

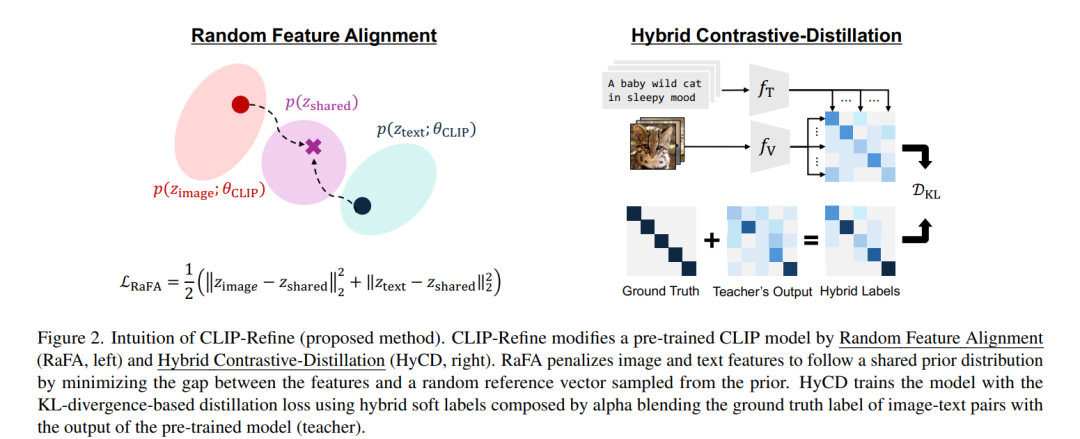
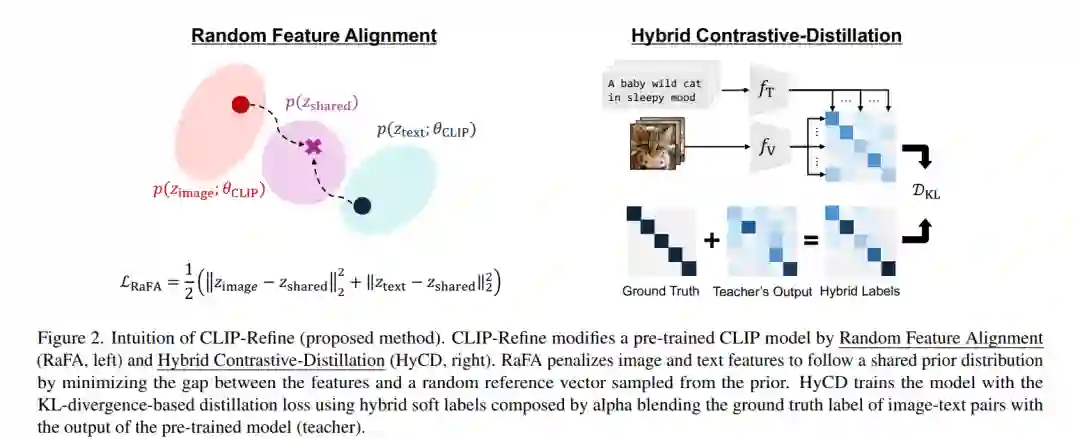
对比语言-图像预训练(Contrastive Language-Image Pre-training, CLIP)是构建现代视觉-语言基础模型的核心组成部分。尽管 CLIP 在下游任务中展现出出色的零样本(zero-shot)性能,其多模态特征空间仍然存在模态差距(modality gap)——即图像与文本特征之间的聚类差异,这限制了下游任务的表现。 虽然已有研究试图通过修改预训练或微调流程来缓解这一模态差距,但往往面临两个难题:需要大规模数据集带来的高昂训练成本,或在零样本性能上的显著下降。 本文提出了一种新的后预训练方法,命名为 CLIP-Refine,该方法介于 CLIP 的预训练与微调阶段之间。CLIP-Refine 的目标是对特征空间进行对齐,通过在小规模图文配对数据集上仅训练 1 个 epoch,实现无损的零样本性能优化。 为此,我们提出了两项关键技术: 1. 随机特征对齐(RaFA, Random Feature Alignment):通过最小化图像与文本特征与随机采样的参考向量之间的距离,使其分布趋向于共享的先验分布,从而实现模态间对齐。 1. 混合对比-蒸馏学习(HyCD, Hybrid Contrastive-Distillation):结合图文对的真实标签与预训练 CLIP 模型的输出,生成软标签,用于更新模型。这种方式在保留原有知识的同时,促进了新知识的学习,实现更优的特征对齐效果。
我们在多个分类与检索任务上进行了广泛实验,结果表明,CLIP-Refine 能有效缩小模态差距,并进一步提升 CLIP 模型的零样本性能。
成为VIP会员查看完整内容

相关内容
Arxiv
224+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日