

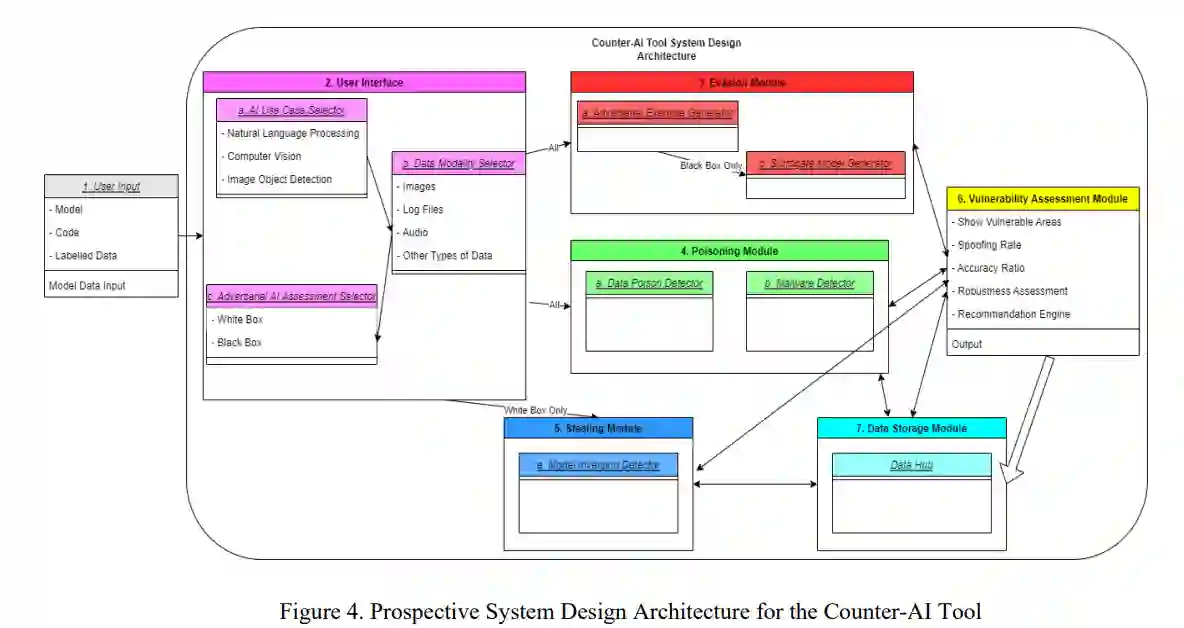
这项工作包括在征求研究、设计和开发用于人工智能(AI)系统对抗性测试和评估的反人工智能工具的初步建议和结论。该报告包括对相关人工智能概念的文献回顾和对抗性人工智能领域的广泛研究。一项密集的利益相关者分析,包括从20多个政府和非政府组织中征集需求,协助确定哪些功能需求应包括在反人工智能工具的系统设计中。随后的系统架构图接受用户输入,测试各种类型的对抗性人工智能攻击,并输出人工智能模型的脆弱性。在这个工具投入使用之前,伙伴组织将进行迭代实验,这是开发和部署这个反人工智能工具的下一个步骤。
美国国防部(DoD)对使用人工智能(AI)技术来提高军事任务能力和日常工作越来越感兴趣。美国防部将人工智能定义为 "旨在像人一样思考或行动的人工系统,包括认知架构和神经网络"(Sayler, 2020)。它将对抗性人工智能定义为 "对手可能针对人工智能系统部署的反措施,以及保障性能所需的评估步骤和防御措施"(美国防部,2018)。美国防部承诺研究新的理论、技术和工具,使人工智能系统更有弹性,表现出更少的意外行为。美国防部的战略概述包括提供解决关键任务的人工智能能力,通过共同的基础扩大人工智能在整个国防部的影响,培养领先的人工智能劳动力,与各种合作伙伴合作,并在军事道德和人工智能安全方面引领世界(美国防部,2018)。
然而,随着人工智能系统实施和采用的增加,对手已经威胁要攻击和操纵这些系统;目前,没有现成的工具来帮助对人工智能系统进行对抗性测试和评估(T&E),以便在其投入使用之前评估漏洞和失败模型。在任务使用情况下,美国防部不应该在没有事先评估安全或反人工智能措施的有效性的情况下部署这些人工智能系统。设计和建立有弹性的人工智能系统对人工智能防御至关重要,因为这些系统更容易解释,更值得信赖,并能确保其免受各种已确定的对抗性攻击方法的影响。
因此,美国防部旨在确保部署的人工智能系统更加安全,以防止对手的操纵。对手将基于三种访问范式攻击人工智能:白盒、黑盒、灰盒。白盒攻击给予攻击者最高的能力,这发生在对手可以访问所有模型组件时(Kurakin,2018)。在黑箱攻击中,对手对模型没有完全透明的看法,但能够探测模型以推断其结构和组件(Kurakin,2018)。攻击者能力的最后一个顺序是灰盒(或隐盒)攻击,这是指对手不能直接访问模型,只能对模型的结构进行假设(Kurakin,2018)。
对人工智能系统的潜在威胁包括各种攻击模式,如中毒、规避和模型反转。中毒攻击是指污染训练数据以歪曲模型行为的攻击,例如将用户输入的数据错误地分类到AI系统中(Bae,2021)。逃避攻击并不直接影响训练数据,但有效地掩盖了它所提供的内容,使攻击对人类观察者、人工智能系统识别和分类都不可见(Bae,2021)。模型反转(偷窃)攻击发生在对手探测人工智能系统以提取有关模型配置或训练数据的信息,从而有效地重建模型(Bae,2021)。所有这三种对抗性攻击对已部署的人工智能系统构成了不同的后果,最明显的是与用户隐私和数据安全有关。
鉴于感知到的威胁和缺乏充分评估对抗性人工智能漏洞的工具,我们的工作旨在了解如何设计、开发和利用反人工智能工具,以帮助保护人工智能系统免受这些新发现的对抗性威胁载体。具体来说,我们的工作有助于并支持研究、设计和开发用于人工智能系统的对抗性T&E的反人工智能工具,供人工智能红队成员使用,以提高人工智能系统的复原力。

