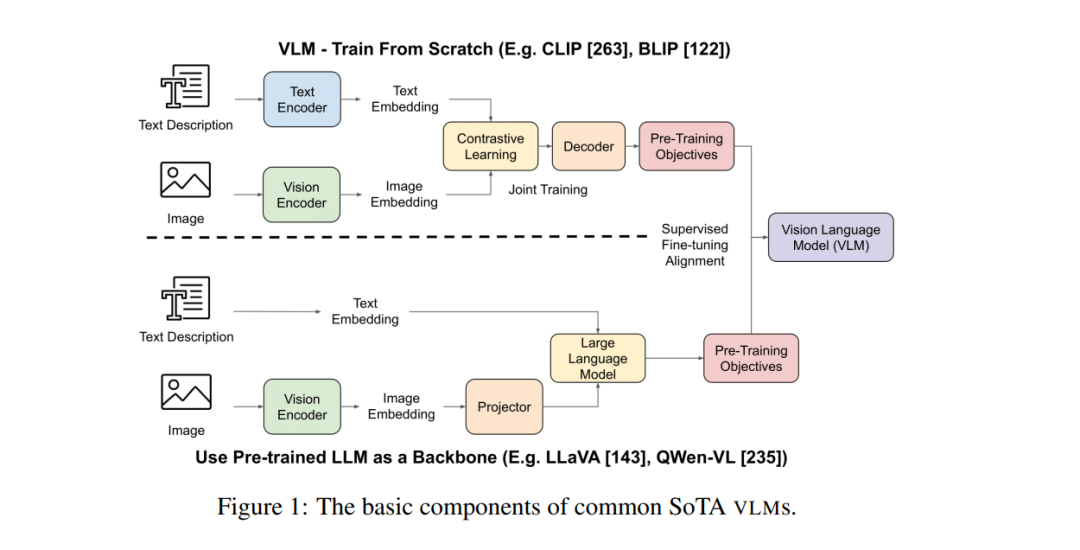
多模态视觉语言模型(VLMs)作为一种变革性技术,出现在计算机视觉与自然语言处理的交叉领域,使得机器能够通过视觉和文本两种模态感知和推理世界。例如,像CLIP [213]、Claude [10] 和 GPT-4V [276] 等模型,在视觉和文本数据上展示了强大的推理和理解能力,并在零-shot 分类任务中超过了传统的单模态视觉模型 [108]。尽管在研究中的快速进展和在应用中的日益普及,关于VLM的现有研究的综合综述仍然显著缺乏,特别是对于那些希望在特定领域利用VLM的研究者。为此,我们在以下几个方面提供了VLM的系统性概述:[1] 过去五年(2019-2024)中开发的主要VLM模型的信息;[2] 这些VLM的主要架构和训练方法;[3] 对VLM的流行基准和评估指标的总结和分类;[4] VLM的应用,包括具身智能体、机器人技术和视频生成;[5] 当前VLM面临的挑战和问题,如幻觉、 fairness(公平性)和安全性。详细的文献和模型库链接收集可见于 https://github.com/zli12321/Awesome-VLM-Papers-And-Models.git。 预训练的大型语言模型(LLMs),如LLaMA [237] 和 GPT-4 [199],在广泛的自然语言处理(NLP)任务中取得了显著成功 [173, 184]。然而,随着这些模型的不断扩展 [191],它们面临着两个挑战:(1)高质量文本数据的有限供应 [241, 142];(2)单一模态架构在捕捉和处理需要理解不同模态之间复杂关系的现实世界信息时的固有限制 [73, 95]。这些局限性促使了对视觉语言模型(VLMs)的探索和开发,VLM结合了视觉(例如图像、视频)和文本输入,提供了更全面的理解,能够理解视觉空间关系、物体、场景和抽象概念 [22, 85]。VLM突破了此前单模态方法的表示边界,支持了更丰富、更加具有上下文信息的世界观 [59, 244, 168],例如视觉问答(VQA)[4]、自动驾驶 [235]。与此同时,VLM遇到了与单模态模型不同的新挑战,例如视觉幻觉,当VLM生成响应时,没有进行有意义的视觉理解,而是主要依赖存储在LLM组件中的参数知识 [76, 152]。目前已经有若干关于单模态模型的综述 [190, 30],但多模态模型的综述仍然缺乏。在本文中,我们对VLM的研究成果进行了批判性审视,系统地回顾了当前主要的VLM架构、评估与基准、应用以及VLM面临的挑战。