漆桂林 | 知识图谱的应用
本文作者为东南大学漆桂林老师,首发于知乎专栏知识图谱和智能问答
前面一篇文章“知识图谱之语义网络篇”已经提到了知识图谱的发展历史,回顾一下有以下几点:
1. 知识图谱是一种语义网络,即一个具有图结构的知识库,这里图的节点可以是概念(比如说大学),可以是实例(比如说东南大学),可以是一个literal(比如说一个数字,一个日期,一个字符串),而图的边就是一个关系(比如说漆桂林 就职于 东南大学,这里“就职于”就是一个关系)。
2. 语义网络的表达能力还是很强的,即一阶谓词逻辑可以表达的知识都可以用语义网络来表达。
3. 语义网络可以有逻辑推理能力,而推理可以通过规则来实现,也可以通过父子节点的继承实现。
那么,知识图谱到底有些什么用呢?知识图谱比较适合需要建立数据关联和需要从非结构化数据中转化出结构化数据的场景。下面是几个应用场景(还会持续更新,也欢迎提意见)。
一、语义搜索
知识图谱这个概念是谷歌提出的,谷歌做知识图谱自然是跟搜索引擎相关,即提供语义搜索。这里语义搜索跟传统搜索引擎的区别在于搜索的结果不是展示网页,而是展示结构化知识,如下图(图1)所示:
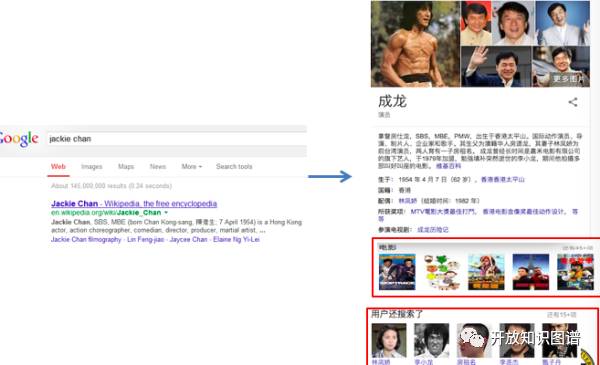
图1 语义搜索示例
在图1中,当用户输入“jackie chan",搜索引擎可以识别出jackie chan其实就是成龙,而且,会给出成龙的各种属性信息,比如说出生日期、国籍、配偶等。这些都是以前基于关键词的检索做不到的,有了知识图谱以后,就可以即问即答了。点击成龙的配偶“林凤娇”,可以直接进入她的知识卡片,见图2:
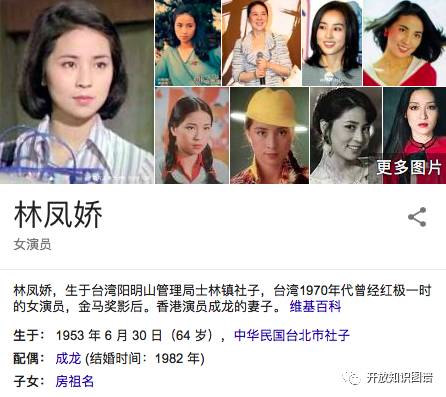
图2 语义导航示例
然后还可以继续点击房祖名看他的信息。这里我们可以把成龙、林凤娇、房祖名看出图的节点,成龙跟林凤娇之间有一个关系,即夫妻关系,林凤娇跟房祖名之间有一个关系,即母子关系,这就是成龙家庭的一个小的关系图谱。
二、股票投研情报分析
通过知识图谱相关技术从招股书、年报、公司公告、券商研究报告、新闻等半结构化表格和非结构化文本数据中批量自动抽取公司的股东、子公司、供应商、客户、合作伙伴、竞争对手等信息,构建出公司的知识图谱。在某个宏观经济事件或者企业相关事件发生的时候,券商分析师、交易员、基金公司基金经理等投资研究人员可以通过此图谱做更深层次的分析和更好的投资决策,比如在美国限制向中兴通讯出口的消息发布之后,如果我们有中兴通讯的客户供应商、合作伙伴以及竞争对手的关系图谱,就能在中兴通讯停牌的情况下快速地筛选出受影响的国际国内上市公司从而挖掘投资机会或者进行投资组合风险控制(图3)。
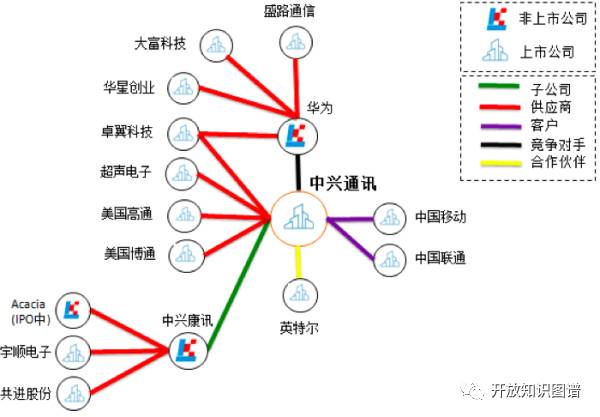
图3 股票投研情报分析
三、公安情报分析
通过融合企业和个人银行资金交易明细、通话、出行、住宿、工商、税务等信息构建初步的“资金账户-人-公司”关联知识图谱。同时从案件描述、笔录等非结构化文本中抽取人(受害人、嫌疑人、报案人)、事、物、组织、卡号、时间、地点等信息,链接并补充到原有的知识图谱中形成一个完整的证据链。辅助公安刑侦、经侦、银行进行案件线索侦查和挖掘同伙。比如银行和公安经侦监控资金账户,当有一段时间内有大量资金流动并集中到某个账户的时候很可能是非法集资,系统触发预警(图4)。
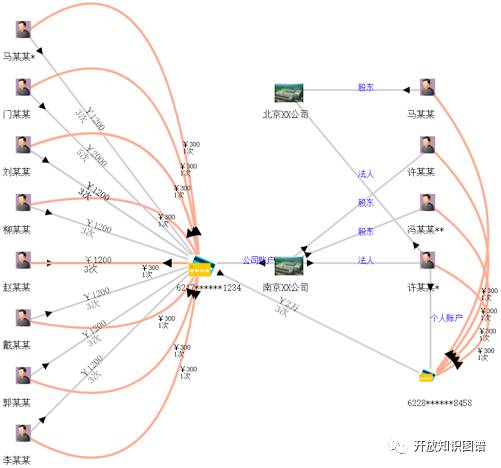
图4 公安情报分析
四、反欺诈情报分析
通过融合来自不同数据源的信息构成知识图谱,同时引入领域专家建立业务专家规则。我们通过数据不一致性检测,利用绘制出的知识图谱可以识别潜在的欺诈风险。比如借款人张xx和借款人吴x填写信息为同事,但是两个人填写的公司名却不一样, 以及同一个电话号码属于两个借款人,这些不一致性很可能有欺诈行为 (图5)。
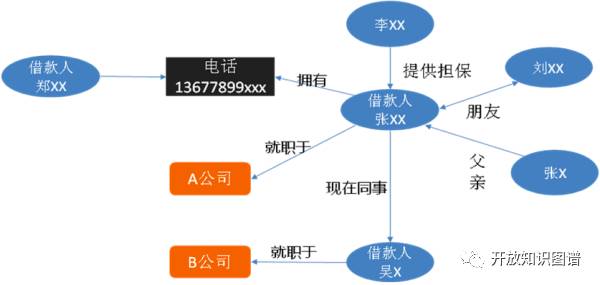
图5 反欺诈情报分析
五、面向多源异构关系数据的自然语言问答
现在很多企业都有自己的数据库,而且这些数据库因为不是同一批人构建的,所以维护数据库的成本很高,访问数据库也很不方便,而且数据库之间的关联也很难发现。通过构建一个本体(该本体可以是从数据库的schema抽取后,然后通过人工来修改得到),然后构建本体和数据库的schema的映射以及数据之间的匹配,就可以方便的实现数据的集成和数据的语义关联,并且可以利用构建的本体和通过本体集成得到的知识图谱来对自然语言做解析,从而将自然语言查询直接转化为SQL去查数据库,并且给出答案,答案可以是用图表的方式来给出。下面给出一个例子(图6):
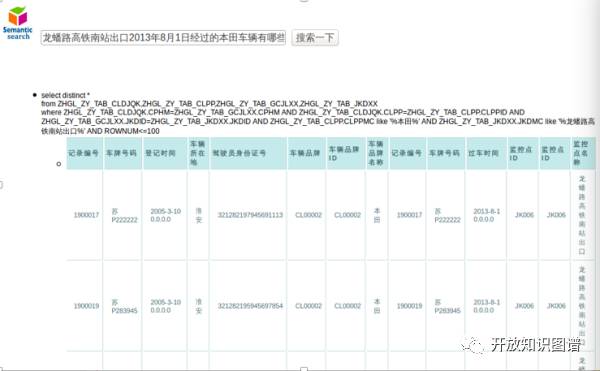
图6 数据库集成和问答系统示例
如用户提问“龙蟠路高铁南站出口2013年8月1日经过的本田车辆有哪些”,系统直接给出结果。
六、面向知识图谱的智能问答
最近几年,问答(Question answering)重新受到广泛的关注,主要原因还是因为有IBM Watson的出现(见The AI Behind Watson - The Technical Article)。Watson虽然号称可以做很多领域(比如说法律有ROSS ROSS and Watson tackle the law - Watson),但是事实上,Watson最早提出的时候只是为智力竞赛节目Jeopardy(Jeopardy! Official Site | Jeopardy.com,类似开心辞典和一站到底)定制的,类似下面这种:
Category: General Science
Clue: When hit by electrons, a phosphor gives off electromagnetic energy in this form.
Answer: Light (or Photons)
也就是说,问题会有一些分类,然后出题的人会给出一些暗示(Clue),做题的人或者机器根据这些暗示给出答案。
Watson的问答系统采用了wikipedia和DBpedia、Yago等半结构化数据以及图谱数据,但是更多的还是从文本中提取各种证据(evidence)来回答。IBM Watson系统架构见下图(图7)。
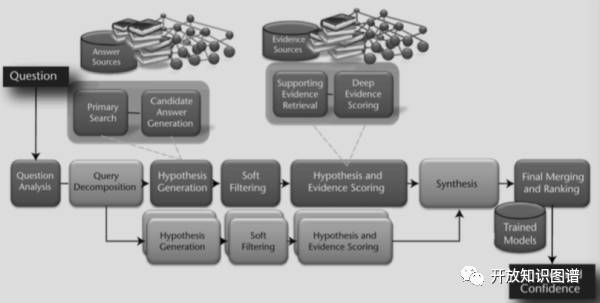
图7 IBM Watson系统架构
IBM Watson系统被神化成可以在任何领域适用,导致只要做问答相关项目,都容易被挑战跟Watson有什么差异。事实上,Watson系统和很多人工智能系统一样,是高度定制化的,当然,相关技术确实是可以用到多个领域,但是需要有一定的变化。
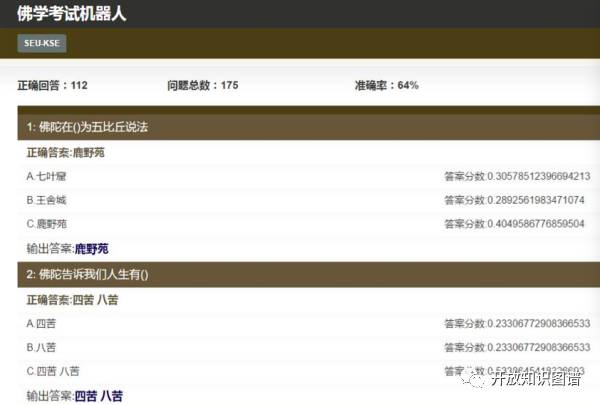
东南大学认知智能研究所借鉴了Watson技术,启动了一个佛学考试机器人项目,旨在回答佛学相关问题。为了做这个系统,需要先构建一个佛学知识图谱,通过图谱和佛学相关的网页,利用问答技术解题。考试题目例子如下:
1.僧伽是①涅槃义②和合众③杀贼义。
2.「诸行无常、诸法无我、涅盘寂静」称为①三种无常②三法印③三乘道。
3.人生最大的错误是①杀生②妄语③邪见。
下面是系统的截屏:
七、辅助判案
知识图谱技术可以帮助我们快速构建一个法律知识图谱,目前还缺乏法律知识图谱的理论工作。跟其他领域的知识图谱相比,法律知识图谱需要考虑法律的逻辑,下面就是一个法律知识图谱的片段:
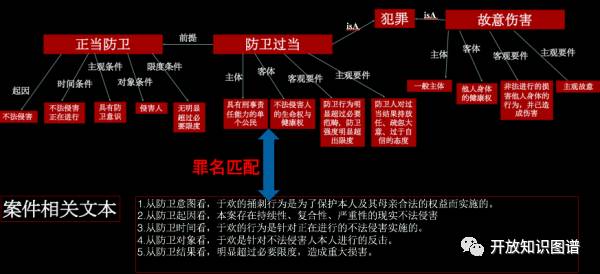
从上面这个例子可以看出,每一个犯罪行为都有主体、客体、主观要件和客观要件,我们就需要从文本中去抽取这些信息,从而形成一个关于犯罪行为的图谱,而通过对海量判决书的挖掘,可以建立犯罪行为之间的关联,比如说,防卫过当和故意伤害之间有一个关联,即误判为的关系。通过这个图谱,给定一个判决书,可以辅助法官判的一个案件是否有误判,是否需要补充信息。
致谢:感谢王昊奋博士对本文部分内容的建议。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。


