近年来,随着人工智能与大数据技术的发展,深度神经网络在语音识别、自然语言处理、图像理解、视 频分析等应用领域取得了突破性进展. 深度神经网络的模型层数多、参数量大且计算复杂,对硬件的计算能力、 内存带宽及数据存储等有较高的要求. FPGA 作为一种可编程逻辑器件,具有可编程、高性能、低能耗、高稳定、 可并行和安全性的特点. **FPGA 与深度神经网络的结合成为推动人工智能产业应用的研究热点. **本文首先简述了人工神经网络坎坷的七十年发展历程与目前主流的深度神经网络模型,并介绍了支持深度神经网络发展与应用的主 流硬件;接下来,在介绍 FPGA 的发展历程、开发方式、开发流程及型号选取的基础上,从六个方向分析了 FPGA 与深度神经网络结合的产业应用研究热点;然后,基于 FPGA 的硬件结构与深度神经网络的模型特点,总结了基 于 FPGA 的深度神经网络的设计思路、优化方向和学习策略;接下来,归纳了 FPGA 型号选择以及相关研究的评 价指标与度量分析原则;最后,我们总结了影响 FPGA 应用于深度神经网络的五个主要因素并进行了概要分析.
引言**
随着智能化时代的到来,人工智能的应用已经 深入到社会的各行各业. 作为人工智能的主要研究 分支,神经网络的研究和发展成为主导当前智能化 程度的主要力量. 简单来讲,神经网络是通过模拟 人脑中神经元的连接方式来实现类脑的信息处理过 程. 在过去的七十年发展历史中,神经网络的发展 也经历了质疑和低谷,得幸于研究者的坚持探索才 使它被普遍认可并有机会更好的造福人类. 为让机 器更好地模拟人脑来认识世界,神经网络模型不断 革新发展,经历了从浅层神经网络到深度神经网络 的重要变革. 目前,深度神经网络可以利用深层的 结构很好地提取和拟合数据特征,并在语音识别、 自然语言处理、图像理解、视频分析等应用领域取 得了突破性进展. 研究者在追求更好精度的同时, 深度神经网络模型层数和参数数量也在不断增加, 从而对硬件的计算能力、内存带宽及数据存储等的 要求也越来越高. 因此. 计算能力强、可并行加速、 数据吞吐高的高性能硬件平台对于模型训练和产业 应用来说显得尤为重要. 本节将概述神经网络的发 展史和当前流行的深度神经网络模型,并分析推动 深度神经网络产业应用的主流硬件平台.
1.1 深度神经网络的发展历程**
相比今天神经网络的发展速度,其基础理论研 究初期却经历重重波折. 最早的神经网络数学模型 是由心理学家 McCulloch 教授和数学家 Pitts 教授于 1943 年提出的模拟人类大脑神经元的 McCullochPitt 神经元模型,并被称为 M-P 模型[1]. 该模型是通 过简单的线性加权来实现对人类神经元处理信号的 模拟,该工作被称为人工神经网络(ANN)的起点,随后出现的神经网络模型均是以该模型为基础的**. 然而,其性能的好坏完全由分配的权重决定,这就 使该模型很难达到最优的效果. 随后,为了改善该 模型并让计算机自动合理的设置权重,心理学家 Hebb 于 1949 年提出 Hebb 学习规则[2]并得到诺贝尔 医学奖得主 Kandel 的认可. 康奈尔大学的实验心理 学家 Rosenblatt 于 1958 年提出感知机模型[3],该模 型是第一个真正意义上的人工神经网络,标志着神 经网络研究进入了第一次高潮期. Minsky 和 Papert 等学者对感知机模型进行了分析,结论为该模型无 法求解简单的异或等线性不可分问题[4],从此神经 网络的发展进入低潮甚至几乎处于停滞状态. 随 后,并行分布处理[5]、反向传播算法[6]及 1982 年连 续和离散 Hopfield 神经网络模型的提出为研究者重 新打开了思路,开启了神经网络发展的又一个春天, 此后的神经网络模型研究开始向问题导向发展.
1985 年 Sejnowski 和 Hinton 受 Hopfield 神经网 络模型的启示提出的玻尔兹曼机模型[7]. 该模型通 过学习数据的固有内在表示来解决困难学习的问 题,随后又针对模型局限性进一步提出受限玻尔兹 曼机模型[8]和深度玻尔兹曼机模型[9]. 反向传播算 法于 1986 年得到进一步发展,成为后续神经网络 模型发展的基石[10],1990 年用于解决数据结构关 系的递归神经网络出现[11]. 经过半个世纪的研究, 加拿大多伦多大学的教授 Hinton 等人在 2006 年提 出了深度置信网络模型[12],不但提出了多隐层的神 经网络,而且提出了深层神经网络在训练问题上的 解决方法,该模型开启了深度神经网络的研究热 潮.** 自此,针对特定研究问题的深度神经网络模型 大量涌现**.
深度卷积神经网络是一种受启发于人类大脑对眼睛里接收到的信号的理解过程而提出的神经网络 模型. 该网络作为人工神经网络的典型模型之一被 提出并出色地应用于计算机视觉领域. LeCun 等人 提出的 LeNet 模型作为卷积神经网络的雏形起初被 应用于手写体识别 . 2012 年 Hinton 等人提出 AlexNet 模型,并应用 ImageNet 图像识别大赛中[13], 其精确度颠覆了图像识别领域,使卷积神经网络进 入大众视野. 随后出现了大量经典卷积神经网络模 型如在网络层次上进行加深的 NIN[14],GoogLeNet[15], VGGNet[16] 等,通过拆分卷积核来提升效率的 Inception V2/V3[17],在深层网络中引入连跳结构来 缓解梯度消失的 ResNet[18]和 DenseNet[19]等. 除此 之外,还有建模特征通道间相互依赖关系的 SENet[20]、基于 ResNet 进行改进的 ResNext[21]及 ResNeSt[22]等. 在不同的研究领域也出现大量经典 的卷积神经网络模型,如致力于全景分割的 UPSNet[23]、FPSNet[24]和 OANet[25]等,致力于目标 检测的 Faster-RCNN[26] 、 YOLO v1/v2/v3[27–29] 、 SSD[30]、EfficientDet[31]、LRF-Net[32]等,致力于目 标跟踪的 SimeseNet[33]、MDNet[34]. 目前,随着社会 的不断进步,卷积神经网络的各种变型模型已经被 应用于无人驾驶、智能监控和机器人等领域. 胶囊 网络是 Hinton 团队于 2017 年为弥补卷积神经网络 在物体空间关系上认知的不足而提出的一种新的网 络体系结构. 其与卷积神经网络的区别在于,该网 络是一种由含有一小群神经元的胶囊组成新型的神 经网络[35],这些胶囊之间通过动态路由来传递特征. 胶囊网络独特的数据表示方式使其考虑了目标的位 置、方向、形变等特征,并能对提取的特征进行理 解. 随后,为提升胶囊网络的性能,对胶囊进行优 化[36–38]和对动态路由进行优化[39, 40]的方法被提出. 目前,胶囊网络的成就主要有抵御对抗性攻击、结 合图卷积神经网络进行图像分类、结合注意力机制 进行零样本意图识别等。
深度强化学习是一种集感知能力和决策能力为 一体的神经网络模型,其应用成果真正进入大众视 野是在 Alpha Go 出现后. Google DeepMind 公司提 出的深度强化学习模型 Deep Q-Network[41]让这一 更接近人类思维方式的模型得到更多学者的青睐. 随后,针对 Deep Q-Network 计算方法、网络结构 和数据结构进行改进出现了 Double DQN、Dueling Network 和 Prioritized Replay 三种强化学习模型. 另 外,Deep Q-Network 加入了递归思想生成了 Deep Recurrent Q-Network. 田春伟等人将强化学习思想 用于目标跟踪领域并提出了 ADNet 模型[42]. 除此之 外,继 Alpha Go 之后,DeepMind 又推出基于强化 学习的 AlphaZero[43]和 MuZero[44],提高了深度神经 网络的智能化水平. 生成对抗网络(GAN)[45]是由 Goodfellow 等人在 2014 年提出的,是采用博弈对抗 理论的一种新型神经网络模型. 该模型打破了已存 在的神经网络对标签的依赖性,一出现就受到业界 的欢迎并衍生出许多广泛流行的构架模型,主要有:第一次将 GAN 和卷积神经网络相结合的 DCGAN 模型[46]、利用 GAN 刷新人脸生成任务的 StyleGAN 模型[47]、探索文本和图像合成的 StackGAN 模型[48]、 进行图像风格转化的 CycleGAN[49]、Pix2Pix[50]和 StyleGAN[47],首次可生成具有高保真度低品种差距 图像的 BigGAN[51],用于解决视频跟踪问题中样本 不均衡问题的 VITAL 网络模型[52]. 图神经网络是针 对图结构数据发展而来的一种神经网络模型,该模 型可以对可转化为图结构的数据之间的关系进行处 理分析,它克服了已有的神经网络模型在处理不规 则数据时的不足. 图神经网络模型最早起源于 2005 年[53],随后由 Franco 博士在 2009 年首次定义了该 模型的理论基础[54],提出之初,该模型并没有引起 很大波澜,直到 2013 年图神经网络才得到广泛关注. 近年来图神经网络得到广泛应用,同时结合已有网 络模型. 图神经网络的不同拓展模型被不断提出, 如图卷积网络(Graph Convolutional Networks)[55]、 图注意力网络(Graph Attention Networks)[56]、图 自编码器(Graph Auto-encoder)[57]、图时空网络 (Graph Spatial-Temporal Networks)[58]、图强化学 习[59–61]、图对抗网络模型[62,63]等. 目前,图神经网 络模型应用比较广泛,不仅被应用于计算机视觉、 推荐系统、社交网络、智能交通等领域,还被应用 于物理、化学、生物和知识图谱等领域.
轻量级神经网络是在保证模型的精度下对神经 网络结构进行压缩、量化、剪枝、低秩分解、教师学生网络、轻量化设计后的小体积网络模型. 2015 年之前,随着神经网络模型性能的不断提升,不断 增大的网络体积和复杂度对计算资源也有较高的需 求,这就限制了当前高性能的网络模型在移动设备 上的灵活应用. 为了解决这一问题,在保证精确度 的基础上,一些轻量级网络应运而生. 从 2016 年开 始,SqueezeNet[64]、ShuffleNet[65]、NasNet[66]以及 MobileNet[67]、MobileNetV2[68]、MobileNetV3[69]等 轻量级网络模型相继出现,这些轻量级网络的出现 使一些嵌入式设备和移动终端运行神经网络成为可 能,也使神经网络得到更广泛的应用。
自动机器学习(Automatic Machine Learning,AutoML)是针对机器学习领域对机器学习从业者和 所需经费的需求不断增长而提出的一种真正意义上 的自动化机器学习系统. AutoML 代替人工进行自动 的网络模型选取、目标特征选择、网络参数优化和 模型评价. 也就是说,AutoML 可以自动构建具有有 限计算预算的机器学习模型结构. AutoML 通过 2017 年 5 月的 Google I/O 大会进入业界视野并得到 广泛关注. 随着神经网络深度和模型数量的不断增 加,大部分的 AutoML 研究将重点关注在了神经网 络搜索算法(Neural Architecture Search algorithm, NAS),NAS 的开创性工作是 GoogleBrain 于 2016 年同时提出的[70]. 随后 MIT 和 GoogleBrain 又在其 基础上做了一系列的改进工作,加入了强化学习、 基于序列模型的优化、迁移学习等更多合理的逻辑 思路,随之依次出现了 NasNet[66,71]、基于正则化 进化的 NasNet[72]、PNAS[73]和 ENAS[74]等. 贺鑫等 将目前神经网络搜索算法的研究进展进行了详细 总结[75]. Google 推出了 Cloud AutoML 平台,只需 上传你的数据,Google 的 NAS 算法就会为你找到 一个快速简便的架构. AutoML 的出现降低了部分行 业对机器学习尤其是神经网络的使用者的在数量 和知识储备上的要求,进一步拓宽了机器学习和神 经网络的适用范围.
1.2 深度神经网络的主流硬件平台
**随着硬件技术和深度神经网络的发展,目前形 成了以“CPU+GPU”的异构模式服务器为主的深度 神经网络的研究平台,如英伟达的 DGX-2. 其具有 16 块 Tesla V100 GPU,可以提供最高达 2 PFLOPs 的计算能力. 面对复杂的实际应用需求和不断加深 的神经网络结构,多样化的深度神经网络硬件平台 也不断发展起来,形成了以通用性芯片(CPU、 GPU)、半制定化芯片(FPGA)、全制定化芯片 (ASIC)、集成电路芯片(SoC)和类脑芯片等为主 的硬件平台市场. 计算性能、灵活性、易用性、成 本和功耗等成为评价深度神经网络硬件平台的因素 和标准.
1.2.1 GPU
GPU(Graphic Processing Unit)起初专门用于 处理图形任务,主要由控制器、寄存器和逻辑单元 构成. GPU 包含几千个流处理器,可将运算并行化 执行,大幅缩短模型的运算时间. 由于其强大的计 算能力,目前主要被用于处理大规模的计算任务. 英伟达在 2006 年推出了统一计算设备构架 CUDA 及对应的 G80 平台,第一次让 GPU 具有可编程性, 使得 GPU 的流式处理器除了处理图形也具备处理 单精度浮点数的能力. 在深度神经网络中,大多数 计算都是矩阵的线性运算,它涉及大量数据运算, 但控制逻辑简单. 对于这些庞大的计算任务,GPU 的并行处理器表现出极大的优势. 自从 AlexNet[13] 在 2012 年的 ImageNet 比赛中取得优异成绩以来, GPU 被广泛应用于深层神经网络的训练和推理. 大 量依赖 GPU 运算的深度神经网络软件框架(如:TensorFlow、PyTorch、Caffe、Theano 和 Paddle-Paddle 等)的出现极大地降低了 GPU 的使用难度. 因此它 也成为人工智能硬件首选,在云端和终端各种场景 均被率先应用,也是目前应用范围最广、灵活度最 高的 AI 硬件.
1.2.2 FPGA
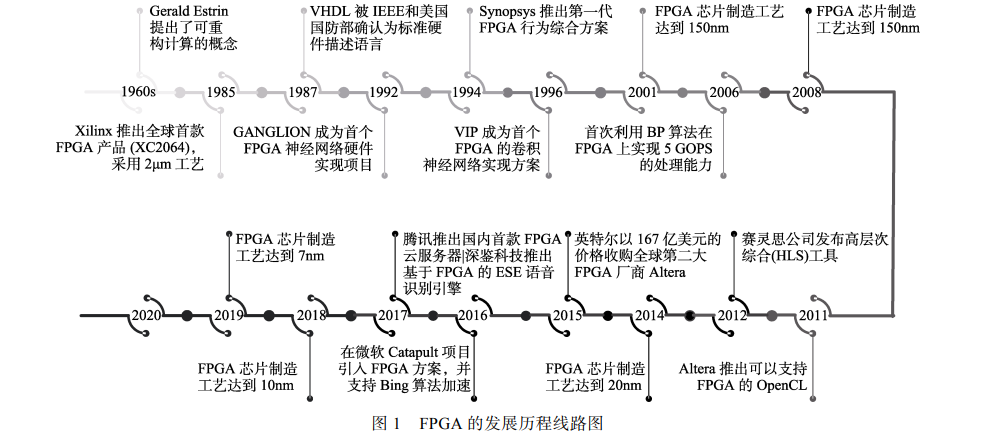
FPGA(Field Programmable Gate Array)是现场 可编程门阵列,它允许无限次的编程,并利用小型 查找表来实现组合逻辑. FPGA 可以定制化硬件流 水线,可以同时处理多个应用或在不同时刻处理不 同应用,具有可编程、高性能、低能耗、高稳定、 可并行和安全性的特点,在通信、航空航天、汽车 电子、工业控制、测试测量等领域取得了很大应用 市场. 人工智能产品中往往是针对一些特定应用场 景而定制的,定制化芯片的适用性明显比通用芯片 的适用性高. FPGA 成本低并且具有较强的可重构 性,可进行无限编程. 因此,在芯片需求量不大或 者算法不稳定的时候,往往使用 FPGA 去实现半定 制的人工智能芯片,这样可以大大降低从算法到芯 片电路的成本. 随着人工智能技术的发展,FPGA 在加速数据处理、神经网络推理、并行计算等方面 表现突出,并在人脸识别、自然语言处理、网络安 全等领域取得了很好的应用.
1.2.3 ASIC
ASIC(Application Specific Integrated Circuit) 是专用集成电路,是指根据特定用户要求和特定电 子系统的需要而设计、制造的集成电路. 相比于同 样工艺 FPGA 实现,ASIC 可以实现 5~10 倍的计算 加速,且量产后 ASIC 的成本会大大降低. 不同于可 编程的 GPU 和 FPGA,ASIC 一旦制造完成将不能 更改,因此具有开发成本高、周期长、门槛高等问 题. 例如近些年类似谷歌的 TPU、寒武纪的 NPU、 地平线的 BPU、英特尔的 Nervana、微软的 DPU、 亚马逊的 Inderentia、百度的 XPU 等芯片,本质上 都属于基于特定应用的人工智能算法的 ASIC 定制. 与通用集成电路相比,由于 ASIC 是专为特定目的 而设计,GoogleBrain 具有体积更小、功耗更低、性能提高、保密性增强等优点,具有很高的商业价值, 特别适合移动终端的消费电子领域的产业应用.
1.2.4 SoC
SoC(System on Chip)是系统级芯片,一般是 将中央处理器、储存器、控制器、软件系统等集成 在单一芯片上,通常是面向特殊用途的指定产品, 如手机 SoC、电视 SoC、汽车 SoC 等. 系统级芯片 能降低开发和生产成本,相比于 ASIC 芯片的开发 周期短,因此更加适合量产商用. 目前,高通、AMD、 ARM、英特尔、英伟达、阿里巴巴等都在致力于 SoC 硬件的研发,产品中集成了人工智能加速引擎,从 而满足市场对人工智能应用的需求. 英特尔旗下子 公司 Movidius 在 2017 年推出了全球第一个配备专 用神经网络计算引擎的 SoC(Myriad X),芯片上集 成了专为高速、低功耗的神经网络而设计的硬件模 块,主要用于加速设备端的深度神经网络推理计算. 赛灵思推出的可编程片上系统(Zynq 系列)是基于 ARM 处理器的 SoC,具有高性能、低功耗、多核和 开发灵活的优势. 华为推出的昇腾 310 是面向计算 场景的人工智能 SoC 芯片.
1.2.5 类脑芯片
类脑芯片(brain-inspired chip)是仿照人类大 脑的信息处理方式,打破了存储和计算分离的架构, 实现数据并行传送、分布式处理的低功耗芯片. 在 基于冯诺依曼结构的计算芯片中,计算模块和存储 模块分离处理从而引入了延时及功耗浪费. 类脑芯 片侧重于仿照人类大脑神经元模型及其信息处理的 机制,利用扁平化的设计结构,从而在降低能耗的 前提下高效地完成计算任务. 在人工智能火热的时 代,各国政府、大学、公司纷纷投入到类脑芯片的 研究当中,其中典型的有 IBM 的 TrueNorth、英特 尔的 Loihi、高通的 Zeroth、清华大学的天机芯等. 目前,深度神经网络芯片正在不断研究开发中, 每种芯片均是针对一定的问题而设计的. 因此,不同 的芯片有其独特的优势和不足. 通过上述对不同芯 片的描述,我们可以了解到相比 GPU,FPGA 具有更 强的计算能力和较低的功耗. 相比 ASIC 和 SoC, FPGA 具有更低的设计成本和灵活的可编程性. 相比 类脑芯片,FPGA 的开发设计更简单. 综合当前深度 神经网络芯片的特性可知,FPGA 的设计性能更适合 应用于深度神经网络在普通领域的开发和应用. 随着 FPGA 在深度神经网络领域的应用,相关 学者对其进行了分析和整理. 文献[76]对基于 FPGA 的卷积神经网络加速过程进行分析总结. 文献[77] 汇总了目前 FPGA 用于卷积神经网络加速的发展研 究现状. 文献[78]对目前 FPGA 用于神经网络的发 展现状进行总结,并提出所面临的问题和挑战. 文 献[79]总结了 FPGA 的设计理论及其用于神经网络 加速的技术原理和实现方法. 文献[80]分别介绍了 人工神经网络和 FPGA 进行介绍的发展,同时总结 了 FPGA 用于人工神经网络的发展和挑战. 本文从 FPGA 应用于深度神经网络的设计原理、型号选择、 应用领域、加速器及具体加速原理、实验评估指标 到最后的 FPGA 应用与深度神经网络的影响因素等 方面进行归纳总结,对 FPGA 用于神经网络加速进 行全面的介绍,为读者提供理论和实践指导.