)系统(超级计算机、集群,有时被视为云计算)上部署,这为数据密集型商业计算提供了巨大的潜力。但随着数据在速度,多样性,准确性和数量上的爆炸式增长,我们越来越难以使用企业级服务器进行存储和提升计算性能。大多数论文考虑到这些需求,并提出了使用异构计算系统的高效 HPC。例如:劳伦斯利弗莫尔国家实验室(LLNL)开发了一个框架:Livermore Big Artificial Neural Networks(LBANN),用于大规模部署深度学习(超级计算规模),这一项目明确地回答了深度学习是否可扩展的问题 [24]。
第三,生成模型是深度学习的另一个挑战,其中一个例子是 GAN,它是一种优秀的数据生成方法,可以生成具有相同分布数据 [28]。第四,我们在第七节讨论过的多任务和迁移学习。第四,我们对网络架构和硬件方面的高效率深度学习方法进行了大量的研究。第 10 节讨论了这个问题。
我们可以制作出适用于多领域、多任务的通用模型吗?出于对多模式系统的关注,最近,谷歌提交的论文《One Model To Learn Them All》介绍了一种新方法,其可以从不同的应用领域学习,包括 ImageNet、多种翻译任务、图像标题(MS-COCO 数据集)、语音识别语料库和英语解析任务。我们将通过这次调查讨论主要挑战和相应的解决方案。在过去几年中,人们还提出了其他多任务技术。
最后,图形模型是一个具有因果关系的学习系统,用于定义如何根据数据推断因果模型。最近,已经出现了解决此类问题的深度学习方法。但是,在过去几年中,还有其他许多具有挑战性的问题仍未得到有效地解决。例如:图像或视频字幕,使用 GAN [35] 从文本到图像合成以及其他从一个域到另一个域的风格迁移。
最近,一些研究者完成了很多关于深度学习的调查,其中有一篇非常高质量的总结,但它没有涉及最近开发的 GAN 的生成模型。此外,它提及了强化学习的话题,但没有涉及深度强化学习方法的近期趋势。大多数情况下,调查是依据深度学习的不同方法来分类的。本报告的主要目标是介绍深度学习的总体思路及其相关领域,包括深度监督(如 DNN、CNN 和 RNN)、无监督(如 AE、RBM、GAN)(有时 GAN 也用于半监督学习任务)和深度强化学习的思路。在某些情况下,深度强化学习被认为是半监督/无监督的方法。我们考虑了该领域的最新发展趋势以及基于该技术开发的应用。此外,我们还囊括了评估深度学习技术常用的框架和基准数据集,会议和期刊的名称也包括在内。
本论文的其余部分的组织方式如下:
第二节讨论 DNN 的详细调查,
第三节讨论 CNN;
第四节介绍了不同的先进技术,以有效地训练深度学习模型;
第五节讨论 RNN;
AE 和 RBM 在第六节中讨论;
GAN 及其应用在第七节讨论;
强化学习在第八节中介绍;
第九节解释迁移学习;
第十节介绍了深度学习的高效应用方法和硬件;
第十一节讨论了深度学习框架和标准开发工具包(SDK);
第十二节给出了不同应用领域的基准测试结果;第十三节为结论。
本文原作者:机器之心 公众号;本次编辑转自:数据派THU 公众号;
END
关联阅读:
原创系列文章:
数据运营 关联文章阅读:
数据分析、数据产品 关联文章阅读:




