
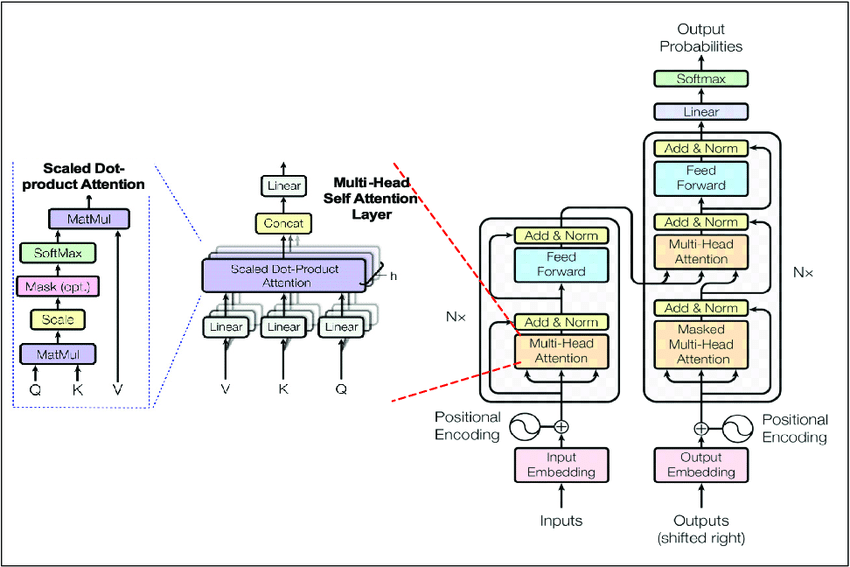
本文包含transformer模型的一些细节,当我第一次尝试从头实现它时,我发现这些细节有点令人困惑。本文并不是对transformer 模型的完整解释,因为在网上已经可以找到大量有用的材料。下面是一些为各种任务实现transformer 模型的示例。
https://github.com/hbchen-one/Transformer-Models-from-Scratch
- 用于文本分类的仅编码器transformer模型
Encoder_only_transformer_AG_News_classification。ipynb开放在协作本笔记本训练了一个简单的只有编码器的transformer 模型,用于在AG News数据集上进行文本分类。该方法很容易达到91.9%左右的精度。
- 经过训练的只有解码器transformer 模型(GPT-like)进行n位数加法
GPT_Addition。ipynb开放在协作同一个模型(只有约28万个参数)分别进行2位、5位、10位和18位的加法训练,2位加法全部正确,只有很小一部分高位数加法错误(18位的测试准确率约为96.6%)。模型给出的错误答案大多相差一两个数字。
- 全transformer模型(编码器+解码器)机器翻译
Transformer_Multi30k_German_to_English。ipynb开放在协作该笔记本在Multi30k数据集上训练了一个大约2600万个参数的transformer模型,在测试集上获得了BLEU 35.5分。这个BLUE分数似乎很高,我认为原因之一是这个数据集中的句子相对简单。Transformer_Chinese_To_English_Translation_news-commentary-v16。ipynb开放在协作这个笔记本电脑在新闻评论v16数据集上训练了一个大约9000万个参数的transformer 。这个笔记本的主要目的是研究模型的性能(测试损失和BLEU分数)如何随着训练集大小的增加而变化。结果显示在本笔记本的最后的情节。


