

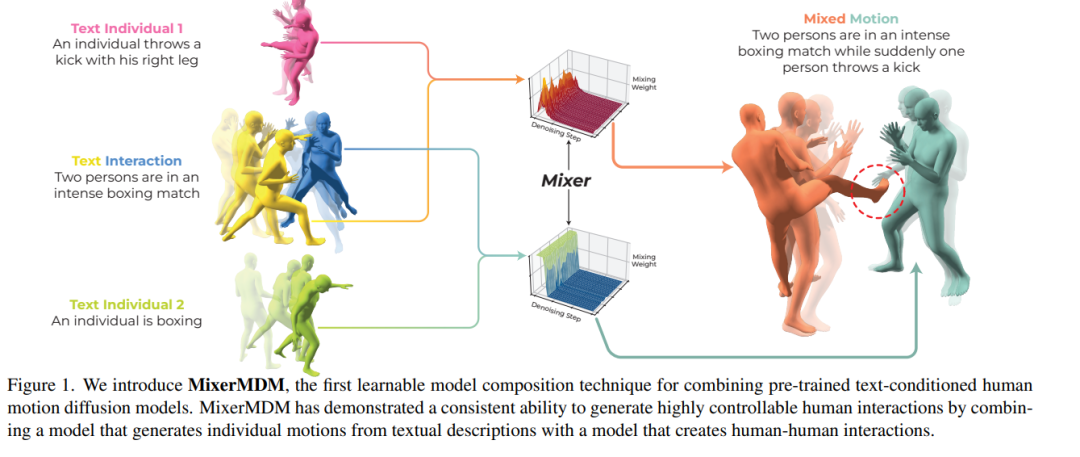
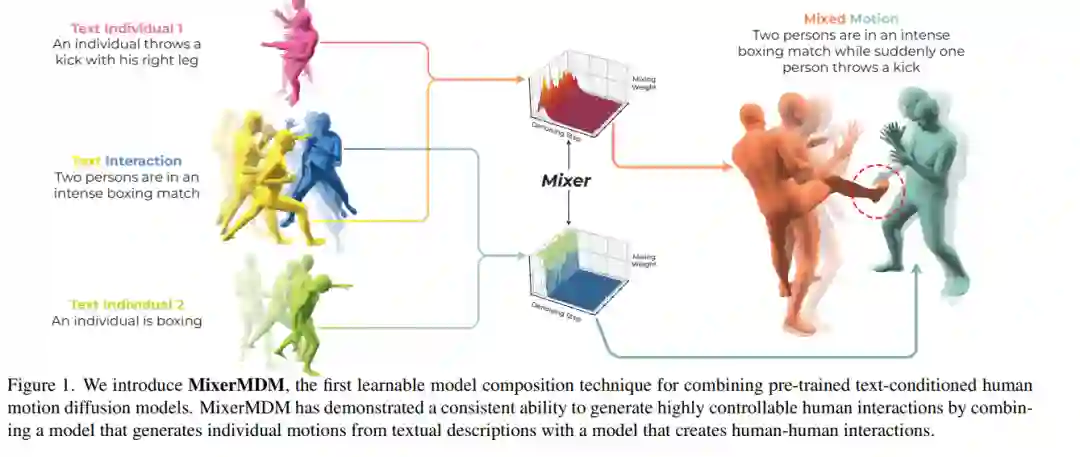
生成由条件(如文本描述)指导的人体运动是一项具有挑战性的任务,因为它需要具有高质量运动及其对应条件的配对数据集。当目标是实现更精细的生成控制时,困难会进一步增加。为此,先前的工作提出了结合多个在不同条件数据集上预训练的运动扩散模型,从而实现对多个条件的控制。然而,现有的合并策略忽视了生成过程的最佳组合方式可能依赖于每个预训练生成模型的特性以及具体的文本描述。在这种背景下,我们提出了 MixerMDM,这是第一个可学习的模型组合技术,用于结合预训练的文本条件人体运动扩散模型。与先前的方法不同,MixerMDM 提供了一种动态混合策略,该策略通过对抗训练的方式学习根据驱动生成的条件集来结合每个模型的去噪过程。通过使用 MixerMDM 结合单人和多人运动扩散模型,我们能够对每个人的动态进行精细控制,并且也能控制整体的交互过程。此外,我们提出了一种新的评估技术,首次在该任务中通过计算混合生成运动与其条件之间的对齐程度,来衡量交互性和个体质量,并评估 MixerMDM 在去噪过程中根据要混合的运动调整混合的能力。
成为VIP会员查看完整内容

相关内容
Arxiv
42+阅读 · 2023年4月19日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日