【密苏里大学博士论文】《使用机器学习技术丰富知识图谱》

摘要
第1章 介绍
1.1 概述


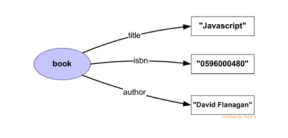
| 书名 | 标题 | 作者 | 出版标识 | 页数 |
| 0596002637 | 部分RDF | Shelley Powers | 7642 | 350 |
| 0596000480 | 脚本 | 大卫-弗拉纳根 | 3556 | 936 |
-
现在的技术大多与计算机相关的项目有关,如社交媒体、银行、广告、教育等。食品、水和能源系统并不像其他专业那样拥有相同的技术兴趣。因此,我们的项目旨在建立一个系统来改进粮食、水和能源的知识图谱,以增强这些系统的功能,使用户能够以更好的方式分析数据库和图谱[83]。 -
在将数据库转换为RDF模型时,由于缺乏现有的本体,我们不得不在DBpedia本体的基础上创建一个新的本体,以便与FEW系统一起使用。 -
分析数据并不是一个新的概念,但是通过添加与现有数据相关的额外的RDF四元组来丰富数据集,基于这些四元组之间的语义相似性是一个真正的挑战,这将丰富一个数据集,为用户提供更多关于该特定数据集中存在的概念的有用信息和事实。
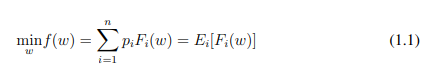
 。FL允许在这些数据上进行训练,而不需要将数据传输到持有人的场所之外。特别是,FL是 "把代码带到数据上,而不是把数据带到代码上 "这种更普遍的方法的一个实例,反过来,它将使用本地化的数据训练一个模型,而不需要允许访问它。Mcmahan和Ramage[20]给出了FL的一般描述,Konecn等人(2016a)[52]McMahan等人(2017[20]2018[63])和[19]给出了理论,以解决数据的隐私、所有权和定位的基本问题。FL最初是针对手机和边缘设备应用而推出的[62],后来FL也被用于多个组织,如医院,我们将这两种设置分别称为 "跨设备 "和 "跨语境",正如[62]中提到的。
。FL允许在这些数据上进行训练,而不需要将数据传输到持有人的场所之外。特别是,FL是 "把代码带到数据上,而不是把数据带到代码上 "这种更普遍的方法的一个实例,反过来,它将使用本地化的数据训练一个模型,而不需要允许访问它。Mcmahan和Ramage[20]给出了FL的一般描述,Konecn等人(2016a)[52]McMahan等人(2017[20]2018[63])和[19]给出了理论,以解决数据的隐私、所有权和定位的基本问题。FL最初是针对手机和边缘设备应用而推出的[62],后来FL也被用于多个组织,如医院,我们将这两种设置分别称为 "跨设备 "和 "跨语境",正如[62]中提到的。
-
FoodKG是一个新颖的软件工具,旨在使用多种功能来丰富和增强FEW图。为所提供的三元组添加上下文是首批功能之一,可以更容易地查询图,为深度学习模型提供更好的输入。 -
FoodKG提供了不同的自然语言处理(NLP)技术,如POS标签、chunking和Stanford Parser,用于提取有意义的主题,统一重复的概念,并将相关实体连接在一起[22, 50, 59]。 -
FoodKG采用了专业化张量模型(STM)[37]来预测图中新增加的关系。 -
我们采用WordNet[67]来返回所提供主题的所有偏移量,以解析ImageNet[85]中的相关图像。这些图像将以通用资源定位器(URL)的形式被添加到图中,作为相关的和纯粹的图像。 -
FoodKG利用GEMSEC[84]模型,该模型在AGROVOC上经过转移学习和微调后产生AGROVEC,以提供相似和链接概念之间的语义相似度分数。AGROVEC与在同一数据集上训练的词嵌入和知识图谱嵌入模型进行了比较。由于在特定领域的图数据上进行了训练,AGROVEC在Spearman Correlation Coefficient得分方面取得了优于其竞争对手的表现。 -
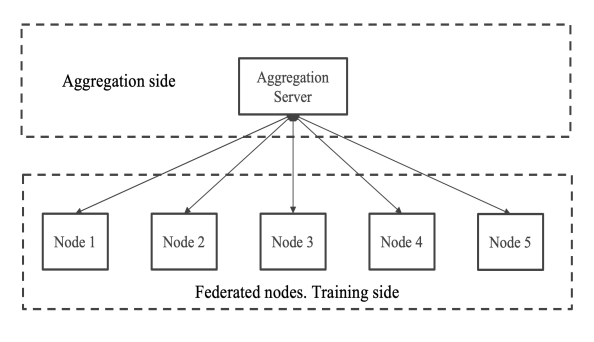
我们引入了联邦学习(FL)技术来进一步扩展我们的工作,通过在每个数据集站点训练较小版本的模型而不访问数据,然后在服务器端汇总所有的模型,将私人数据集纳入其中。我们提出了一种我们称之为RefinedFed的算法,通过在聚合阶段之前对每个数据集站点的模型进行过滤来进一步扩展当前的FL工作。我们的算法在MNIST日期集上将目前的FL模型准确性从84%提高到91%。
便捷下载,请关注专知人工智能公众号(点击上方蓝色专知关注)
后台回复“KGML” 就可以获取《【密苏里大学博士论文】《使用机器学习技术丰富知识图谱》》专知下载链接



登录查看更多
相关内容

Arxiv
0+阅读 · 2022年11月22日
Arxiv
0+阅读 · 2022年11月18日
Arxiv
14+阅读 · 2019年1月17日
Arxiv
11+阅读 · 2018年5月9日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年11月22日
Arxiv
0+阅读 · 2022年11月18日
Arxiv
14+阅读 · 2019年1月17日
Arxiv
11+阅读 · 2018年5月9日