

摘要
虽然人工智能应用于法律领域是一个起源于上个世纪的话题,但人工智能最近的进展使其发生了革命性的变化。本工作概述和背景介绍了自然语言处理领域的主要进展,以及这些进展如何被用于进一步发展法律文本分析的现状。
1. 引言
世界上每个国家的内部运作都建立在一个复杂的司法系统之上。例如,在葡萄牙,《葡萄牙官方公报》(Di´ario da Rep´ublica)是公布葡萄牙共和国所有法律和规范的场所。目前有150多万项法律法规在实施,每个月有1000多项新的法律法规在DRE上发表。这个在线资源提供了访问葡萄牙所有立法的途径,以及让公民找到他们所需要的法律和规范的服务。
鉴于公民拥有的权利和必须遵守的义务,这类信息对所有公民来说都很容易获得,这一点显然很重要。在访问立法搜索时,由于使用的语言级别,一些公民可能很难找到搜索结果。普通市民通常使用自然语言(NL)来引入搜索查询。问题在于,法律和法律规范包含的语言——尽管在技术上属于非母语——使用了专门的术语和句子结构。即使是简单的搜索也会遇到双重障碍。一方面,系统必须理解用户的查询,并将其与正确的法规联系起来。另一方面,由于格式的原因,返回的文本不容易被普通用户理解。
法律文本、规范、程序和论证的逻辑特征表明,形式逻辑可以作为代表法律规则和情境事实的模型。因此,根据规则对事实的应用,可以帮助公民进行推理。但是,要使这个系统发挥作用,我们前面提到的“自然语言障碍”必须克服。首先,有必要将法律规范从NL翻译成某种与机器兼容的语义或逻辑表示形式。由于NL和法律语言的一些特性,这个困难成为了一个真正的障碍。然后,还必须将用户查询从NL转换为语义或逻辑表示。最后,在系统完成逻辑推理后,“自然语言障碍”必须进行第三次换位,为外行人生成用户友好的解释或程序描述。自然语言处理的革命性进展最近改变了这一局面,创造了可扩展的方法来分析大型文本语料库。它们也已开始应用于法律领域,为跨越上述障碍开辟了新的途径。许多困难和未决问题仍然存在,但似乎在未来几年内,我们将能够创造新的工具,开发创新的应用,以帮助公民与法律互动。
本文对人工智能和法律领域、自然语言处理(NLP)及其在法律领域的应用现状进行了概述、情境化和分析,目的是确定如何最好地利用最近的进展来改善由DRE提供给用户的搜索服务。本文档组织如下。在下一节中,我们将简要概述人工智能应用于法律领域的子领域。在第三部分,NLP的深度学习进展,我们将介绍NLP的深度学习的最新进展。语义表示部分概述了语义表示语言和自然语言处理中的语义信息提取。之后,我们将讨论NLP(探索新的进展和语义表示语言的使用)在与法律领域相关的任务中的新应用,如法律信息检索和规范提取。
2. 人工智能和法律
应用于法律领域的两种传统人工智能方法,要么是以逻辑为基础,要么以数据为中心。基于逻辑的方法植根于像[3]这样的先驱的工作,但是第一次将其应用于真正的法律,像英国国家法案[52]的规则的形式化,是在80年代制定的。以数据为中心的方法在法律领域的应用也始于20世纪80年代,以基于案例的推理HYPO系统[4]为例。该制度的目标是在先例的基础上建立推理模式,引用过去的案例作为法律结论的理由。
2.1基于逻辑的方法
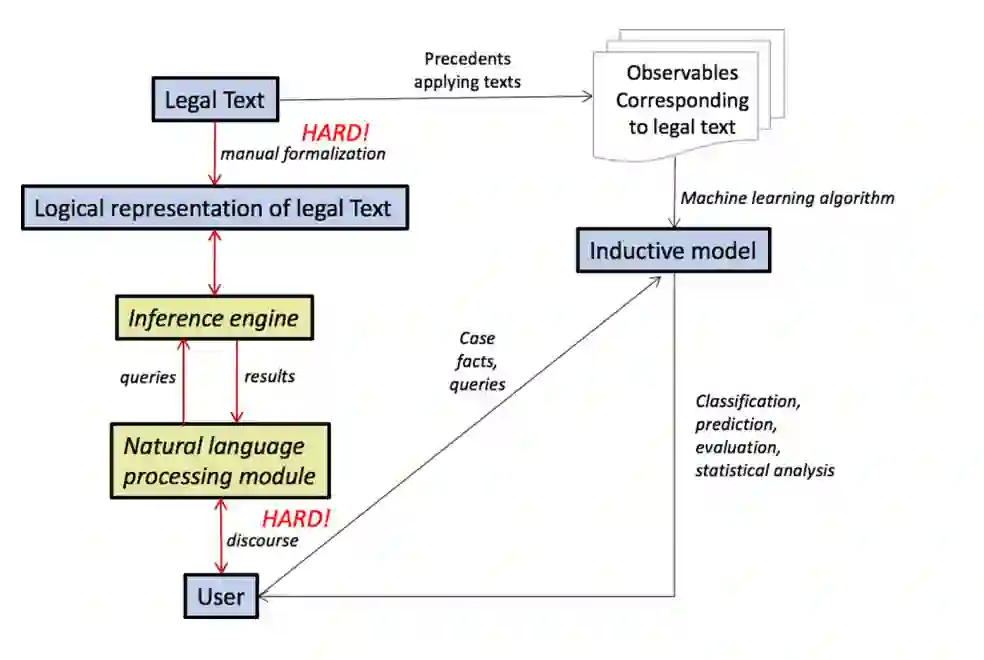
图1显示了基于会话逻辑的法律推理系统的体系结构。原则上,可以从有关法律和案件事实的形式化版本中推断出法律结论。但是,“自然语言障碍”造成了两个主要障碍:以逻辑表达形式表示法律文本的挑战,以及从自然语言[15]表达的事实评估法律谓词的困难。

基于会话逻辑的法律推理系统结构
2.2 以数据为中心的方法
以数据为中心或数据驱动的方法具有自动化和可伸缩性的优点,大大减少了以逻辑形式对法律文本进行人工编码的繁琐工作。它可以用来替代法律推理系统或整个系统的特定组件。如图3所示,主要的前提是通过构建一个数据集的例子,例如一组与法律文本翻译成一个逻辑表示的例子,一个可以使用机器学习技术——如深度神经网络——归纳学习如何自动执行相同的任务在新的例子。但是,这里有一个权衡,因为以数据为中心的方法通常透明度和解释性较低[15]。例如,在深度神经网络的情况下,学习的模型将是一个非常复杂的模型,通常有数百万甚至数十亿个参数被组合起来——通常以非线性的方式——来确定一个特定的输出。对于人类观察者来说,理解模型产生特定翻译、预测或决策的原因或方式并不容易。出于这个原因,我们认为,与其取代整个系统,不如将数据为中心的方法用作改进法律推理系统某些组件的工具——例如将法律文本翻译成相应逻辑形式的组件。
在基于会话逻辑的法律推理系统的体系结构中增加一个以数据为中心的组件。
3. 深度学习自然语言处理
近年来,由于基于Transformer的模型的出现,研究人员看到了深度学习模型和技术在自然语言处理领域的应用取得了重大突破。本节将通过描述NLP中使用的编码器-解码器模型的演变来概述这些进展,从基于LSTM的序列到序列模型,最后介绍最新的基于transformer的方法。

Transformer架构

Multi2OIE的体系结构。利用BERT的隐藏状态提取谓词,然后将隐藏序列、谓词的平均向量和位置嵌入连接起来,作为多头注意力块的输入进行参数提取。
4. 深度学习自然语言处理在法律领域应用
研究人员已经开始探索利用深度学习模型对一系列下游任务实现的自然语言处理的最新进展。在本节中,我们将介绍一些系统的示例,这些系统将说明如何使用自然语言处理来改进一组对法律领域有用的任务,例如信息检索或规范提取。我们将描述直接应用于法律文本的系统的例子,但也将描述其技术可以容易地应用和转移到法律领域的系统。
法律信息检索的语义NLP方法
NLP领域已经显示出在创造解释和代表法律文本的新方式方面非常相关,以便不了解基本法律概念的普通公民能够理解和查询该系统。对于这个复杂的任务,有几个因素会影响基于NL的法律查询系统的良性运行。在一个句子中,单词的顺序是决定其语义价值的一个非常重要的因素。发布的前几个句子编码器——有些实际上是改头换面的单词编码器——也陷入了同样的困境。缺少词序编码。两个单词完全相同,但顺序不同的句子,可能有完全不同的意思。由这个顺序定义的语境会影响特定单词的意思。例如,当一个人说“我去跑步了”时,我们就会认为“跑”这个词与这项运动有关联。当另一个人说,你必须在你的电脑上运行这个,意思完全不同于另一个句子。它不仅被用作动词,而且它的意思也不再与体育有关,而是与计算任务有关。而且,即使在run这个词被用作与这项运动相关的动词的情况下,在大多数情况下,由于相关的单词,它仍然可以与计算意义区分开来。
评价两篇文本之间的语义文本相似度(STS)非常重要,它是指两篇文本之间的意义相似度。这项任务对于确定搜索系统如何能够捕获查询的含义并将其作为选择搜索结果的一个因素非常有用。在STS任务中度量模型性能的一个重要基准是GLUE基准。它使用指标和STS数据集,专门用于评估模型将意义编码到生成的令牌嵌入中的能力。

句子BERT的相似性计算
自动合规检查的语义NLP方法
SNACC(基于语义自然语言处理的自动合规检查)系统[63]能够自动从国际建筑规范的法规文件中提取法规信息。提取的法规信息用一阶逻辑(FOL)表示。通过使用FOL形式主义表示这些信息,SNACC能够自动检查特定的建筑模型是否与法规一致。SNACC的另一个有趣的方面是,作者探索了基于树的可视化表示的法规陈述(基于树的表示形式是由符合表示),并认为基于树的表示让用户更容易理解。图21显示了一个基于树的表示的示例。
利用SRL从法律文本中提取规范
Humphreys和他的同事[36]最近研究了如何从法律文本中自动提取知识,并使用这些知识填充法律本体的问题。为了解决这个问题,他们创建了一个基于自然语言处理和基于领域知识的后处理规则的系统。作者声称他们是第一个使用PropBank语义角色标签从法律文本中提取定义和规范的人。该系统主要由两部分组成。第一个组件是Mate Tools语义角色标记器[10],它从法律文本中提取抽象语义表示以及依赖解析树。第二个组件由一组规则组成,这些规则标识可能的规范和定义,对它们的类型进行分类,并将语义角色树中的参数映射到法律本体中特定领域的位置。使用SRL的优势在于,它用相关的语义信息丰富了句子解析树,这将简化为提取规范和定义而必须创建的规则。

结论
在本文中,我们简要分析了人工智能应用于法律领域的研究领域的历史和现状,以及它的前景和挑战。我们还发现了一些可用的产品。然后,我们回顾了深度学习应用于自然语言处理、信息检索和语义表示的最新趋势,这些可用于构建更好的系统,帮助公民访问和理解法律。这些技术,有些是最近才发表的论文,就在这些结论发表前的几周,可以用来帮助解决我们上面描述的法律信息搜索系统的非专业用户面临的三重自然语言障碍。特别有趣的是,最近关注的系统能够探索使用自动提取的语法和语义信息来完成需要自然语言理解的任务。语义信息——即使只是在较浅的层次上提供——提供了对法律语料库中的文本的更深入的理解,使我们能够超越单词匹配技术。另一个相关趋势是使用弱监督技术(具有低注释成本和易于扩展到大领域)自动生成问题和答案的数据集,并使用它们在信息检索或问题回答等下游任务中训练模型。我们相信,以其中一些技术为基础,将有可能建立一个“主动法律信息检索和过滤系统”,允许以简化程序并使检索数据更相关和及时的方式访问法律文本。
![]() 参考文献
参考文献
 参考文献
参考文献[1] Ajani, G., Boella, G., Caro, L.D., Robaldo, L., Humphreys, L., Praduroux, S., Rossi, P., Violato, A.: The european taxonomy syllabus: A multilingual, multi-level ontology framework to untangle the web of european legal terminology. Appl. Ontology 11(4), 325–375 (2016)
[2] Aletras, N., Tsarapatsanis, D., Preot¸iuc-Pietro, D., Lampos, V.: Predicting judicial decisions of the european court of human rights: A natural language processing perspective. PeerJ Computer Science 2, e93 (2016)
[3] Allen, L.E.: Symbolic logic: A razor-edged tool for drafting and interpreting legal documents. Yale Law Journal 66, 833—-879 (1957)
[4] Ashley, K.D.: Reasoning with cases and hypotheticals in HYPO. International Journal of Man-Machine Studies 34, 753–796 (1991)
[5] Ashley, K.D.: Case-based models of legal reasoning in a civil law context. In: International congress of comparative cultures and legal systems of the instituto de investigaciones jur´ıdicas (2004)
[6] Athan, T., Governatori, G., Palmirani, M., Paschke, A., Wyner, A.: LegalRuleML: Design Principles and Foundations, pp. 151–188. Springer International Publishing (2015)
[7] Banarescu, L., Bonial, C., Cai, S., Georgescu, M., Griffitt, K., Hermjakob, U., Knight, K., Koehn, P., Palmer, M., Schneider, N.: Abstract Meaning Representation for sembanking. In: Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse. pp. 178–186. Association for Computational Linguistics, Sofia, Bulgaria (Aug 2013), https://www.aclweb.org/anthology/W13-2322
[8] Barros, R., Peres, A., Lorenzi, F., Wives, L.K., da Silva Jaccottet, E.H.: Case law analysis with machine learning in brazilian court. In: International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems. pp. 857–868. Springer (2018)



