

深度神经网络(DNN)在几乎所有的学术和商业领域都产生了突破性的成果,并将作为未来人机团队的主力,使美国防部(DOD)现代化。因此,领导人将需要信任和依赖这些网络,这使得它们的安全成为最重要的问题。大量的研究表明,DNN仍然容易受到对抗性样本的影响。虽然已经提出了许多防御方案来对付同样多的攻击载体,但没有一个成功地使DNN免受这种脆弱性的影响。新颖的攻击暴露了网络防御的独特盲点,表明需要一个强大的、可适应的攻击,用来在开发阶段早期暴露这些漏洞。我们提出了一种基于强化学习的新型攻击,即对抗性强化学习智能体(ARLA),旨在学习DNN的漏洞,并产生对抗性样本来利用这些漏洞。ARLA能够显著降低五个CIFAR-10 DNN的准确性,其中四个使用最先进的防御。我们将我们的方法与其他最先进的攻击进行了比较,发现有证据表明ARLA是一种适应性攻击,使其成为在国防部内部署DNN之前测试其可靠性的有用工具。
1.1 深度学习与美国防部
美国海军(USN)和国防部(DOD)建立对对手的持久技术优势[1],他们必将尖端的机器学习(ML)技术整合到当前的系统和流程中。ML,即系统从原始数据中提取意义和知识[2],已经将更广泛的人工智能(AI)领域推向了似乎无止境的应用。人们很难找到一个领域,无论是学术、商业还是医疗领域,ML都没有进行过革新。ML已经被用来帮助识别汽车保险欺诈[3],提供宫颈癌的早期检测[4],以及检测和描述飞机上冰的形成[5]。在这些情况下,ML模型的作用不是做决定,只是为人类操作员提供更好的信息。通过以类似的方式应用ML,国防部有一个路线图,可以将系统和流程演变成遵守道德人工智能原则的人机团队[6]。
虽然ML可以包含广泛的用于预测的模型,但一个被称为深度学习的子集是这个人工智能夏天的驱动力。与线性回归建模和支持向量机等更简单的ML技术不同,深度学习包含了利用深度神经网络(DNNs)的ML模型,它使用许多隐藏的人工神经元层,通过数据学习复杂的概念[2]。尽管DNNs被用于许多目的,但本论文重点关注那些专门用于图像识别的DNNs。
1.2 信任机器
美国防部要想成功过渡到人机团队,军事和文职领导人必须能够信任和依赖基础技术。这对高级领导人来说是一个不小的要求。与人类分析师不同,他们的思维过程可以通过对话来理解,但没有明确的路径来理解DNN如何完全基于数据做出决定。因此,信任必须建立在一个合理的信念上,即该系统能够抵御攻击,其结果是一致和可靠的。任何关于可信度和可靠性的担忧都是合理的,因为一连串的研究已经证明,DNN在对抗性样本面前始终是脆弱的。
对抗性样本(AE)是一个良性的输入样本,通过添加扰动导致目标DNN返回不正确的输出而被畸形化。AE的目的是在降低目标网络的整体准确性的同时显得非恶意的,这可能会产生严重的、威胁生命的后果。例如,考虑到自动驾驶以及汽车不混淆停车和让行标志是多么关键。对于军事指挥官来说,如果一个网络对对抗性样本不健全,那么对该系统的信任很容易就会下降,并且该系统会被忽略,而被用于更传统和耗时的分析。想象一下一个系统,DNN正确地过滤掉90%的图像,只留下10%的标签供人类审查。如果该系统被成功攻击,那么人机团队就会失败,分析员很快就会被新的工作量压垮。
1.3 研究问题
对抗性攻击算法的核心是函数,即给定一个良性的输入𝑋,就会产生一个对抗性的𝑋ˆ。许多攻击可能需要样本的真实标签(𝑦),或目标网络或它的一些近似值,但它们仍然只是函数。因此,在给定的一组输入变量的情况下,某种攻击总是会输出相同的AE。深度学习不是攻击本身的一部分,这意味着在创建对抗性样本时没有涉及ML。这种生成AE的算法方法使我们考虑到强化学习(RL)领域,其中一个DNN "智能体"学习在特定环境中的最佳行为,同时追求一个特定的目标[7]。来自RL研究小组DeepMind的大量成功案例表明,RL能够在各种游戏中实现超人类的表现[8]-[11]。最简单的说法是,RL智能体通过观察环境的模式进行学习,采取获得某种奖励的行动,然后观察随后的状态。智能体试图使其获得的总奖励最大化,最终学会了最佳的行为策略。
考虑到RL和对抗性样本对DNN构成的威胁,我们提出了第一个研究问题:
1)如果图像是环境,像素变化是可玩的行动,强化学习智能体能否学会生成最小扰动的对抗性样本?
在所有研究对抗性攻击的学术文献中,有同样多的文献涉及对抗性防御: 一个新的攻击被提出来,之后的某个时候会有一个反击它的防御,而这个循环会重复下去。虽然最先进的防御手段可以抵御所有当前的攻击,但不能保证防御手段能够抵御未知的攻击。如果一种攻击可以适应任何防御,它将帮助研究人员和开发人员领先于未知的攻击。考虑到攻击的适应性,我们提出了第二个研究问题:
2)基于强化学习的对抗性攻击能否成为一种适应性攻击?
通过解决这两个问题,我们首次将对抗性研究和强化学习这两个领域融合在一起。
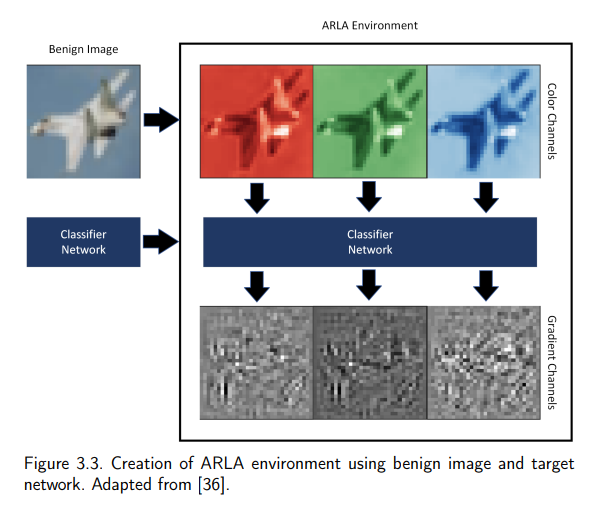
1.4 对抗强化学习智能体(ARLA)
这项研究引入了第一个基于RL的对抗性攻击。命名为对抗性强化学习智能体(ARLA),我们的攻击使用良性样本图像作为学习环境来生成对抗性样本,目标是找到与原始样本的ℓ2距离最短的对抗者。ARLA使用双重深度Q-learning(DQL),在第2章中进行了解释,并采用了改进的深度Q-网络(DQN)智能体架构,在第2章和第3章中进行了详细解释。我们的结果提供了证据,证明ARLA是一种自适应的对抗性攻击,对本论文中用于攻击评估的所有五种模型都显示出明显的攻击成功。虽然我们的结果很有希望,但还需要做更多的工作来稳定ARLA如何学习最佳行为政策。
我们研究的目的是为国防部提供一个有效的工具来评估武装部门正在开发的DNN。与其他需要由技术专家对特定防御进行调整的适应性攻击不同,基于RL的对抗性攻击可能会以更大的难度和最少的培训来利用。我们希望ARLA就是这样一种攻击,并成为在作为未来军事系统一部分部署的人机团队中建立机构信任的一个小而有价值的步骤。






