
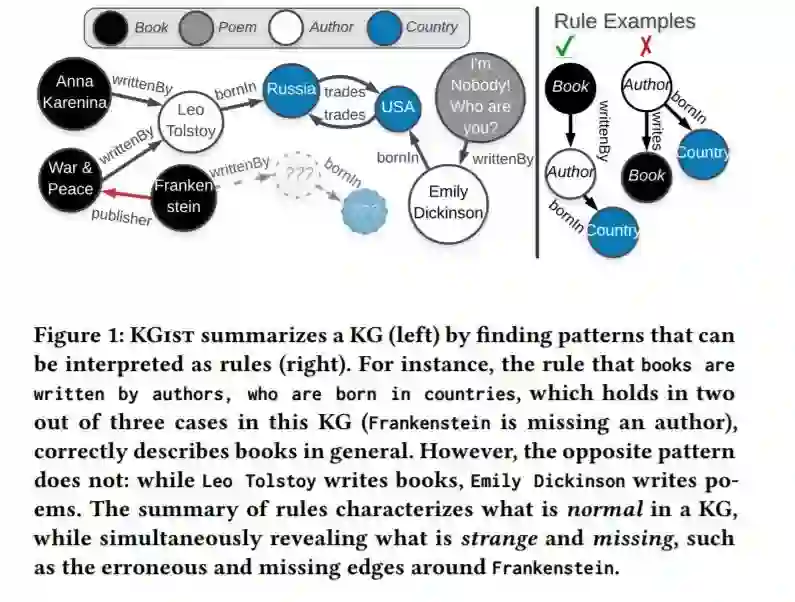
知识图谱(KGs)在图的结构中存储了关于世界的高度异构的信息,对于回答问题和推理等任务非常有用。然而,它们经常包含错误和丢失信息。KG精化的活跃研究已经解决了这些问题,裁剪技术可以检测特定类型的错误,也可以完成KG。
这个工作,我们引入了一个统一的解决方案来描述KG的特性,通过用一组归纳的软规则将问题化为无监督的KG总结,这些规则描述了KG中的正常值,从而可以用来识别异常值,不管是奇怪的还是缺失的。与一阶逻辑规则不同,我们的规则被标记为有根图,即根据节点的类型和KG中的信息,描述一个(可见或不可见的)节点周围的预期邻域的模式。在传统的基于支持/信任的规则挖掘技术的基础上,我们提出了KGist,即知识图谱归纳摘要,它学习归纳规则的摘要,根据最小描述长度原则对KG进行最佳压缩——这是我们在KG规则挖掘上下文中首次使用的公式。我们将规则应用于三个大型KGs (NELL、DBpedia和Yago),以及诸如压缩、各种类型的错误检测和不完整信息标识等任务。我们证明了KGist在错误检测和不完全性识别(识别93%缺失实体的位置—比基线多10%)方面优于特定于任务的、有监督的和无监督的基线,同时对于大型知识图谱也是有效的。
成为VIP会员查看完整内容
相关内容
Arxiv
3+阅读 · 2019年6月6日

相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2019年6月6日