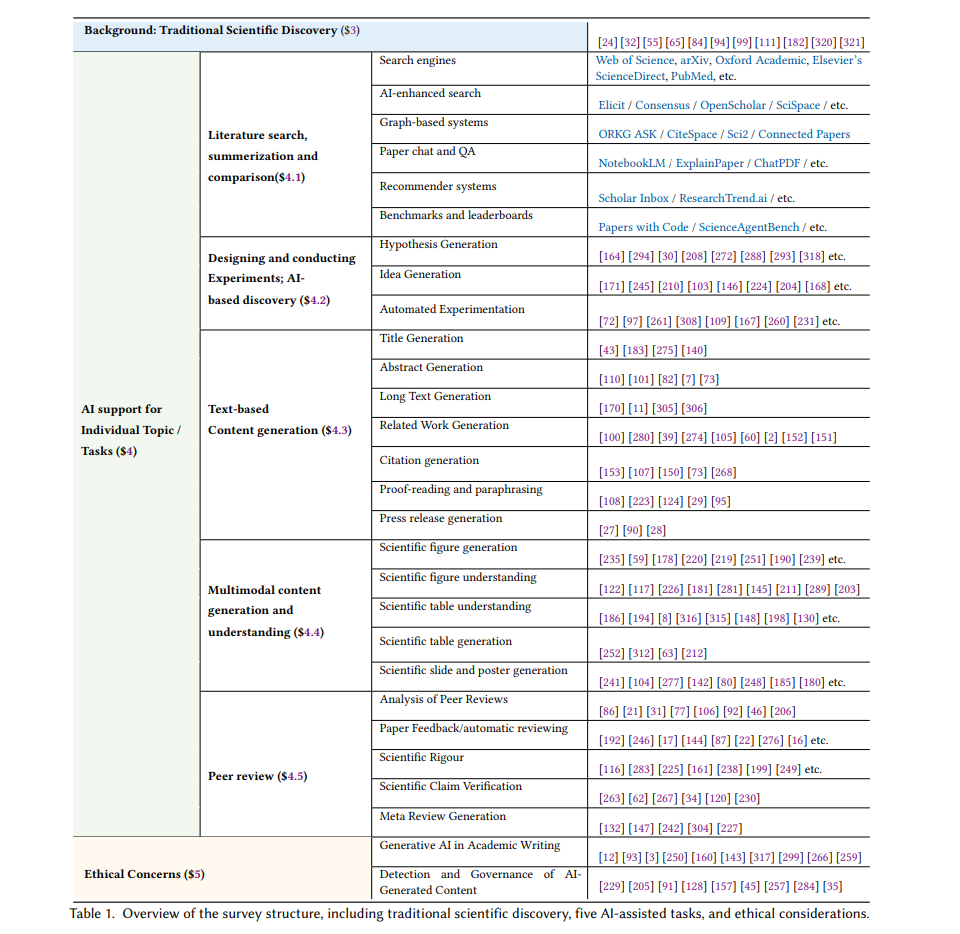
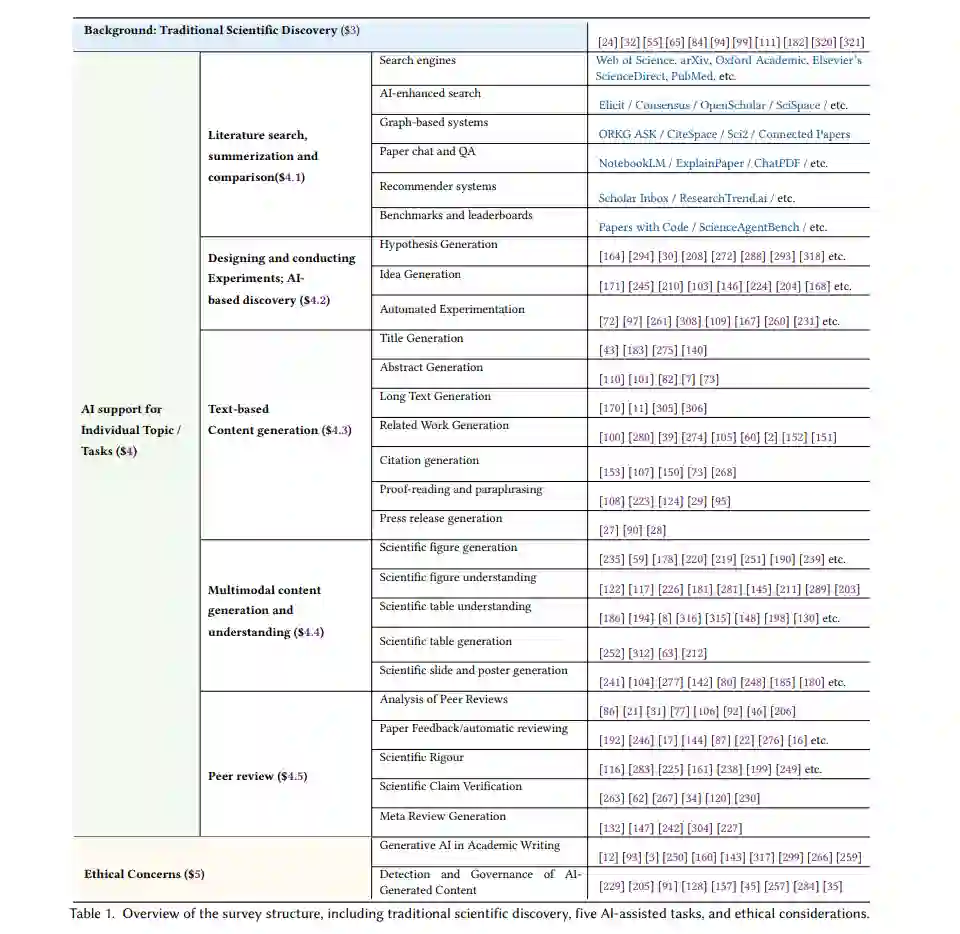
![]()
随着大型多模态语言模型的出现,科学正站在基于人工智能技术变革的门槛上。近期,涌现出大量新的人工智能模型和工具,承诺能够帮助全球的研究人员和学者更高效、更有效地开展研究。这些工具涵盖了研究周期的各个方面,尤其是:(1) 查找相关文献;(2) 生成研究想法并进行实验;(3) 生成基于文本的内容和(4) 多模态内容(例如,科学图表和图示);以及(5) 基于人工智能的自动同行评审。在本次调研中,我们深入探讨了这些令人兴奋的最新进展,它们有望从根本上改变科学研究过程。我们的调研涵盖了上述五个方面,提供了相关数据集、方法和结果(包括评估),以及局限性和未来研究的潜力。关于这些工具的不足之处及其潜在滥用(伪科学、剽窃、对研究诚信的危害)等伦理问题,特别是在我们的讨论中占据了重要位置。我们希望本次调研不仅能成为该领域新入者的参考指南,还能成为“AI4Science”领域中新的基于人工智能的创新举措的催化剂。 CCS概念: • 不要使用此代码 → 为您的论文生成正确的术语;为您的论文生成正确的术语;为您的论文生成正确的术语;为您的论文生成正确的术语。 附加关键词: 语言模型、科学、AI4Science、搜索、实验、创意生成、多模态内容生成、评估、同行评审 1. 引言
随着大型多模态基础模型的出现,如ChatGPT、Qwen、DeepSeek和Gemini等,许多研究领域和日常生活的各个领域正站在基于人工智能的技术变革的门槛上,科学也不例外。一项近期的研究分析了2018年到2024年间,约148,000篇来自22个非计算机科学领域的论文,这些论文引用了大型语言模型(LLMs),并报告了这些学科中LLMs的应用日益普及[202]。此外,美国出版公司Wiley最近对全球70多个国家近5000名研究人员进行的调查显示,尽管目前的AI应用主要限于写作辅助形式,但大多数研究人员认为AI将在未来两年内成为科学研究的主流。 传统上,科学依赖于人类的创造力和劳动来提出研究想法和假设、查找相关文献、进行实验并报告研究结果。然而,近年来,出现了大量承诺能够帮助科学家在这些任务中取得进展的AI模型、工具和功能。包括用于文献搜索的模型,如Elicit或ORKG ASK;用于实验设计的模型,如The AI Scientist [170];以及用于生成多模态科学内容的模型,如AutomaTikZ [18]和DeTikZify [19];甚至还有研究探讨这些AI模型在评估科学过程结果方面的能力,例如同行评审[302]。所有这些模型都承诺大幅加速科学研究周期,理想情况下能够带来意想不到的新发现,并为研究结果的文献编写、引用和报告提供更好的、更易用的、更准确的方式。 然而,据我们所知,目前还没有关于现有工具、模型和功能及其局限性的全面调查,能够帮助科学家加速和改进研究周期,除非是在社会科学[290]或物理学等特定子领域[310]。在本次调研中,我们填补了这一紧迫的空白,提供了关于研究周期五个核心方面的概述,在这些方面,最近出现了大量新的AI模型:第4.1节中的文献搜索(例如,查找相关文献)和内容摘要;第4.2节中的科学实验(例如,编程)和研究想法生成;第4.3节中的单模态内容生成,如草拟标题、摘要、建议引用和帮助重新表述基于文本的材料;第4.4节中的多模态内容生成与理解,如生成和理解图表、表格、幻灯片和海报;第4.5节中的AI辅助同行评审过程。Wiley的近期调查表明,这种概述对于AI研究人员在为科学过程提供更好的工具使用指南和支持方面具有重要意义,其中“63%的受访者表示,缺乏明确的指南和共识,关于在其领域中哪些AI用途被接受,和/或需要更多的培训和技能”。 在使用AI工具进行科学研究时,伦理问题至关重要。这是因为AI工具存在各种局限性,例如: (i) 它们可能产生幻觉并伪造内容;(ii) 它们可能存在偏见;(iii) 它们的推理能力可能有限;(iv) 有时缺乏适当的评估;(v) 它们可能具有较大的环境足迹,以及其他许多担忧,如伪科学、剽窃和缺乏人类权威的风险。事实上,欧盟最近发布了关于科学领域负责任使用AI的指南,指出,“研究是最可能受到生成式AI显著影响的领域之一”,“AI在加速科学发现、提高研究和验证过程的效率和进度方面具有巨大潜力”,“但这些[AI]工具可能危害研究诚信,并引发关于当前模型能否应对欺骗性科学实践和虚假信息的质疑”[5]。我们的调研对这些伦理问题给予了充分的重视,在我们覆盖的每个研究周期方面都包含了伦理关注部分,并且在第5节中有一个单独的“伦理问题”部分。 值得指出的是,我们的调研并未涵盖AI与科学关系的其他方面,例如,使用数据科学工具分析科学的研究,如“科学科学”的领域[76, 269]。 如表1所示,本文的其余部分组织结构如下:第2节讨论了我们调研的方法论;第3节简要概述了传统的科学发现与传播过程,这为第4节的内容提供了背景,第4节的每个子部分描述了AI在各个科学任务中的应用(文献搜索、实验设计、写作等)。对于每个任务,我们描述了重要的数据集、现有的先进方法和结果、伦理问题、应用领域、局限性以及未来的研究方向;第5节讨论了不特定于某个任务的伦理问题;最后,第6节总结了科学AI的优势与局限,并指出了一些未来研究的方向。 本次调研相关资源可在 https://github.com/NL2G/TransformingScienceLLMs 上访问。![]() 2. 调查方法本文提供了一个高层次的、学科背景化的调查,涵盖了人工智能在科学研究实践中的最新应用,从研究想法的初步构想到结果的传播。它旨在帮助人工智能领域(自然语言处理、计算机视觉等)的研究人员快速熟悉这一广泛且快速发展的研究领域的跨学科基础和最新发展。部分内容对政策制定者、从业者和相邻领域的研究合作者也有用,包括人机交互、图书馆和信息科学、传播研究、元科学、科学新闻和研究伦理。尽管我们既不打算提供生产就绪工具的全面目录,也不打算提供使用这些工具的实用指南,但我们所涵盖的示例可以作为任何领域的研究人员将(辅助性)AI技术纳入其研究工作流程的起点。我们相信我们的贡献是及时的,因为尽管对该主题的兴趣日益增长,但其研究人员才刚刚开始形成一个拥有专门传播场所的社区。最近的例子包括2024年或2025年首次举办的Natural Scientific Language Processing and Research Knowledge Graphs (NSLP)(Miller et al., 2020)、Foundation Models for Science (FM4Science)6、AI & Scientific Discovery (AISD)7和Towards a Knowledge-grounded Scientific Research Lifecycle (AI4Research)8等研讨会。现有的AI-for-science文献综述仅涉及孤立主题或应用领域。最早的例子(例如(Bertrand et al., 2020; Bhattacharya et al., 2020))现在已经过时,往往组织成AI用于专门任务的案例研究,如方程或药物发现。最近的调查,如(Bartlett et al., 2020),涵盖了更广泛的应用领域,但集中在科学生命周期的较窄部分,并且更倾向于AI工具的潜在用户,而不是旨在理解和推进基础数据集、方法和评估指标的AI研究人员。鉴于我们主题的广泛范围、快速进展以及对来自不同领域的知识和方法的依赖,我们选择采用叙述性方法进行调查。这种方法在选择和构建相关论文方面提供了更大的自由度[125],促进了“文献覆盖的广度和处理不断发展的知识和概念的灵活性”[25],以及“桥接相关工作领域、激发思考、启发新的理论模型并指导研究领域的未来努力”的能力[196]。系统综述虽然被认为更客观,但更适合具有明确定义的经验研究问题的相对狭窄主题(Bertrand et al., 2017)。因此,我们在本调查中引用的研究没有采用固定的纳入或排除标准,而是根据我们自己的相关性判断进行选择。在为本调查组建合著者时,我们努力包括在我们涵盖的各种子主题中积极发表的研究人员。
2. 调查方法本文提供了一个高层次的、学科背景化的调查,涵盖了人工智能在科学研究实践中的最新应用,从研究想法的初步构想到结果的传播。它旨在帮助人工智能领域(自然语言处理、计算机视觉等)的研究人员快速熟悉这一广泛且快速发展的研究领域的跨学科基础和最新发展。部分内容对政策制定者、从业者和相邻领域的研究合作者也有用,包括人机交互、图书馆和信息科学、传播研究、元科学、科学新闻和研究伦理。尽管我们既不打算提供生产就绪工具的全面目录,也不打算提供使用这些工具的实用指南,但我们所涵盖的示例可以作为任何领域的研究人员将(辅助性)AI技术纳入其研究工作流程的起点。我们相信我们的贡献是及时的,因为尽管对该主题的兴趣日益增长,但其研究人员才刚刚开始形成一个拥有专门传播场所的社区。最近的例子包括2024年或2025年首次举办的Natural Scientific Language Processing and Research Knowledge Graphs (NSLP)(Miller et al., 2020)、Foundation Models for Science (FM4Science)6、AI & Scientific Discovery (AISD)7和Towards a Knowledge-grounded Scientific Research Lifecycle (AI4Research)8等研讨会。现有的AI-for-science文献综述仅涉及孤立主题或应用领域。最早的例子(例如(Bertrand et al., 2020; Bhattacharya et al., 2020))现在已经过时,往往组织成AI用于专门任务的案例研究,如方程或药物发现。最近的调查,如(Bartlett et al., 2020),涵盖了更广泛的应用领域,但集中在科学生命周期的较窄部分,并且更倾向于AI工具的潜在用户,而不是旨在理解和推进基础数据集、方法和评估指标的AI研究人员。鉴于我们主题的广泛范围、快速进展以及对来自不同领域的知识和方法的依赖,我们选择采用叙述性方法进行调查。这种方法在选择和构建相关论文方面提供了更大的自由度[125],促进了“文献覆盖的广度和处理不断发展的知识和概念的灵活性”[25],以及“桥接相关工作领域、激发思考、启发新的理论模型并指导研究领域的未来努力”的能力[196]。系统综述虽然被认为更客观,但更适合具有明确定义的经验研究问题的相对狭窄主题(Bertrand et al., 2017)。因此,我们在本调查中引用的研究没有采用固定的纳入或排除标准,而是根据我们自己的相关性判断进行选择。在为本调查组建合著者时,我们努力包括在我们涵盖的各种子主题中积极发表的研究人员。 ![]() 3. 背景纵观历史,科学经历了许多范式转变,最终形成了今天的数据密集型探索时代(Kumar and Kumari, 2009)。尽管新工具和框架加速了科学发现的步伐,但其基本步骤几个世纪以来保持不变。如图1所示,这些步骤包括(1)研究问题或问题的构想,通常源于传播知识中的空白;(2)收集和研究与问题相关的现有文献或数据;(3)提出可证伪的假设;(4)设计和执行实验以检验这一假设;(5)分析和解释所得数据;以及(6)报告发现,允许其在现实世界中的应用或作为进一步科学循环的知识来源。关于前两个步骤,任何学者面临的主要挑战是获得并保持对给定主题现有研究的足够熟悉,以便能够识别新的研究问题或发现回答这些问题所需的知识。在20世纪之前,通常可以通过阅读所有相关书籍和期刊来跟上某一专业的发展。然而,在现代,科学出版物的数量每17年翻一番(Liu et al., 2018),使得这种详尽的方法不可行。筛选大量学术知识的需求促使简单的图书馆目录(自古代以来使用)发展为摘要期刊、书目索引和引文索引。到20世纪60年代和70年代,许多这些资源正在使用标准化控制原则和技术生产,并且可以使用自动化信息检索系统进行交互式查询(Garantie et al., 2017, pp. 88-91)。这些技术发展使得更系统地探索科学知识的方法得以广泛采用,如系统综述(Miller et al., 2018)和引文分析(Ruiz et al., 2018)。专家如何提出假设来解释观察到的现象在科学哲学和心理学中得到了广泛讨论,尽管直到最近才进行了相对较少的实证工作(Steinberg et al., 2017; Steinberg and Raffelt, 2018)。与科学推理的理想化概念相反,假设很少仅通过归纳(即从一组经验观察中抽象出一般原则)产生。相反,使用出声思维协议的案例研究表明,假设是通过逐步细化的过程生成的。这些过程可能涉及非归纳启发式(类比、简化、形象推理等),这些启发式单独使用时常常失败,但在“生成、评估和修改或拒绝的重复循环”后可能导致有效的解释模型(Steinberg and Raffelt, 2018; Steinberg and Raffelt, 2018)。实验和分析旨在建立与给定科学假设相关的自变量和因变量之间的因果关系。元科学文献中充满了关于实验设计和执行的实用建议,其中许多是特定学科的。然而,其中的一般思想可以追溯到Ronald Fisher,他在统计方法(Fisher and Fisher, 1999)和实验设计(Fisher and Fisher, 2000)方面的开创性工作普及了随机化(通过机会分配实验对象)、复制(在不同实验对象下观察相同条件)和区组(消除不希望的变化来源)的原则。除了这些考虑因素外,实验设计还涉及确定将执行的(统计)分析,并且通常受到资源可用性的限制,如时间、精力或收集和分析观察或数据的成本[126]。科学循环的最后一步,报告,涵盖了研究结果的传播,通常但不限于通过文章、书籍和演示文稿向更广泛的科学界传播。科学传播的实践本身吸引了科学研究,导致对其各种过程和策略的描述性和教学性处理(例如,[94; 300])。同行评审[282]的重要作用引起了特别关注,尽管更多关注其高级过程、其有效性和可靠性,以及其客观性和偏见,而不是评审人员如何评估手稿并传达这一评估。因此,同行评审工作流程中的技术发展直到最近才倾向于为编辑和出版商的利益管理或简化评审过程,或支持开放或协作评审[65; 282]。4. AI对个别主题/任务的支持4.1 文献搜索、总结和比较科学文献的快速增长对研究人员提出了重大挑战,他们需要高效地搜索、分析和总结大量信息。AI驱动的工具通过利用自然语言处理(NLP)、机器学习(ML)、大语言模型(LLMs)、引文图和知识图(KGs)来自动化科学信息的检索、提取和总结,正在改变这些任务。与依赖基本关键词匹配的传统搜索引擎不同,AI增强的系统提供上下文感知的语义搜索功能,检索更相关和精确的结果。这些系统不仅帮助找到相关论文,还提供结构化摘要和比较见解,帮助研究人员识别多个研究之间的空白、趋势和矛盾。广义上,科学文献的搜索系统可以分为六种主要类型:(1)搜索引擎,基于关键词查询检索文档;(2)AI增强搜索,集成NLP和ML进行高级、上下文感知的检索;(3)基于图的搜索,利用引文网络和知识图探索论文之间的关系;(4)论文聊天,实现与科学内容的交互式、对话式参与;(5)推荐系统,基于用户偏好、引文或主题建模推荐相关研究;(6)基准和排行榜,比较模型在标准化数据集和指标上的表现。在本节中,我们将讨论每种搜索系统,并提供最流行工具的概述及其关键功能。我们将从科学论文库的回顾开始,这些库是大多数科学搜索系统的数据源。4.1.1 数据科学搜索引擎依赖于庞大且多样化的出版商数据库,以提供对学术文献的全面访问。这些数据库作为文献搜索、总结和比较的基础,为研究人员提供了广泛的科学成果。了解科学出版商库的结构和类型对于评估搜索引擎在基于证据的研究中的覆盖范围、可靠性和实用性至关重要。科学出版商库可以根据其访问模式、主题焦点和内容类型进行分类。基于访问的库包括开放获取库,提供对研究文章的无限制访问(例如PubMed Central、arXiv、Europe PMC),以及需要机构或个人订阅才能访问全文内容的订阅库(例如Elsevier的ScienceDirect、SpringerLink、Wiley Online Library)。此外,混合库提供开放获取和付费内容的混合,允许研究人员免费访问一些文章,同时需要支付其他文章的费用(例如Taylor & Francis Online、Oxford Academic)。从主题焦点来看,科学库可以分为多学科库,涵盖广泛的学科(例如Web of Science、Scopus),以及特定主题库,专注于特定领域,如医学(例如PubMed)、物理学(例如INSPIRE-HEP)和社会科学(例如SSRN)。机构库由大学和研究机构管理,提供对特定组织内产生的学术工作的访问(例如MIT DSpace、Harvard DASH),而预印本库(例如bioRxiv、chemRxiv、arXiv)促进研究结果在正式同行评审之前的早期传播。政府和公共部门库,如NASA ADS和欧洲委员会的OpenAIRE,提供对公共资助研究的访问,并促进开放科学倡议。此外,数据存储库(例如Dryad、Zenodo、Figshare)专门存储研究数据集,支持透明度、可重复性和数据驱动的研究。聚合库,如BASE和CORE [127],收集和索引来自多个来源的内容,使研究人员能够跨各种学科的学术出版物进行搜索。最后,灰色文献库(例如OpenGrey、EThOS)提供对非传统研究产出的访问,如论文、报告和白皮书,这些可能无法通过传统出版商平台获得。这些库的可用性和结构显著影响搜索引擎在检索相关信息、进行系统综述和支持研究贡献的比较分析方面的有效性。在以下内容中,我们将讨论利用这些库促进文献搜索和合成的文献搜索、总结和比较系统。虽然经典学术搜索引擎如Google Scholar或AI增强搜索系统如Elicit在非常大的库中搜索(例如3亿文档),但论文聊天和问答系统如NotebookLM允许用户从较小的文章集中检索信息(例如50个PDF文档),这些文章通常由用户选择或提供。相比之下,推荐系统如Scholar Inbox根据研究人员的相关性对最近的库添加进行排名,以便为用户提供每日或每周的相关文献新闻提要。4.1.2 方法和结果在以下内容中,我们调查了当前经典和AI增强的文献搜索、总结和比较系统,并根据其主要功能将其分为六类。表2比较了这六类系统的四个关键特征。表3提供了所有系统的详细概述。搜索引擎。传统学术搜索引擎如Google Scholar、Semantic Scholar、Baidu Scholar、Science.gov和BASE以其广泛的文献覆盖、引文跟踪能力和基于关键词的搜索功能为特点。它们的主要优势包括对学术内容的广泛索引,涉及从各种来源(如出版商网站、机构库和开放获取档案)聚合和组织大量学术文档。这种全面索引涵盖多个学科和文档类型,确保用户可以访问多样化的资源。此外,这些平台提供强大的引文分析功能,允许研究人员跟踪引文数量、衡量出版物的影响,并探索引文网络以识别给定领域内有影响力的作品和新兴趋势。另一个显著优势是它们免费访问广泛的学术资源,如同行评审的期刊文章、会议论文、预印本、论文和学位论文、技术报告、书籍和书籍章节,以及灰色文献如白皮书、政府报告和机构研究产出。然而,这些搜索引擎有一定的局限性,如有限的AI驱动过滤选项和与更先进的AI增强搜索工具相比相对基本的相关性排名机制。AI增强搜索。AI增强平台如Elicit、Consensus、OpenScholar和SciSpace利用AI超越传统搜索功能,提供AI驱动的语义搜索、论文总结、证据合成和趋势分析。与主要关注基于关键词匹配检索相关文档的传统搜索引擎不同,这些工具利用NLP和机器学习算法提取关键见解,跨多个来源合成信息,并根据用户查询呈现结构化摘要。它们的一个关键优势是能够生成快速简洁的摘要,帮助研究人员节省时间并专注于文献中最相关的方面。此外,它们通过将发现分类为研究结果、方法和局限性,简化了比较和解释研究的过程。一些最新努力,如The AI Scientist(Liu et al., 2019)甚至旨在自主进行科学探索和实验。基于图的系统。基于图的系统如ORKG ASK旨在促进对科学知识的结构化访问。与传统的论文搜索引擎不同,它们利用知识图(KG)将研究贡献组织为结构化数据而非非结构化文本。这些贡献通常从摘要、引言和结果部分提取(Bai et al., 2018; Wang et al., 2020)。这些系统使用户能够提出复杂的、特定领域的问题,并从语义结构化的科学数据中合成答案。它们通常使用基于KG的推理和检索增强生成(RAG)等技术从KG中提取相关信息,提供比传统基于LLM的问答系统更可解释和可验证的答案。CiteSpace和Sci2是专门用于研究科学研究的结构和演变的文献计量分析和网络分析工具。CiteSpace专注于识别研究趋势、关键词共现网络和引文爆发,使用可视化分析突出新兴主题和有影响力的论文。Sci2是一个更通用的工具,设计用于分析学术数据集,使用户能够进行网络分析、地理空间映射和科学文献和合作模式的时间建模。Connected Papers是一种科学文献探索工具,旨在帮助研究人员基于给定的种子论文发现相关论文。与传统的基于引文的系统不同,它使用从共引和书目耦合分析得出的相似性度量构建论文图。该平台构建了一个网络,其中每个节点代表一篇论文,边表示基于共享引用和引文的相似性,而不是直接引文链接。这种方法允许用户找到可能未被直接引用但在概念上相关的论文。基于图的可视化提供了一种直观的方式来探索研究集群,识别基础和新兴作品,并跟踪科学思想的演变。4.1.3 伦理问题在科学搜索、总结和比较中使用AI引发了伦理考虑,特别是在确保透明度、问责制和公平性方面。AI可以显著加速发现的速度,自动化搜索任务,并揭示可能被人类研究人员忽视的模式,但它也引入了风险,如延续训练数据中的偏见,破坏科学过程的完整性(例如,作者身份和信用分配),以及滥用发现的可能性。现有的动态,如马太效应(知名研究人员获得不成比例的关注),可能会被算法强化,加剧不平等。我们认为,研究应遵循以人为中心的方法,其中人类研究人员被提供先进工具,但仍对执行研究和总结研究结果负全部责任。开发算法以减少偏见,根据研究内容推荐相关工作,而不考虑作者的知名度,也是重要的。能够揭示现有文献空白的工具甚至可能导致研究人员更均匀地分配到主题,减少对过度拥挤领域的偏见。4.1.4 应用领域本节讨论的搜索、总结和比较工具适用于所有科学领域。然而,所呈现的基准特定于计算机科学领域,尤其是人工智能领域。4.1.5 局限性和未来方向尽管AI驱动的学术搜索系统取得了显著进展,但仍存在一些限制其全部潜力的局限性。其中一个主要挑战是数据质量和覆盖范围的差距,因为这些系统通常难以处理不完整、非标准化或过时的数据源,这可能导致检索信息的不准确和不一致。此外,AI模型中的偏见仍然是一个关键问题,搜索和排名算法可能基于训练数据引入偏见,可能影响某些研究领域的可见性,并限制呈现给用户的观点的多样性。另一个主要限制在于可扩展性和实时处理,因为高效处理大规模数据集同时保持低延迟和高检索准确性仍然是一个技术挑战。解决这些局限性开辟了几个有希望的未来方向。一个潜在的途径是增强个性化,通过适应用户偏好,根据研究兴趣和行为模式提供更量身定制的推荐。最后,通过将AI驱动的搜索系统与其他数字工具(如数据可视化平台和研究管理软件)集成,促进跨学科合作,可以实现更全面和深入的研究成果。解决这些挑战并探索未来方向对于实现AI驱动的学术搜索和合成的全部潜力至关重要。
3. 背景纵观历史,科学经历了许多范式转变,最终形成了今天的数据密集型探索时代(Kumar and Kumari, 2009)。尽管新工具和框架加速了科学发现的步伐,但其基本步骤几个世纪以来保持不变。如图1所示,这些步骤包括(1)研究问题或问题的构想,通常源于传播知识中的空白;(2)收集和研究与问题相关的现有文献或数据;(3)提出可证伪的假设;(4)设计和执行实验以检验这一假设;(5)分析和解释所得数据;以及(6)报告发现,允许其在现实世界中的应用或作为进一步科学循环的知识来源。关于前两个步骤,任何学者面临的主要挑战是获得并保持对给定主题现有研究的足够熟悉,以便能够识别新的研究问题或发现回答这些问题所需的知识。在20世纪之前,通常可以通过阅读所有相关书籍和期刊来跟上某一专业的发展。然而,在现代,科学出版物的数量每17年翻一番(Liu et al., 2018),使得这种详尽的方法不可行。筛选大量学术知识的需求促使简单的图书馆目录(自古代以来使用)发展为摘要期刊、书目索引和引文索引。到20世纪60年代和70年代,许多这些资源正在使用标准化控制原则和技术生产,并且可以使用自动化信息检索系统进行交互式查询(Garantie et al., 2017, pp. 88-91)。这些技术发展使得更系统地探索科学知识的方法得以广泛采用,如系统综述(Miller et al., 2018)和引文分析(Ruiz et al., 2018)。专家如何提出假设来解释观察到的现象在科学哲学和心理学中得到了广泛讨论,尽管直到最近才进行了相对较少的实证工作(Steinberg et al., 2017; Steinberg and Raffelt, 2018)。与科学推理的理想化概念相反,假设很少仅通过归纳(即从一组经验观察中抽象出一般原则)产生。相反,使用出声思维协议的案例研究表明,假设是通过逐步细化的过程生成的。这些过程可能涉及非归纳启发式(类比、简化、形象推理等),这些启发式单独使用时常常失败,但在“生成、评估和修改或拒绝的重复循环”后可能导致有效的解释模型(Steinberg and Raffelt, 2018; Steinberg and Raffelt, 2018)。实验和分析旨在建立与给定科学假设相关的自变量和因变量之间的因果关系。元科学文献中充满了关于实验设计和执行的实用建议,其中许多是特定学科的。然而,其中的一般思想可以追溯到Ronald Fisher,他在统计方法(Fisher and Fisher, 1999)和实验设计(Fisher and Fisher, 2000)方面的开创性工作普及了随机化(通过机会分配实验对象)、复制(在不同实验对象下观察相同条件)和区组(消除不希望的变化来源)的原则。除了这些考虑因素外,实验设计还涉及确定将执行的(统计)分析,并且通常受到资源可用性的限制,如时间、精力或收集和分析观察或数据的成本[126]。科学循环的最后一步,报告,涵盖了研究结果的传播,通常但不限于通过文章、书籍和演示文稿向更广泛的科学界传播。科学传播的实践本身吸引了科学研究,导致对其各种过程和策略的描述性和教学性处理(例如,[94; 300])。同行评审[282]的重要作用引起了特别关注,尽管更多关注其高级过程、其有效性和可靠性,以及其客观性和偏见,而不是评审人员如何评估手稿并传达这一评估。因此,同行评审工作流程中的技术发展直到最近才倾向于为编辑和出版商的利益管理或简化评审过程,或支持开放或协作评审[65; 282]。4. AI对个别主题/任务的支持4.1 文献搜索、总结和比较科学文献的快速增长对研究人员提出了重大挑战,他们需要高效地搜索、分析和总结大量信息。AI驱动的工具通过利用自然语言处理(NLP)、机器学习(ML)、大语言模型(LLMs)、引文图和知识图(KGs)来自动化科学信息的检索、提取和总结,正在改变这些任务。与依赖基本关键词匹配的传统搜索引擎不同,AI增强的系统提供上下文感知的语义搜索功能,检索更相关和精确的结果。这些系统不仅帮助找到相关论文,还提供结构化摘要和比较见解,帮助研究人员识别多个研究之间的空白、趋势和矛盾。广义上,科学文献的搜索系统可以分为六种主要类型:(1)搜索引擎,基于关键词查询检索文档;(2)AI增强搜索,集成NLP和ML进行高级、上下文感知的检索;(3)基于图的搜索,利用引文网络和知识图探索论文之间的关系;(4)论文聊天,实现与科学内容的交互式、对话式参与;(5)推荐系统,基于用户偏好、引文或主题建模推荐相关研究;(6)基准和排行榜,比较模型在标准化数据集和指标上的表现。在本节中,我们将讨论每种搜索系统,并提供最流行工具的概述及其关键功能。我们将从科学论文库的回顾开始,这些库是大多数科学搜索系统的数据源。4.1.1 数据科学搜索引擎依赖于庞大且多样化的出版商数据库,以提供对学术文献的全面访问。这些数据库作为文献搜索、总结和比较的基础,为研究人员提供了广泛的科学成果。了解科学出版商库的结构和类型对于评估搜索引擎在基于证据的研究中的覆盖范围、可靠性和实用性至关重要。科学出版商库可以根据其访问模式、主题焦点和内容类型进行分类。基于访问的库包括开放获取库,提供对研究文章的无限制访问(例如PubMed Central、arXiv、Europe PMC),以及需要机构或个人订阅才能访问全文内容的订阅库(例如Elsevier的ScienceDirect、SpringerLink、Wiley Online Library)。此外,混合库提供开放获取和付费内容的混合,允许研究人员免费访问一些文章,同时需要支付其他文章的费用(例如Taylor & Francis Online、Oxford Academic)。从主题焦点来看,科学库可以分为多学科库,涵盖广泛的学科(例如Web of Science、Scopus),以及特定主题库,专注于特定领域,如医学(例如PubMed)、物理学(例如INSPIRE-HEP)和社会科学(例如SSRN)。机构库由大学和研究机构管理,提供对特定组织内产生的学术工作的访问(例如MIT DSpace、Harvard DASH),而预印本库(例如bioRxiv、chemRxiv、arXiv)促进研究结果在正式同行评审之前的早期传播。政府和公共部门库,如NASA ADS和欧洲委员会的OpenAIRE,提供对公共资助研究的访问,并促进开放科学倡议。此外,数据存储库(例如Dryad、Zenodo、Figshare)专门存储研究数据集,支持透明度、可重复性和数据驱动的研究。聚合库,如BASE和CORE [127],收集和索引来自多个来源的内容,使研究人员能够跨各种学科的学术出版物进行搜索。最后,灰色文献库(例如OpenGrey、EThOS)提供对非传统研究产出的访问,如论文、报告和白皮书,这些可能无法通过传统出版商平台获得。这些库的可用性和结构显著影响搜索引擎在检索相关信息、进行系统综述和支持研究贡献的比较分析方面的有效性。在以下内容中,我们将讨论利用这些库促进文献搜索和合成的文献搜索、总结和比较系统。虽然经典学术搜索引擎如Google Scholar或AI增强搜索系统如Elicit在非常大的库中搜索(例如3亿文档),但论文聊天和问答系统如NotebookLM允许用户从较小的文章集中检索信息(例如50个PDF文档),这些文章通常由用户选择或提供。相比之下,推荐系统如Scholar Inbox根据研究人员的相关性对最近的库添加进行排名,以便为用户提供每日或每周的相关文献新闻提要。4.1.2 方法和结果在以下内容中,我们调查了当前经典和AI增强的文献搜索、总结和比较系统,并根据其主要功能将其分为六类。表2比较了这六类系统的四个关键特征。表3提供了所有系统的详细概述。搜索引擎。传统学术搜索引擎如Google Scholar、Semantic Scholar、Baidu Scholar、Science.gov和BASE以其广泛的文献覆盖、引文跟踪能力和基于关键词的搜索功能为特点。它们的主要优势包括对学术内容的广泛索引,涉及从各种来源(如出版商网站、机构库和开放获取档案)聚合和组织大量学术文档。这种全面索引涵盖多个学科和文档类型,确保用户可以访问多样化的资源。此外,这些平台提供强大的引文分析功能,允许研究人员跟踪引文数量、衡量出版物的影响,并探索引文网络以识别给定领域内有影响力的作品和新兴趋势。另一个显著优势是它们免费访问广泛的学术资源,如同行评审的期刊文章、会议论文、预印本、论文和学位论文、技术报告、书籍和书籍章节,以及灰色文献如白皮书、政府报告和机构研究产出。然而,这些搜索引擎有一定的局限性,如有限的AI驱动过滤选项和与更先进的AI增强搜索工具相比相对基本的相关性排名机制。AI增强搜索。AI增强平台如Elicit、Consensus、OpenScholar和SciSpace利用AI超越传统搜索功能,提供AI驱动的语义搜索、论文总结、证据合成和趋势分析。与主要关注基于关键词匹配检索相关文档的传统搜索引擎不同,这些工具利用NLP和机器学习算法提取关键见解,跨多个来源合成信息,并根据用户查询呈现结构化摘要。它们的一个关键优势是能够生成快速简洁的摘要,帮助研究人员节省时间并专注于文献中最相关的方面。此外,它们通过将发现分类为研究结果、方法和局限性,简化了比较和解释研究的过程。一些最新努力,如The AI Scientist(Liu et al., 2019)甚至旨在自主进行科学探索和实验。基于图的系统。基于图的系统如ORKG ASK旨在促进对科学知识的结构化访问。与传统的论文搜索引擎不同,它们利用知识图(KG)将研究贡献组织为结构化数据而非非结构化文本。这些贡献通常从摘要、引言和结果部分提取(Bai et al., 2018; Wang et al., 2020)。这些系统使用户能够提出复杂的、特定领域的问题,并从语义结构化的科学数据中合成答案。它们通常使用基于KG的推理和检索增强生成(RAG)等技术从KG中提取相关信息,提供比传统基于LLM的问答系统更可解释和可验证的答案。CiteSpace和Sci2是专门用于研究科学研究的结构和演变的文献计量分析和网络分析工具。CiteSpace专注于识别研究趋势、关键词共现网络和引文爆发,使用可视化分析突出新兴主题和有影响力的论文。Sci2是一个更通用的工具,设计用于分析学术数据集,使用户能够进行网络分析、地理空间映射和科学文献和合作模式的时间建模。Connected Papers是一种科学文献探索工具,旨在帮助研究人员基于给定的种子论文发现相关论文。与传统的基于引文的系统不同,它使用从共引和书目耦合分析得出的相似性度量构建论文图。该平台构建了一个网络,其中每个节点代表一篇论文,边表示基于共享引用和引文的相似性,而不是直接引文链接。这种方法允许用户找到可能未被直接引用但在概念上相关的论文。基于图的可视化提供了一种直观的方式来探索研究集群,识别基础和新兴作品,并跟踪科学思想的演变。4.1.3 伦理问题在科学搜索、总结和比较中使用AI引发了伦理考虑,特别是在确保透明度、问责制和公平性方面。AI可以显著加速发现的速度,自动化搜索任务,并揭示可能被人类研究人员忽视的模式,但它也引入了风险,如延续训练数据中的偏见,破坏科学过程的完整性(例如,作者身份和信用分配),以及滥用发现的可能性。现有的动态,如马太效应(知名研究人员获得不成比例的关注),可能会被算法强化,加剧不平等。我们认为,研究应遵循以人为中心的方法,其中人类研究人员被提供先进工具,但仍对执行研究和总结研究结果负全部责任。开发算法以减少偏见,根据研究内容推荐相关工作,而不考虑作者的知名度,也是重要的。能够揭示现有文献空白的工具甚至可能导致研究人员更均匀地分配到主题,减少对过度拥挤领域的偏见。4.1.4 应用领域本节讨论的搜索、总结和比较工具适用于所有科学领域。然而,所呈现的基准特定于计算机科学领域,尤其是人工智能领域。4.1.5 局限性和未来方向尽管AI驱动的学术搜索系统取得了显著进展,但仍存在一些限制其全部潜力的局限性。其中一个主要挑战是数据质量和覆盖范围的差距,因为这些系统通常难以处理不完整、非标准化或过时的数据源,这可能导致检索信息的不准确和不一致。此外,AI模型中的偏见仍然是一个关键问题,搜索和排名算法可能基于训练数据引入偏见,可能影响某些研究领域的可见性,并限制呈现给用户的观点的多样性。另一个主要限制在于可扩展性和实时处理,因为高效处理大规模数据集同时保持低延迟和高检索准确性仍然是一个技术挑战。解决这些局限性开辟了几个有希望的未来方向。一个潜在的途径是增强个性化,通过适应用户偏好,根据研究兴趣和行为模式提供更量身定制的推荐。最后,通过将AI驱动的搜索系统与其他数字工具(如数据可视化平台和研究管理软件)集成,促进跨学科合作,可以实现更全面和深入的研究成果。解决这些挑战并探索未来方向对于实现AI驱动的学术搜索和合成的全部潜力至关重要。
![]()
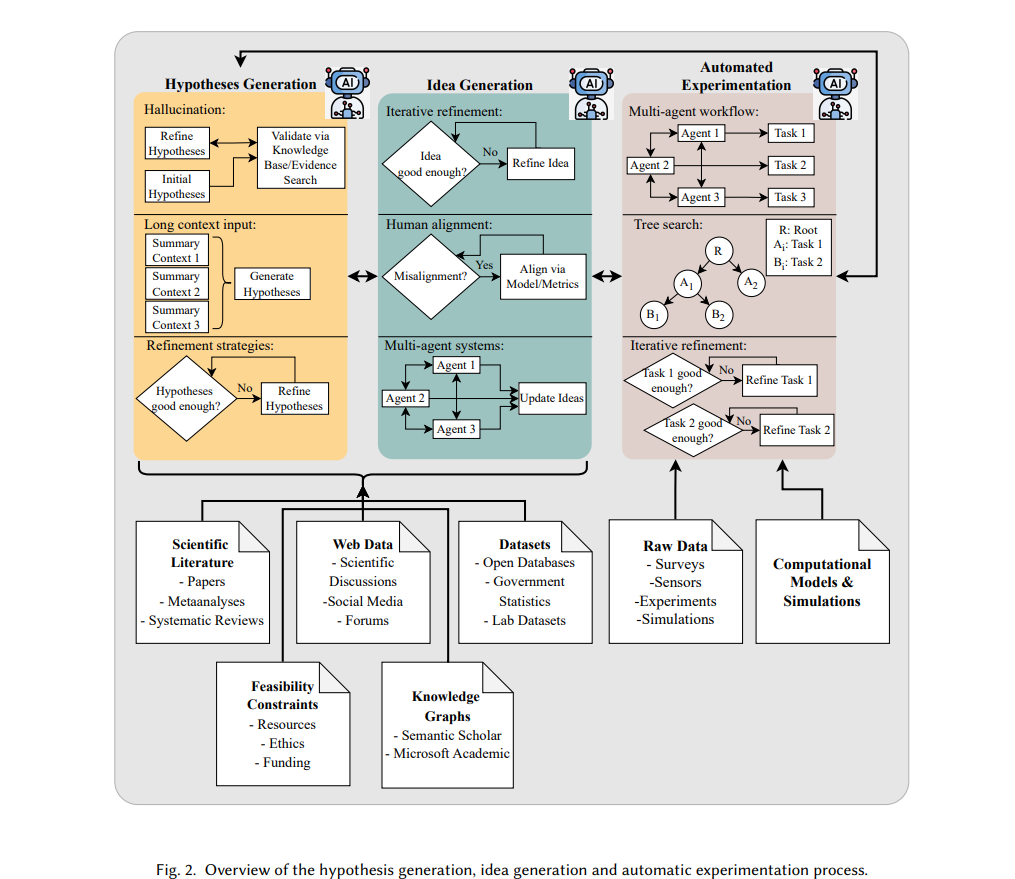
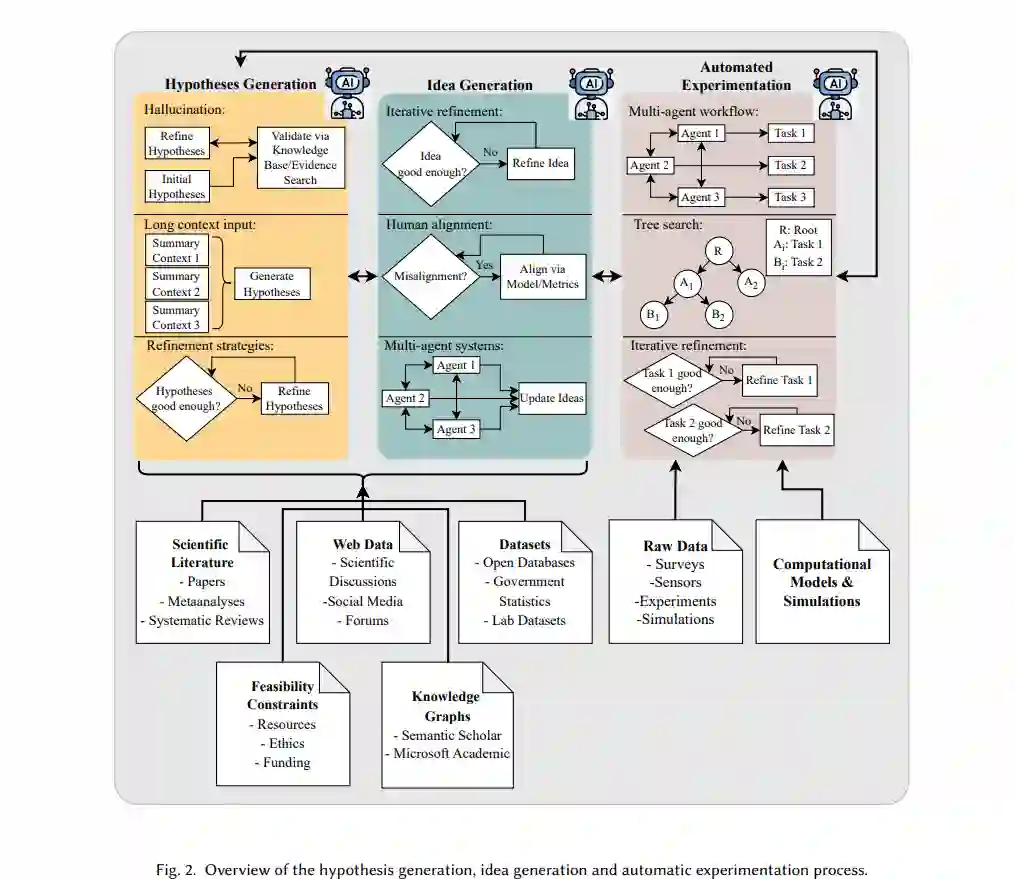
4.2 设计和进行实验;基于AI的发现假设生成、创意形成和实验是科学发现中的关键步骤。假设生成涉及提出具体且可验证的问题,这些问题为实证或理论的论证提供灵感;而创意形成,特别是在AI领域,侧重于提出新工具或对现有工具进行基准测试。实验则通过系统的观察、数据收集和分析来检验假设并评估创意。在AI中,这通常包括模型基准测试、运行仿真或进行消融研究。传统上,这些过程由人类研究人员完成。然而,在科学产出快速增长的时代,文献回顾到假设和创意形成的转变已变得非常耗时,尤其对于各学科的研究人员来说,鉴于他们在审阅日益增多的相关文献时的有限能力,这可能会阻碍科学进展。实验本身也引入了更多挑战,例如设计方法论、运行大规模仿真和分析结果。这些复杂性可能会减缓科学进展,尤其是在需要多次迭代以精炼实验结果时。最近,越来越多的研究开始关注大型语言模型(LLMs)在假设生成和创意形成中的潜力,因为LLMs能够高效处理和综合大量文献。除此之外,LLMs还可以与计算工具结合,支持自动化实验,在实验设计、仿真执行和结果分析中提供帮助。然后,基于这些发现,可以迭代地优化假设,形成反馈循环,从而加速发现过程。在本节中,我们将概述基于AI的假设生成、创意形成和实验过程。每个部分的回顾将集中在其数据集、方法、结果、局限性、伦理问题等方面。4.3 基于文本的内容生成在科学领域的基于文本的内容生成中,我们涵盖了生成科学论文特定文本部分的不同任务,例如自动生成:(i) 标题;(ii) 摘要;(iii) 相关工作部分;以及 (iv) 引用生成。此外,我们还将讨论使用AI系统进行的校对和释义重写,以及新闻稿生成。4.4 多模态内容生成与理解在科学领域,多模态内容生成指的是生成科学论文中的多模态科学内容,如图表和表格,或例如在发布后过程中的幻灯片和海报。通过AI自动化这些任务至少有三个重要原因:(i) 生成高质量的图表、表格、幻灯片和海报对于人类作者来说是困难且耗时的(维度:成本);(ii) 论文中高质量的多模态内容可以对引用或接受决策产生较大影响(维度:对作者的益处)[138];(iii) 表格、图形、海报和幻灯片使科学内容更容易被科学受众获取,并且通常代表了研究结果的简明表达(维度:对读者的益处)。多模态科学内容理解则指的是理解科学图像和表格(这通常需要推理过程),例如,回答有关多模态科学内容的问题,为科学图表和表格提供标题或总结。自动化这一理解过程有望实现自动描述这些多模态对象,这同样是耗时且成本高昂的工作,能够帮助读者更轻松地理解内容(例如,允许提出任何问题)。
结论
本文调研了AI4Science领域中的方法,特别关注了基于大型语言模型的最新方法。我们考察了研究周期中的五个关键方面:(1) 文献搜索,(2) 实验与研究创意生成,(3) 基于文本的内容生成,(4) 多模态内容生成,以及(5) 同行评审。针对每个主题,我们讨论了相关的数据集、方法和结果,包括评估策略,并突出指出了局限性和未来研究的方向。鉴于AI辅助内容生成的潜在滥用和维护科学诚信的挑战,伦理问题在我们的调研中占据了重要位置。 我们希望本次调研能够激发AI4Science领域的新举措,推动更快速、更高效、更具包容性的科学发现、实验、报告和内容合成,同时坚守最高的伦理标准。科学的终极目标是服务于人类,我们希望这些进展能够加速知识的创造,增强研究的可及性和可靠性,从而带来改善医疗健康、医疗治疗、经济流程等一系列社会效益。