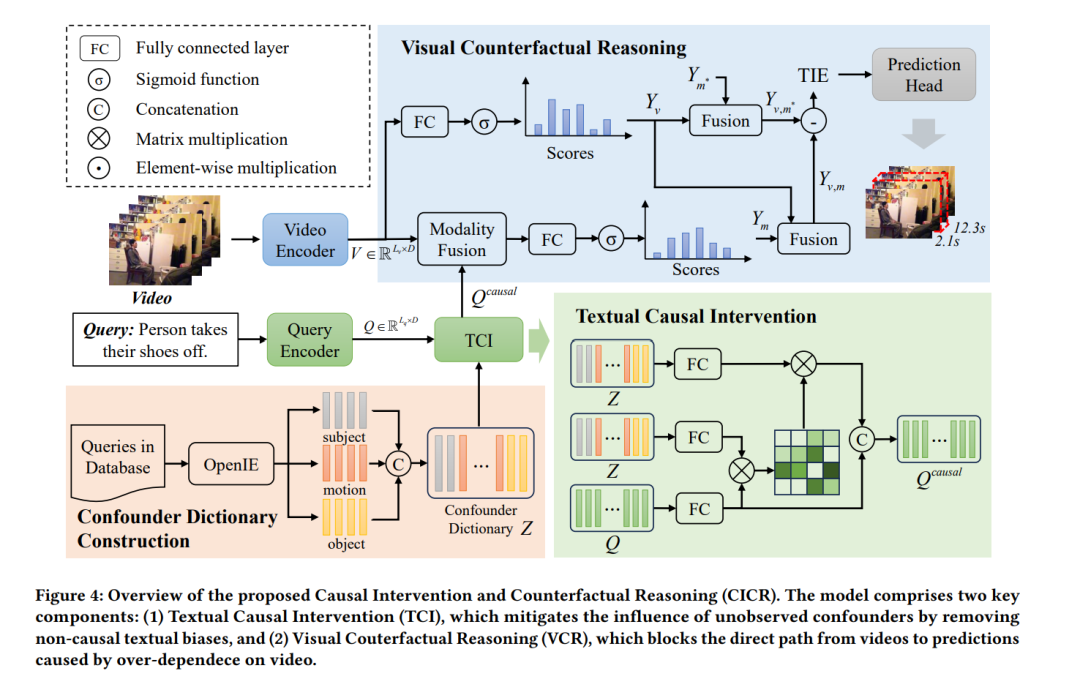
时间句子定位(Temporal Sentence Grounding,TSG) 旨在从未经剪辑的视频中识别出与给定文本查询语义对应的相关时刻。尽管现有研究在该任务上已取得了显著进展,但它们往往忽视了视频与文本查询之间伪相关(spurious correlations)的问题。这些伪相关主要源于两个因素:(1)文本数据中固有的偏差,例如特定动词或短语的频繁共现;(2)模型容易过拟合视频内容中的显著或重复模式。这些偏差会误导模型将文本线索与错误的视频片段建立关联,从而导致预测不可靠,并在处理分布外样本时泛化能力较差。 为克服这些局限性,我们提出了一种新颖的 TSG 框架,通过因果干预与反事实推理(causal intervention and counterfactual reasoning),利用因果推理消除伪相关性并增强模型的鲁棒性。具体而言,我们首先从因果视角出发,使用结构性因果模型(structural causal model)对 TSG 任务进行建模。随后,为应对源自文本中对特定动词或短语偏好的不可观测混淆因子(unobserved confounders),我们提出了一种文本因果干预方法(textual causal intervention),基于 do-演算(do-calculus)来估计因果效应。此外,我们还进行视觉反事实推理(visual counterfactual reasoning),通过构造一个只包含视频特征、不包含查询与融合模态特征的反事实场景,从而隔离并移除视频本身对总体效果的影响,实现模型去偏。 在多个公开数据集上的实验结果表明,所提出的方法具有优越的性能。代码可通过以下地址获取:https://github.com/Tangkfan/CICR