【CVPR2023】基于强化学习的黑盒模型反演攻击

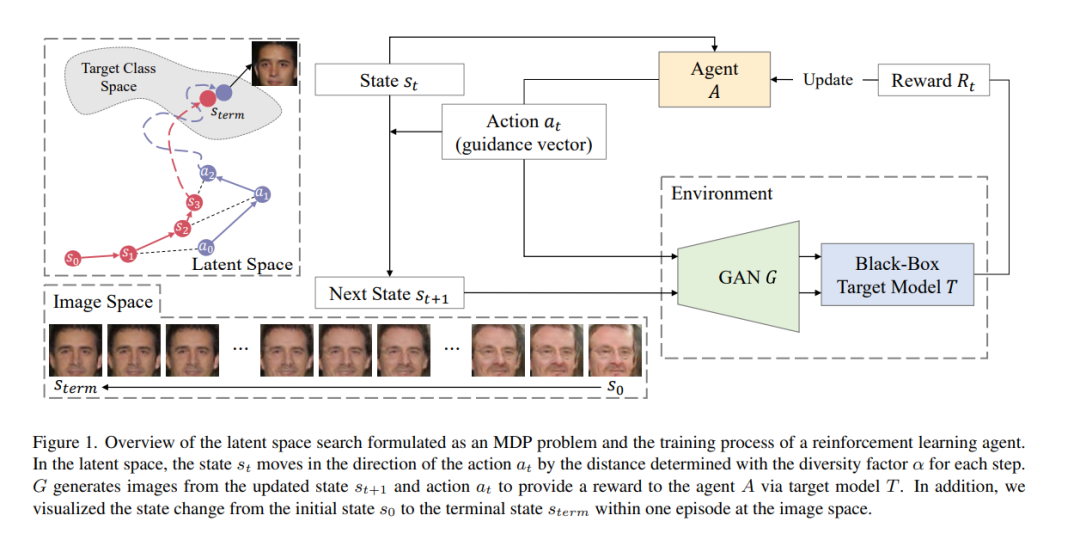
模型反演攻击是一种隐私攻击,它仅通过访问模型来重构用于训练机器学习模型的私有数据。近年来,利用生成对抗网络(Generative Adversarial Networks, GANs)从公共数据集中提取知识的白盒模型反演攻击因其出色的攻击性能而受到广泛关注。另一方面,目前利用GANs的黑盒模型反演攻击存在一些问题,例如无法保证在预定数量的查询访问内完成攻击过程,或实现与白盒攻击相同的性能水平。为克服这些限制,本文提出一种基于强化学习的黑盒模型反演攻击。本文将潜空间搜索表述为马尔可夫决策过程(MDP)问题,并使用强化学习来解决它。该方法利用生成图像的置信度分数为智能体提供奖励。最后,利用在MDP中训练的智能体找到的潜在向量来重构隐私数据。在多个数据集和模型上的实验结果表明,该攻击方法在取得最先进攻击性能的同时,成功地恢复了目标模型的隐私信息。本文通过提出一种更先进的黑盒模型反演攻击来强调隐私保护机器学习研究的重要性。
https://www.zhuanzhi.ai/paper/9ed3a5a3de3f2f121b1b49bffe5a7662
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复或发消息“RLBA” 就可以获取《【CVPR2023】基于强化学习的黑盒模型反演攻击》专知下载链接



登录查看更多
相关内容
Arxiv
0+阅读 · 2023年5月31日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年5月31日