OpenKG开源系列 | 人物百科知识图谱(东南大学)
OpenKG地址:http://openkg.cn/dataset/figure-kg
GitHub地址:https://github.com/F-period/Open_Chinese_Figure_KG/
开放许可协议:CC BY 4.0
贡献者:东南大学(王然,漆桂林,殷春锁,王鹏,金日辉)
1、图谱简介
以人物为中心的知识图谱可以有效地显示个人信息和人际关系,并进一步支持相关应用。知识图谱上的人际关系搜索系统直观地说明了社会中人与人之间的关系。人立方搜索引擎和搜狗人物知识图谱都是例子,尽管出于隐私因素它们今天已经被禁用。此外,小型特殊的人物知识图可以促进历史和文化研究。在事件分析和书籍阅读任务中,可以构建相关的图形知识图作为一种辅助。
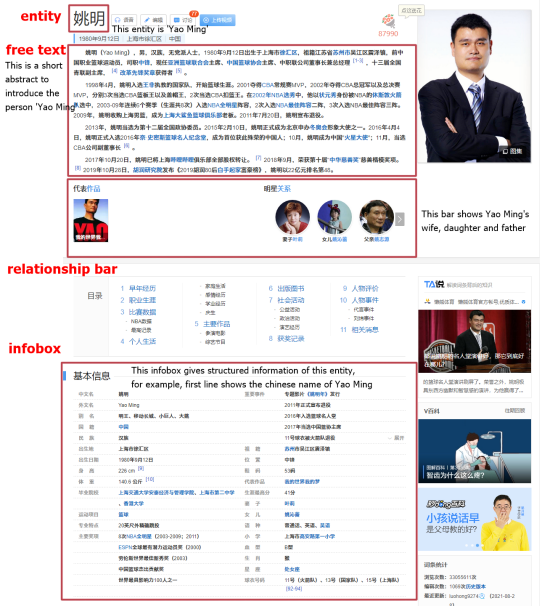
百科数据里包含了大量关于人物的信息,可以作为人物知识图谱的数据基础。下图是一个百度百科页面的展示,可以看到,百度百科中具有多模态、结构化与半结构化的多种数据信息。
2、构建方法

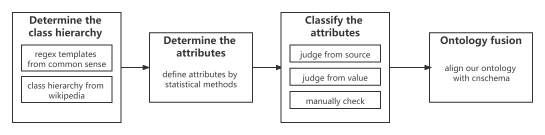
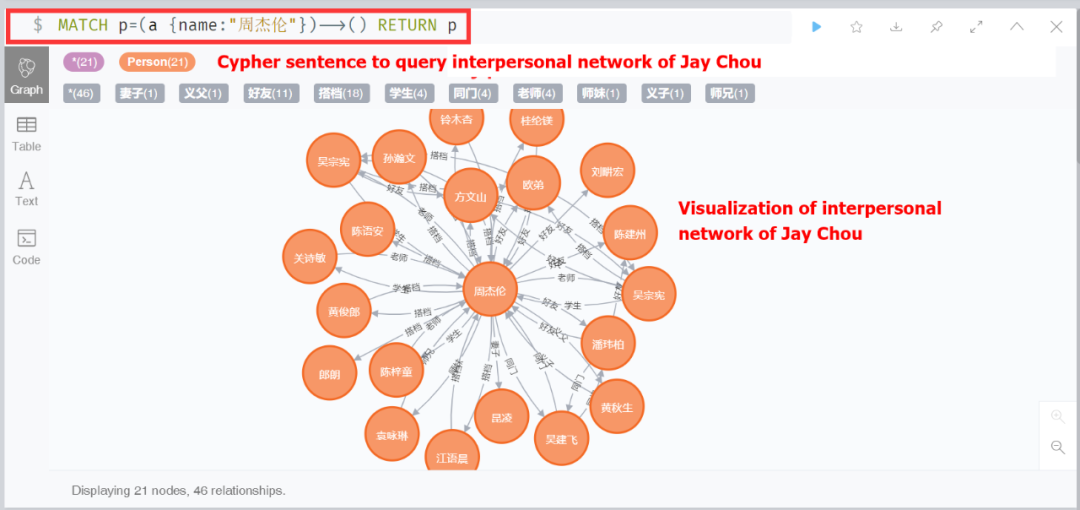
在信息提取步骤中,我们自动从半结构化和非结构化数据中提取实体、关系和属性等结构化信息。关键技术包括实体提取、关系提取和属性提取。除了传统的HTML提取和正则模板方法。且我们设计方法单独处理了百度百科页面中的表格数据,将其转换为结构化的RDF三元组。我们往往将基于模型的方法和基于模板的方法的结果结合起来,形成最终的结果。在大多数任务中,正则表达式模板的效率高于模型,模型通常起着互补作用。

最后,我们整合所有提取的结果,并将它们转换为neo4j数据库的适当形式。
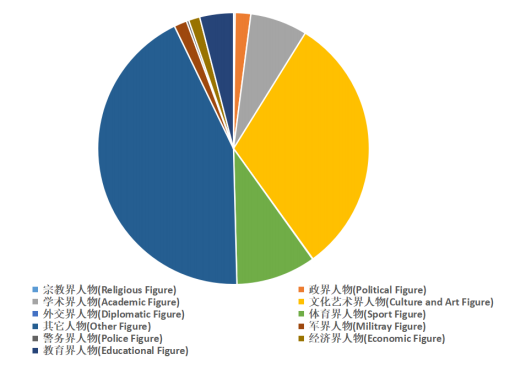
3、成果总结

4、视频详解
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。
登录查看更多
相关内容

知识图谱(Knowledge Graph),在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
知识图谱是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。它能为学科研究提供切实的、有价值的参考。
Arxiv
20+阅读 · 2021年5月27日
Arxiv
27+阅读 · 2021年1月21日
Arxiv
21+阅读 · 2018年1月16日




相关VIP内容
相关资讯