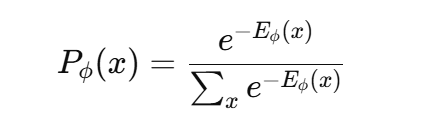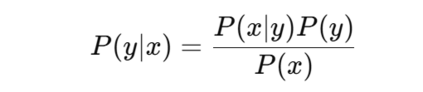视觉-语言模型(Vision-Language Models, VLMs)融合了视觉与文本信息,使图像描述(Image Captioning)和视觉问答(Visual Question Answering)等广泛应用成为可能,因此在现代人工智能系统中具有重要意义。然而,这类模型对计算资源的高度依赖,为实时应用带来了巨大挑战。因此,近年来对于高效视觉-语言模型的研究逐渐成为热点。 在本综述中,我们回顾了用于在边缘设备和资源受限环境中优化VLMs的关键技术,并探讨了紧凑型VLM架构与相关框架。同时,我们还深入分析了高效VLM在性能与内存之间的权衡问题。 此外,我们在 GitHub 上建立了一个开源仓库(https://github.com/MPSC-UMBC/Efficient-Vision-Lang),收录所有被调研的论文,并将持续更新。我们的目标是推动该领域的深入研究。 关键词:高效视觉-语言模型,多模态模型,边缘设备
1 | 引言
视觉-语言模型(Vision-Language Models,VLMs)的出现回应了当前对能够有效处理和整合视觉与文本数据系统的迫切需求。如今,医疗(如医学图像与诊断报告)、自动驾驶系统(如传感器数据与导航指令),以及社交媒体(如配有文字说明的图片)等领域日益丰富的多模态数据凸显出单模态模型的局限性——它们难以将视觉内容与语言语境有机关联。VLMs 通过在统一的表示空间中对齐图像与文本信息,有效应对了这一挑战,从而实现了图像描述、跨模态检索、视觉问答(VQA)、视觉常识推理(VCR)等高级任务。 深度学习架构的持续进步以及大规模多模态数据集的可获取性,进一步推动了 VLMs 的发展。为了更高效地对齐并融合多模态数据,VLMs 利用了多种训练目标,其中对比学习、掩码建模和生成建模起到了关键作用。 在基于对比学习的VLM中,模型目标是对匹配的数据对赋予较低的能量值(energy),而对不匹配的数据对施加较高能量惩罚。所学习的能量函数 Eϕ(x)E_\phi(x)Eϕ(x) 通过玻尔兹曼公式将数据样本映射为概率分布:
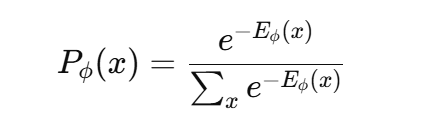
这一公式确保了能量值越低的样本,其对应的概率越高。优化目标是使模型分布 Pϕ(x)P_\phi(x)Pϕ(x) 尽可能接近目标分布 PT(x)P_T(x)PT(x)。这种优化常使用最大似然估计,通过正负样本计算梯度,其中负样本通常通过马尔可夫链蒙特卡洛(MCMC)等方法生成。CLIP(Radford 等, 2021)与 SigLIP(Zhai 等, 2023)等模型展示了对比学习在将视觉与文本嵌入对齐方面的有效性,使模型在多模态任务中表现稳健。 掩码建模则采用另一种思路:通过对输入进行部分遮蔽并训练模型预测被遮蔽的部分。例如,掩码语言建模(MLM)依托 Transformer 架构,随机丢弃输入 token 并进行预测;而掩码图像建模(MIM)在视觉数据中应用相同原理。FLAVA(Singh 等, 2022)与 BEiT(Bao 等, 2021)等框架成功利用掩码建模策略,在大规模多模态数据集上进行预训练。 相比之下,生成式模型通过同时学习对比损失与生成损失,进一步扩展了 VLMs 的能力。这类模型广泛用于图像描述任务。例如,CM3Leon(Yu 等, 2023b)采用独立的图像与文本 tokenizer,将不同模态的输入转换为 token 序列,随后由 Transformer 解码器处理。而 Chameleon(Team, 2024)则进一步统一设计,采用相同的 Transformer 模型处理图像与文本 token,以提高效率与一致性。除了图像描述,生成式模型还可应用于多种下游任务,例如利用贝叶斯公式进行图像分类:
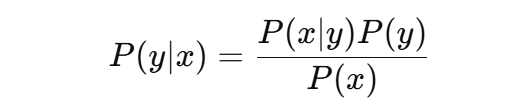
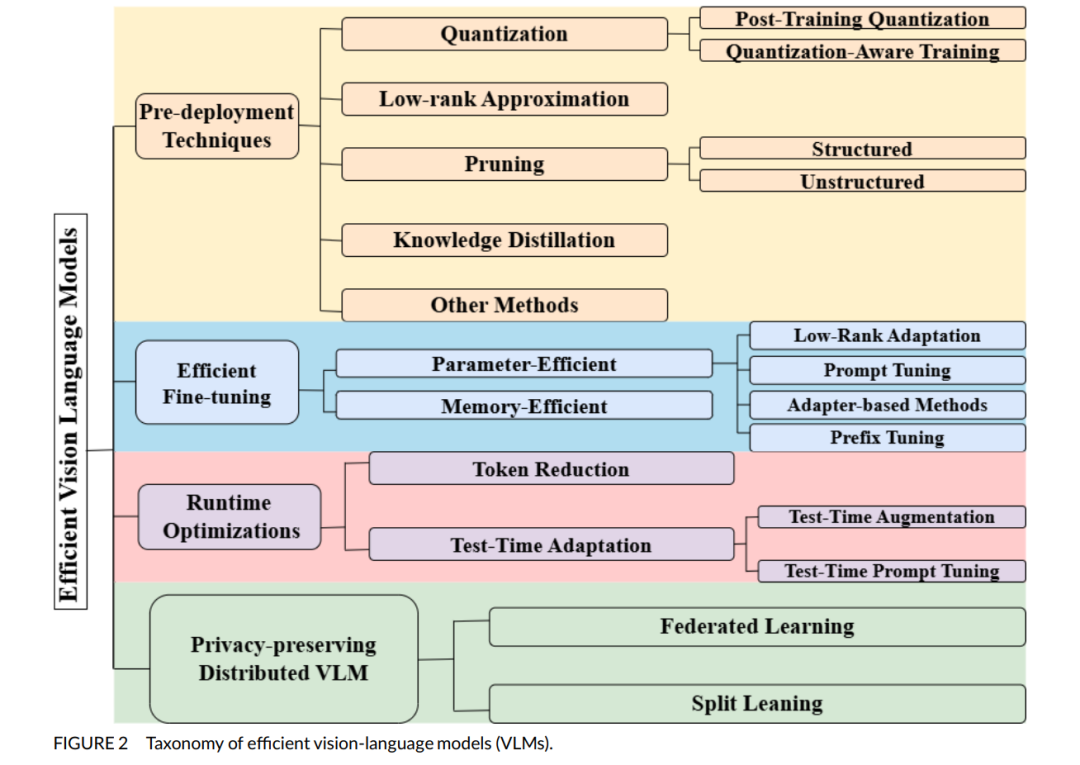
为节省计算资源并降低训练成本,VLMs 通常集成预训练的模型骨干(backbone),例如 Frozen(Tsimpoukelli 等, 2021)、MiniGPT(Zhu 等, 2023)或 Qwen 系列(Qwen 等, 2024)。这些预训练组件可加快收敛速度并具备较好的任务泛化能力。VLM 的预训练架构也存在差异,从图像与文本分别编码的双塔模型(Two-Tower)到使用统一网络生成联合嵌入的一体化模型(One-Tower),都在提升效率的同时增强了对边缘设备的适配性。 将 VLMs 部署于资源受限设备(如边缘计算终端)可有效满足实时处理与隐私保护的需求,使推理过程可在本地完成。同时,边缘部署也可在网络连接有限或不稳定的环境中实现稳定性能,使 VLMs 在自动导航与智能物联网系统中表现出高度适应性(见图1)。 然而,随着最先进 VLMs 为追求更高性能而不断扩展,其模型体积与推理延迟显著上升。例如,CLIP-B/16(Liu, 2024)模型的图像编码器参数量达 8620 万,文本编码器达 6340 万,使其难以部署于 Jetson Nano(4 GB RAM,无独立 GPU)或 Jetson Xavier(8 GB RAM,1 个 GPU)等边缘设备。在 Jetson Nano 上,有限的内存会导致频繁的内存交换,严重影响延迟与吞吐量;而即使是 Jetson Xavier,其 GPU 也可能无法实时满足模型的计算需求。这些限制凸显了开发内存占用低、延迟低且性能竞争力强的高效 VLMs 的迫切性。 本综述的主要贡献如下: 1. 系统总结了在资源受限设备上提升 VLM 效率的多种技术,包括部署前优化、精调策略与运行时优化方法; 1. 汇总了当前最具代表性的轻量化 VLM 模型及其配套框架; 1. 基于上述技术,深入分析了 VLM 性能与内存占用之间的权衡关系。
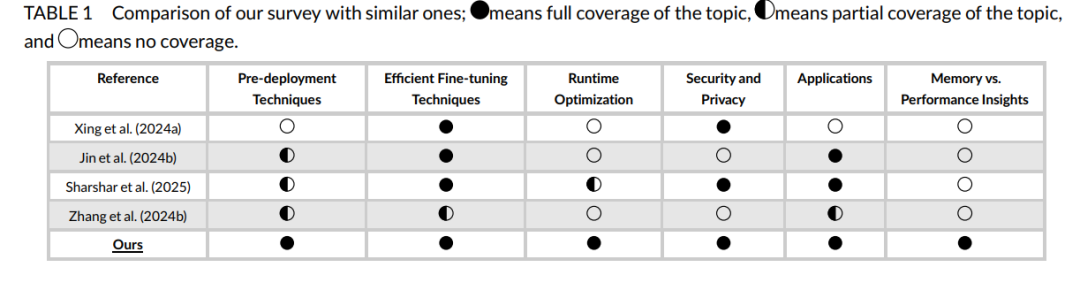
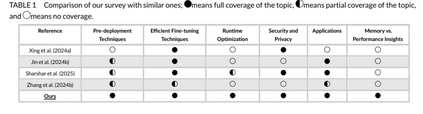
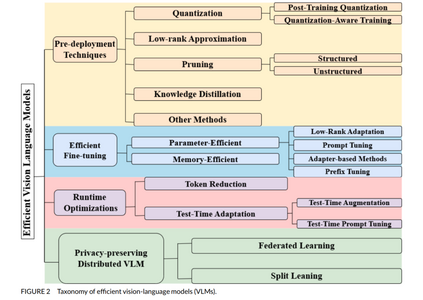
本综述按照图2中的分类体系展开。与现有综述(如 Ghosh 等, 2024)主要聚焦 VLM 架构,Du 等 (2022) 针对视觉语言预训练模型(VL-PTMs),以及 Zhang 等 (2024a) 探讨知识蒸馏与迁移学习等技术不同,我们则聚焦于面向边缘与资源受限设备的高效 VLMs 设计,并提供深入分析。表1对比了本综述与其他综述的差异。 为了保证综述的全面性,我们从 Google Scholar、DBLP 与 ResearchGate 等平台广泛检索顶级会议与研讨会论文,检索关键词包括 “VLM quantization”、“VLM pruning”、“VLM finetuning techniques”、“VLM knowledge distillation”、“VLM runtime optimizations”,以确保对该快速发展的研究领域进行有针对性的深入探讨。 本文接下来的结构如下:第2节介绍部署前优化技术;第3与第4节分别探讨精调策略与运行时优化方法;第5节涉及分布式 VLMs;第6节总结当前高效 VLM 模型及其配套框架与库;第7节分析准确率与效率的权衡问题;第8节探讨典型应用场景;第9节讨论当前挑战与未来研究方向;最后在第10节进行总结。 我们还创建了一个 GitHub 仓库,收录本综述中提及的所有论文,并将持续维护更新以涵盖新兴研究:https://github.com/MPSC-UMBC/Efficient-V