摘要
在全球化和合作日益加强的时代,政府通过互联网提供法律信息,使所有感兴趣的人有可能获得这些信息,这一点越来越重要。随着时间的推移,不同国家的法律信息系统在可用数据、格式和可访问性方面有不同的发展。这导致了更复杂的法律信息搜索过程,特别是当涉及到来自不同国家的法律信息,从而也涉及到不同的法律信息系统。特别是,来自不同国家的法律信息的跨国界相互联系是缺失的。为了克服这些问题,欧盟提出了促进法律信息更容易获取和相互连接的建议。这些建议的目标是利用独特的标识符和注释,以标准化和机器可读的方式提供法律信息。语义技术使我们能够将法律信息表现为 "知识图谱",它将法律数据连接起来,并实现结构化查询。在这篇论文中,我们研究了为奥地利法律系统创建和查询法律知识图谱的可能性。建议的法律知识图谱是根据奥地利法律信息系统中的数据创建的,并根据欧盟的建议进行建模。此外,我们还分析了来自其他国家的可用链接法律数据,以及这些数据如何被整合。我们展示并比较了以理想的自动化方式填充拟议的法律知识图谱的不同方法。最后,我们展示了拟议中的法律知识图谱是如何用来自不同国家的法律数据来填充的,以增强法律信息搜索的可能性,从而回答搜索查询,这在目前是不可能的。
第一章 简介
在我们的日常生活中,能够获取法律信息是一个非常重要的方面,因为 "法律 "无处不在,例如,当我们在超市买东西或参与交通时。一项在101个国家进行的、每个国家有1000名参与者的研究[世界正义项目,2019]显示,在2015年至2017年期间,全球约有一半的参与者面临法律挑战。奥地利更详细的数字显示,只有三分之二的参与者知道在哪里可以找到法律信息。这些数字表明,对于剩下的三分之一的人来说,获取法律信息的途径需要改进,并使之更容易。
我们所说的 "法律信息 "到底是什么意思?法律信息可以出现在不同的方面,例如,作为规定义务或禁止的法律。更广泛地说,我们可以将法律定义为管理我们日常生活的规则框架。法律信息也可以包含在法院的判决中,这些判决也被用来解释和完善法律。通常情况下,法律信息包含在文件中,这就是为什么我们也称它们为法律文件。这种文件可以是,例如,法律和法院判决,但也可以是个人之间的合同,其中包括受影响的当局的具体信息或对其他法律文件的引用。我们把这些特定的词的序列称为法律实体。此外,法律文件还可以包括时间表达,这些表达可以与法律实体相结合,以表示法律事件并描述何时发生。
与以前不同的是,以前为了遵守法律出版的要求,法律的修改只在官方公告牌上打印公布,现在我们可以使用法律信息系统。法律信息系统被用来支持搜索和寻找解决法律问题所需的信息[van Opijnen and Santos, 2017]。例如,这样的法律信息系统是由联邦数字和经济事务部(BMDW)提供的奥地利Rechtsinformationssystem des Bundes(RIS),该系统可以在网上获得,并且可以免费访问。RIS提供了一个基于关键词的搜索界面,允许用户在不同种类的文件中进行搜索,例如法律或法院判决。可以使用额外的过滤器来限制搜索,例如搜索文件的特定出版日期。搜索结果以长长的结果列表形式呈现,要求用户浏览所有的单个文件,并检查它们是否包含所需的信息。此外,这些文件只有部分的相互联系,例如,法院判决中的法律参考文献没有与实际的法律文件相联系。这就要求用户在RIS法律栏目中为每个法律参考文献进行额外的法律搜索。因此,文件中缺失的链接降低了可操作性,并使搜索过程变得复杂,因为它是一个不必要的繁琐和耗时的过程。此外,搜索的可能性往往受到现有元数据的限制,这意味着实际文件中包含的信息,例如法律实体,并不能用于搜索过程。当需要来自欧盟或外国的法律资源来解决一个法律问题时,情况就更糟糕了。在这种情况下,需要参考外国的法律信息系统,而这些系统可能以完全不同的方式组织。
因此,缺失链接的问题可以通过增加文件之间的链接来解决。此外,信息提取方法可用于提取法律文件中包含的额外信息,例如法律实体,以补充现有的元数据并使其可用于搜索过程。为此,可以使用资源描述框架(RDF)[W3C工作组,2014]这种机器可读的数据格式来链接法律数据,以实现结构化查询和更容易地浏览相互链接的法律文件。2011年,欧盟开始为解决这些问题做出努力,提出了一些标准,这些标准应该有助于在欧盟成员国之间基于RDF的法律信息的相互连接。用于立法文件的欧洲法律标识符(ELI)和用于司法文件的欧洲判例法标识符(ECLI)已由欧盟理事会提出。ELI和ECLI都为法律文件分配了唯一的标识符,并描述了一套最低限度的元数据。对欧盟成员国来说,拟议标准的实施不是强制性的,这可能是吸收缓慢的原因。在ELI和ECLI提出的过去几年中,一些欧盟成员国至少为其法律文件分配了标识符,而其他成员国则没有表现出参与这些倡议的兴趣。
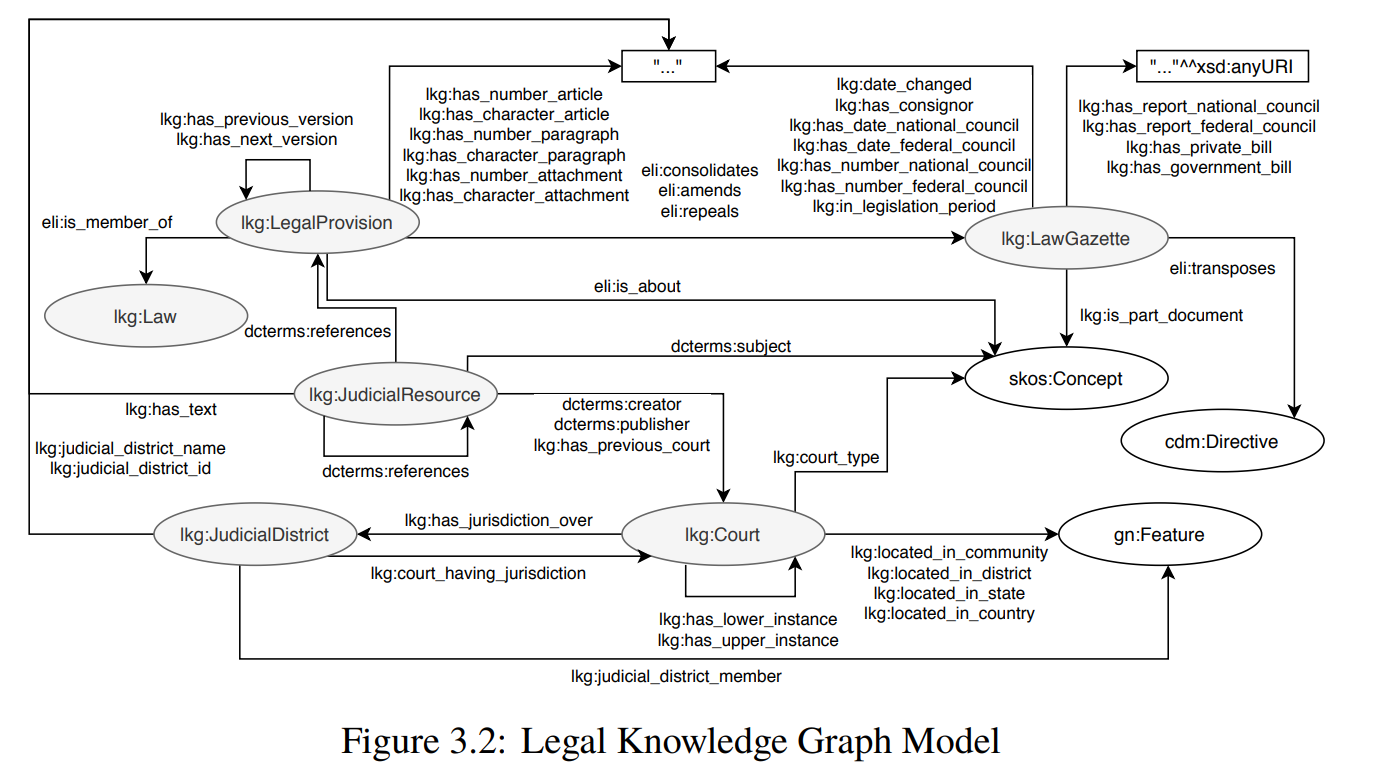
奥地利是欧盟成员国之一,在第一步中,ELI和ECLI标识符(而且只有标识符)已经被分配给RIS文件。这意味着,我们可以把目前的状态作为一个起点,克服上述搜索过程中的缺点。此外,我们还可以在已经采取的努力基础上,参与ELI和ECLI。此外,ELI和ECLI还提供了必要的灵活性,通过用奥地利法律体系特有的类和属性来扩展ELI和ECLI本体,以适应特定的国家要求。因此,一个能够代表相关信息的法律知识图谱,例如与其他法律文件的链接或根据分类模式归入同一类别的文件,能够增强搜索能力。此外,从法律文件中提取的信息可用于将实体链接到外部知识库,如Geonames或DBpedia,这也增强了法律信息搜索。此外,通过整合其他国家和欧盟的法律数据,它还支持跨法域的搜索请求。我们为ELI和ECLI的目标做出了贡献,这些目标旨在为整个欧洲的法律信息提供更便捷的访问和相互链接,而这只有在各成员国参与并使用同一系统时才能成功。从实用的角度来看,这将使我们能够实现更复杂的搜索查询,这些查询要么需要复杂的搜索过程,要么在目前的系统中根本无法回答,比如下面的问题(Q),将在第三章中详细解释。
问题1 在一个具体的法院判决中引用了哪些文件?
问题2 法院对哪些地区有管辖权?
问题3 某一特定欧盟指令的国家转换是什么?
问题4 用外语的关键词搜索,哪些法律文件规定了特定的法律领域?
问题5 法院判决中提到了哪些事件,可以用来快速了解案件的情况?
事实上,由法律专家进行的法律搜索过程涉及回答这样的问题及其组合。任何对这些问题的回答和部分自动处理的支持,都将使这些搜索任务对法律专业人士来说更加有效。
以前关于处理法律信息以支持各种任务的研究已经在不同的科学领域进行。计算法的法律信息学领域着眼于 "法律分析的机械化"[Genesereth, 2018],将规则和事实在逻辑表达方面的形式化与推理相结合,从而得出结果。20世纪80年代,人工智能(AI)开始被应用于法律领域,以支持解决法律问题,例如在法律推理方面[v. d. L. Gardner, 1983]。后来,法律领域的另一个工作领域集中在表示法律信息的数据格式上,如Metalex[Boer等人,2002]和Akoma-Ntoso[Palmirani和Vitali,2011],都是用于描述法律文件结构和内容的XML(可扩展标记语言)标准。与此同时,关于法律本体的工作也开始了,目标是实现法律信息的交换,例如法律知识交换格式(LKIF)[Hoekstra等人,2007]和法律领域的特定本体,例如隐私政策的本体[Oltramari等人,2018,Palmirani等人,2018],以描述法律领域的一个子集或问题。法律领域的自然语言处理这一新兴领域始于基于模板的法律文件中的人物提取[Dozier和Haschart, 2000]。随着时间的推移,这项工作在提取不同种类的实体和法律文件的分类方面得到了扩展,从使用基于规则的方法到机器学习,最后到深度学习方法[Dozier等人,2010,Cardellino等人,2017a,Chalkidis等人,2019,Leitner等人,2019,Tuggener等人,2020] 。然而,以前这些努力的重点是法律文件的内容,而不是它们之间的联系。只有在最近几年,我们才能看到向连接国家法律数据转变的小迹象。希腊的Diavgeia项目旨在通过强迫当局通过网络提供他们的文件来增加法律信息的可及性,从中可以创建链接的法律数据[Chalkidis等人,2017]。使用ELI和ECLI为芬兰立法和案例法发布RDF的类似工作是Finlex数据库[Oksanen等人,2019]。
因此,有必要建立链接的法律信息,使专业和非专业用户能够通过在法律知识图谱(LKG)中相互链接本国和外国的法律文件来搜索和浏览法律信息。基于所有欧盟成员国使用的共同本体,用图结构表示法律信息,有助于我们简化法律信息的获取,并支持跨边界的搜索。
1.1 假设和研究问题
在创建奥地利法律知识图谱的明确动机下,在努力实现链接法律数据的基础上,本文提出的工作由以下总体假设指导:
- “法律知识图谱可用于将国内和国际来源的法律文件联系起来,从而增强法律信息的搜索过程,扩大搜索的可能性,这在目前使用传统的法律信息系统是不可能的。”
从这个假设中,我们可以得出以下具体的研究问题(RQ):
研究问题1 为了从现有的法律信息系统中构建一个法律知识图谱,需要什么?
为了回答这个研究问题,我们想知道,为了将传统法律信息系统中的数据转化为知识图谱,我们可以使用哪些要求和预先存在的构建模块。此外,我们需要将现有的数据与现有的本体结合起来,这些本体需要被扩展以支持国家的要求。奥地利的法律体系被嵌入到欧洲体系中,并与其他国家的法律体系相互影响,这就是为什么ELI和ECLI作为我们法律知识图谱的基础。
研究问题2 为了以自动化的方式从不同的数据源填充法律知识图谱,可以采取哪些方法?
奥地利法律信息系统中的数据可以被转移到法律知识图谱中。因此,我们需要找到方法来实现从不同的数据源进行填充。我们有必要分析来自RIS的可用数据(元数据和文件),并将其与我们需要填充的本体的属性进行比较。我们可以衍生出三个子研究问题:
研究问题 2.1 哪些方法可用于从结构化数据中获取法律知识图谱,它们的效果如何?
为了回答这个研究问题,我们需要分析哪些信息是由RIS提供的结构化格式的元数据,并研究使用这些信息来填充法律知识图谱的方法。
研究问题2.2 哪些方法可用于从文本来源(即法律文件)中获取法律知识图谱,它们的效果如何?
为了回答这个研究问题,我们需要研究哪些ELI和ECLI属性不能从RIS元数据中填充,而是从法律文件中的信息中填充。我们将分析和比较不同的方法来从文件中提取法律实体。此外,我们还将研究允许我们将法律文件归类到一组给定类别的方法。
研究问题2.3 哪些方法可用于从法律文件中提取事件,它们的效果如何?
为了回答这个研究问题,我们需要调查法律文件中包含的事件。此外,我们有必要分析各个事件的组成部分,并比较不同的提取方法对这些组成部分的性能。
研究问题3 在多大程度上有可能通过链接法律数据来提高法律查询和搜索过程?
为了找到这个研究问题的答案,我们需要分析当前的法律信息搜索过程,为此我们使用了上述的样本问题。我们调查我们是否可以利用增加的链接和增强的元数据进行增强的搜索查询,以回答样本问题。
1.2 贡献
本论文的贡献可以概括为以下几点:
-
对问题1的贡献:我们分析了拟议的ELI和ECLI本体,以及它们在涉及奥地利法律数据时的适用性,并在必要时扩展本体。特别是,我们描述了法律知识图谱的创建方法,并用类和属性来扩展ELI和ECLI本体,以表示奥地利法律信息系统中的数据。此外,我们引入了一个新的词库,包含了奥地利法律语言和信息中使用的特定术语,其中ELI和ECLI本体规定了国家扩展,例如文件分类方案或国家特定的文件类型。
-
对问题2.1的贡献:对于奥地利的法律知识图谱,我们根据RIS提供的可用元数据,提出了三种不同的人口方法。特别是,我们为法律知识图谱的人口提出了三种方法。(i)允许直接转移数据的方法,只需要最低限度的预处理工作;(ii)基于附加条件和查询的方法;(iii)将RIS数据与外部知识库相互链接的方法。
-
对问题2.2的贡献:我们提出了基于NLP工具和技术的群体方法:(i)从文件中提取信息;(ii)使用文件内容将这些文件分类到一个给定的术语库中。对于这两项任务,我们使用了已经成功应用于其他领域文件的最先进的方法,我们根据包含法律文件的数据集对其性能进行了比较和评估。更详细地说,我们提供了一个包含50个手动注释的奥地利最高法院判决的新语料库,它被用于法律实体提取实验。分类方法的性能在包含欧盟法律文件的黄金标准数据集上进行了评估。
-
对问题2.3的贡献:我们确定了在法院判决中提取时间性表达的问题。此外,我们提出了三个时间维度,可以沿着这些维度对法院判决中的时间表达进行分类。我们提供了一个新的黄金标准语料库,其中有30个人工注释的法院判决的时间性注释,分别来自欧洲法院、欧洲人权法院和美国最高法院的10份文件。我们使用这个语料库来比较和讨论十个最先进的、但不针对法律领域的时间标记器的特征和性能。我们对这些通用时间标记器的最常见的错误和问题进行了概述。从法院判决中提取法律事件有助于快速了解一个案件的概况。我们介绍了两种不同类型的事件,并定义了事件组件以进一步分割事件中包含的信息。我们提供了另一个人工注释的黄金标准语料库,其中有30个来自欧洲人权法院的法院判决,并附有法律事件的注释。这个语料库被用来提取法院判决中的事件并进行分类。对于这两项任务,我们分析了最先进的事件提取方法的性能。
-
对问题3的贡献:我们对所有欧盟成员国的法律信息系统和搜索可能性的现状进行了比较。我们分析了法律数据的可用性以及ELI和ECLI的实施状况,使用的数据格式和附加信息。我们还从更普遍的角度描述了所有欧盟成员国的法律数据库的访问和特点,用于传播法律文件的文件格式,以及以何种语言提供法律信息。我们描述了基于ELI和ECLI的非政府努力,以提供链接的法律数据,并根据它们的特点进行分类。我们通过展示由实际的法律搜索用例驱动的查询来证明链接法律数据的好处,这在法律知识图谱中是可能的,但在包括其他国家的综合法律数据之前是不可能的。
1.3 论文结构
本论文的其余部分结构如下。
第二章介绍了与知识图谱、语义网、关联数据有关的背景信息,并介绍了论文中所使用的法律本体和术语表。此外,它还包括对自然语言处理(NLP)和语言模型的介绍,以及常用的NLP任务、方法和工具。
第三章描述了传统法律信息系统所面临的挑战,以奥地利的RIS为例,介绍了创建法律知识图谱的衍生要求。本章还介绍了创建方法,最后介绍了法律知识图谱本体论(LKG),其中包含了新的类别和属性,以正确表示奥地利的法律体系。
第四章介绍了使用自然语言处理工具和技术从各种数据源中获取不同的知识图谱的方法。特别是,我们描述了从法律文件中提取实体和将文件分类为大量不相干的类。我们进行了实验,并对这两项任务的结果进行了比较和讨论。
第五章集中讨论了法律文件中的时间信息,特别是法院判决。我们描述了从法院判决中提取时间信息的挑战,并介绍了不同的时间维度。此外,我们比较了10个非领域特定的时间标记器在检测时间信息方面的表现。此外,时间信息也是可以从法院判决中提取的事件的一部分,并以时间轴的形式呈现。我们比较了从法院判决中提取法律事件的不同方法,并讨论了它们的性能。
第六章介绍并比较了其他欧洲国家在(链接)法律数据方面的举措。一个概述显示了哪些国家参与了欧盟驱动的倡议或决定走另一条路。此外,本章还介绍了在链接法律数据领域的非政府倡议。最后,我们介绍了链接法律数据的好处,并为考虑提供链接法律数据或创建法律知识图谱的利益相关者提出了一个链接法律知识图谱的路线图。
第七章总结了本论文的发现,回答了研究问题并讨论了未来的研究方向。
1.4 出版物和影响
本论文介绍的内容已经在不同的同行评议的国际会议和期刊上提出和发表,包含了来自(按时间顺序)的材料。
- Erwin Filtz, Sabrina Kirrane, Axel Polleres, and Gerhard Wohlgenannt. 利用Eurovoc的分层结构对法律文件进行分类。在迈向有意义的互联网系统。OTM 2019年会议--联邦国际会议。CoopIS, ODBASE, C&TC 2019, Rhodes, Greece, October 21-25, 2019, Proceedings, Volume 11877 of Lecture Notes in Computer Science, pages 164-181. Springer,2019年。[Filtz等人,2019年]
在本文中,我们比较了各种可用于在多标签分类设置中对法律文件进行分类的方法,这些方法使用的是带有欧盟发布的法律文件的语料。我们将结果与分类任务中使用的来自新闻领域的知名数据集进行对比。在论文中,这项工作将在第4.3节中介绍。这项工作的延伸表明,通过使用转化器模型可以提高结果[Shaheen等人, 2020]。
该出版物对RQ2.2有所贡献。
- María Navas-Loro, Erwin Filtz, Víctor Rodríguez-Doncel, Axel Polleres和Sabrina Kirrane. TempCourt: 在一个新的法院判决语料库上评估时间标签器。The Knowledge Engineering Review, 34:e24, 2019. doi:10.1017/S0269888919000195. [Navas-Loro et al., 2019].
这项工作的重点是法院判决中包含的时间信息,并比较了10个非领域特定的时间标记器的性能。为了评估这些标记器的性能,我们创建了一个来自三个不同法院的手工注释的黄金标准语料库。这项工作将在第5.1节中介绍。
本出版物对RQ2.3有所贡献。
- Erwin Filtz, María Navas-Loro, Cristiana Santos, Axel Polleres, and Sabrina Kirrane. 事件很重要。从法院判决中提取事件。法律知识和信息系统 - JURIX 2020: 第三十三届年会,捷克共和国布尔诺,2020年12月9-11日,《人工智能及应用前沿》第334卷,第33-42页。IOS出版社,2020年。[Filtz等人, 2020]
在这篇文章中,我们介绍了法院判决中常见的两种不同类型的事件,并比较了不同的先进的事件提取方法。此外,我们还提取了三个事件组件来描述一个事件,这使得我们能够创建一个时间线来提供一个法院判决的快速概览。这项工作的内容将在第5.2节中介绍。
本出版物对RQ2.3有所贡献。
- Erwin Filtz, Sabrina Kirrane, and Axel Polleres. 链接的法律数据景观:链接不同国家的法律数据。人工智能与法律》,第1-55页。[Filtz等人,2021年] 。
在本文中,我们描述了基于奥地利法律信息系统的法律知识图谱的奥地利用例,并涵盖了从建模到整合其他国家的法律数据的所有主题。本文的背景信息在第二章中涉及。第三章介绍了挑战和要求,以及建模部分的描述。第四章介绍了人口方法的描述。最后,第六章讨论了法律数据的整合。
本出版物对研究问题1、2.1、2.2和3有所贡献。
以下是作者已经发表的其他作品,与本文介绍的工作部分相关,同时对本论文介绍的内容没有直接贡献:
-
Erwin Filtz. 构建和处理法律数据的知识图谱。The Semantic Web - 14th International Conference, ESWC 2017, Portoroû, Slovenia, May 28 - June 1, 2017, Proceedings, Part II, Volume 10250 of Lecture Notes in Computer Science, pages 184-194, 2017. [Filtz, 2017]
-
Erwin Filtz, Sabrina Kirrane, and Axel Polleres. 法律数据的相互联系。与第14届国际语义系统会议同地举行的第14届国际语义系统会议(SEMANTiCS 2018)的海报和演示论文集,奥地利维也纳,2018年9月10-13日。,《CEUR研讨会论文集》第2198卷。CEUR-WS.org,2018。[Filtz et al., 2018]
-
Martin Beno, Erwin Filtz, Sabrina Kirrane, and Axel Polleres. Doc2rdfa: 网络文档的语义注释。第15届国际语义系统会议海报和演示论文集(SEMANTiCS 2019),德国卡尔斯鲁厄,2019年9月9日至12日。,CEUR研讨会论文集第2451卷。CEUR-WS.org,2019年。[Filtz et al., 2019]
-
Zein Shaheen, Gerhard Wohlgenannt和Erwin Filtz. 使用转化器模型的大规模法律文本分类。SEMAPRO 2020第十四届语义处理进展国际会议,法国尼斯,2020年10月25-29日,第7-17页,IARIA 2020。[Shaheen et al., 2020]