
转载“竹言见智” 为什么机器人技术远远落后于 NLP、视觉和其他 AI 领域?除其他困难外,数据短缺是罪魁祸首。谷歌 DeepMind 联合其他机构推出了 Open X-Embodiment 数据集,并训练出了能力更强的 RT-X 模型。
在大模型不断取得突破的 2023,把大模型当做大脑来辅助运行的具身智能机器人研究也在被迅速推进。
2 个多月前,谷歌 DeepMind 推出了第一个控制机器人的视觉 - 语言 - 动作(VLA)模型 ——RT-2。这个模型让机器人不仅能解读人类的复杂指令,还能看懂眼前的物体(即使这个物体之前从未见过),并按照指令采取动作。比如,你让机器人拿起桌上「已灭绝的动物」。它会抓起眼前的恐龙玩偶。

当时,一位谷歌高管称,RT-2 是机器人制造和编程方式的重大飞跃。「由于这一变化,我们不得不重新考虑我们的整个研究规划了。」 更令人吃惊的是,时间仅仅过去了两个多月,DeepMind 的这个机器人模型又进步了,而且一下就提高了两倍。 这是怎么实现的呢? 我们知道,机器人通常在做某一件事情上非常专业,但通用能力很差。一般情况下,你必须针对每项任务、每个机器人和环境训练一个模型。改变一个变量往往需要从头开始。但是,如果我们能将各种机器人学的知识结合起来,创造出一种训练通用机器人的方法呢? 这就是 DeepMind 在过去一段时间所做的事情。他们汇集了来自 22 种不同机器人类型的数据,以创建 Open X-Embodiment 数据集,然后在之前的模型(RT-1 和 RT-2)的基础上,训练出了能力更强的 RT-X(分别为 RT-1-X 和 RT-2-X)。 他们在五个不同的研究实验室测试了 RT-1-X 模型,结果显示,与针对每个机器人独立开发的方法相比,新方法在五种不同的常用机器人中平均成功率提高了 50%。他们还表明,在上述数据集上训练的 RT-2-X 在现实世界机器人技能上的表现提高了 2 倍,而且,通过学习新数据,RT-2-X 掌握了很多新技能。这项工作表明,在来自多个机器人类型数据上训练的单个模型比在来自单个机器人类型数据上训练的模型在多个机器人上的性能要好得多。

值得一提的是,这项研究并非由 DeepMind 独立完成,而是他们与 33 家学术实验室通力合作的结果。他们致力于以开放和负责任的方式开发这项技术。

目前,Open X-Embodiment 数据集和 RT-1-X 模型检查点已经对广泛的研究社区开放。
英伟达高级人工智能科学家Jim Fan表示今天可能是机器人的ImageNet时刻。

谷歌研究员Karol Hausman也表达了同样的感叹:机器人的ImageNet时刻终于到来了。
Open X-Embodiment 数据集,机器人的 ImageNet 时刻
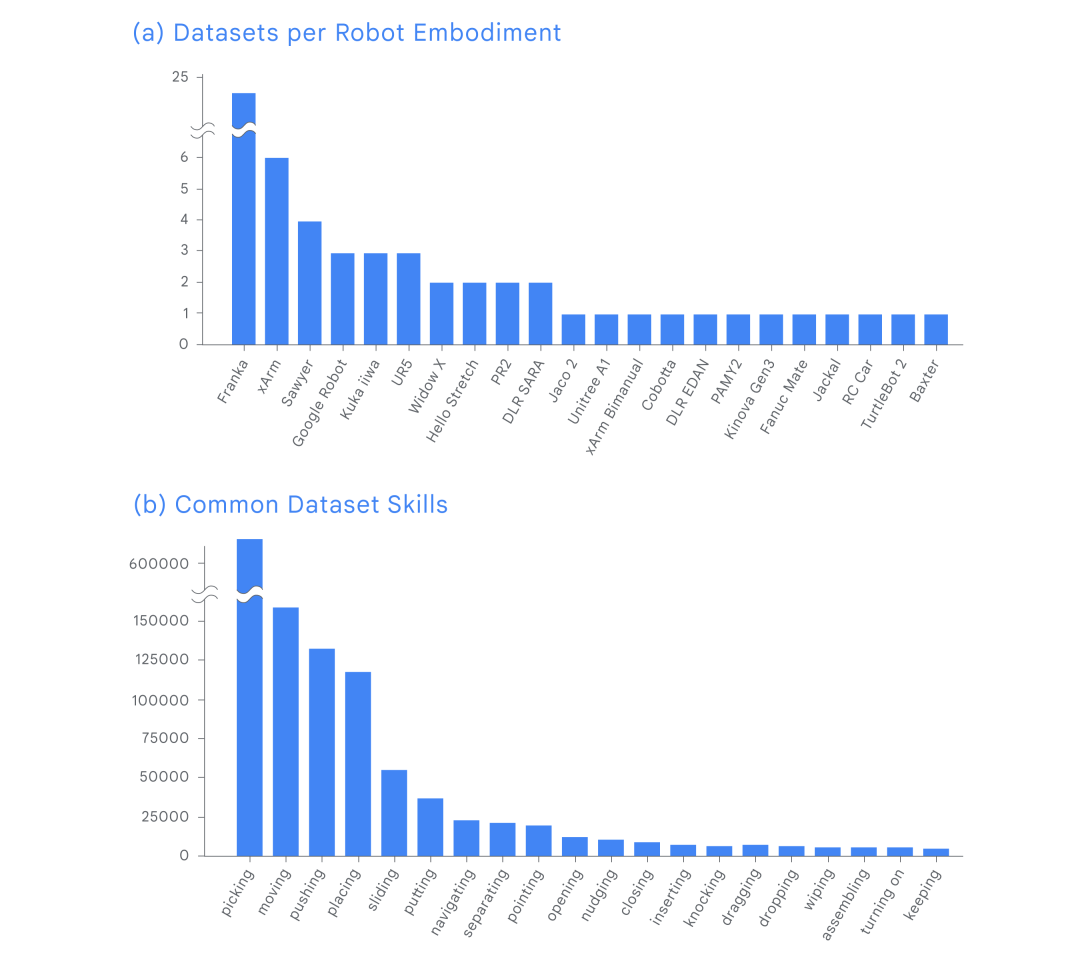
数据集以及基于数据集训练的模型在推进 AI 进步方面发挥了关键作用。正如 ImageNet 推动了计算机视觉的研究,Open X-Embodiment 同样推动了机器人技术的发展。 一直以来,构建多样化数据集是训练通用模型的关键,这些训练好的模型可以控制许多不同类型的机器人,遵循不同的指令,对复杂任务进行基本推理,并有效地进行泛化。然而,对于任何单个实验室来说,收集这样的数据集都过于耗费资源。 为此,DeepMind 与 33 家机构的学术研究实验室展开合作,从而构建了 Open X-Embodiment 数据集。他们从 22 个机器人实例中收集数据,这些数据涵盖超过 100 万个片段,展示了机器人 500 多项技能和在 150000 项任务上的表现。该数据集是同类中最全面的机器人数据集。 
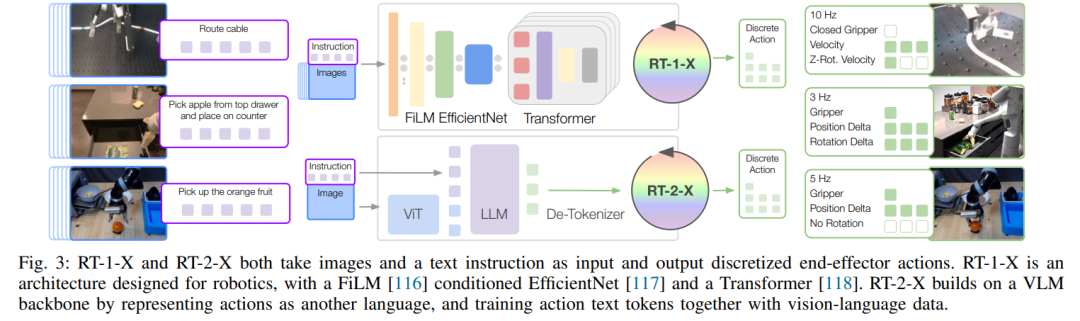
RT-X 基于两个 robotics transformer(RT)模型构建而成。 具体而言,他们使用 RT-1 训练 RT-1-X,其中 RT-1 是建立在 Transformer 架构上的 35M 参数网络,专为机器人控制而设计,如图 3 所示。 此外,他们还在 RT-2 上训练 RT-2-X,其中 RT-2 是一系列大型视觉语言动作模型 (VLA),在互联网规模的视觉和语言数据以及机器人控制数据上训练而成。
为了评估 RT-1-X,DeepMind 将其与在特定任务上(例如开门)开发的模型进行了比较。结果显示,使用 Open X-Embodiment 数据集训练的 RT-1-X 平均性能优于原始模型 50%。 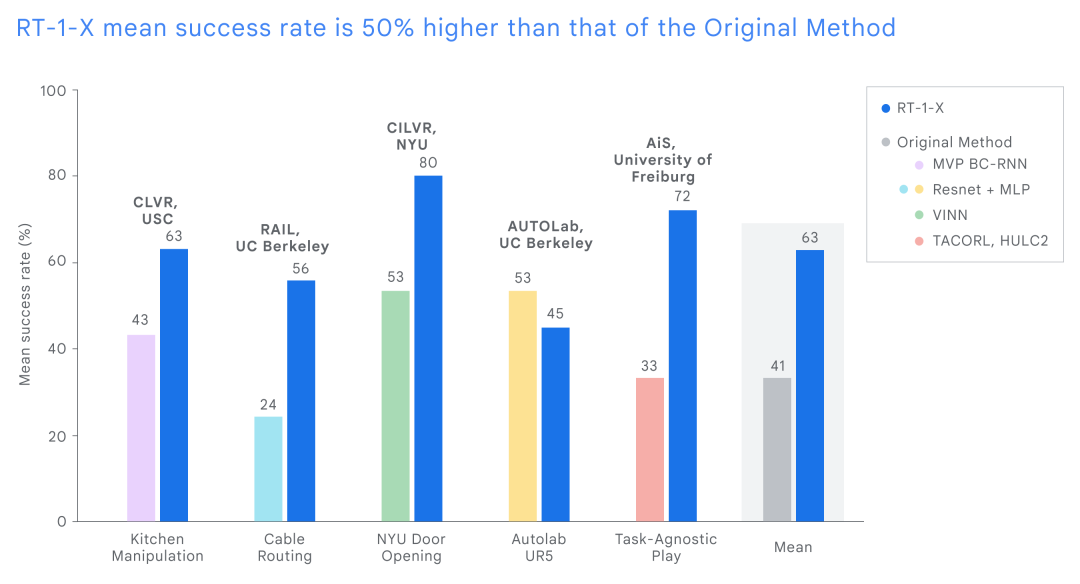

为了研究 RT-X 的知识迁移能力,DeepMind 又进行了其他实验。这些实验涉及 RT-2 数据集中不存在的对象和技能,但这些对象和技能存在于另一个机器人的数据集中。结果表明,在掌握新技能方面,RT-2-X 的成功率是其之前的最佳模型 RT-2 的三倍。这也说明了,与其他平台的数据进行联合训练可以为 RT-2-X 赋予原始数据集中不存在的额外技能,使其能够执行新颖的任务。 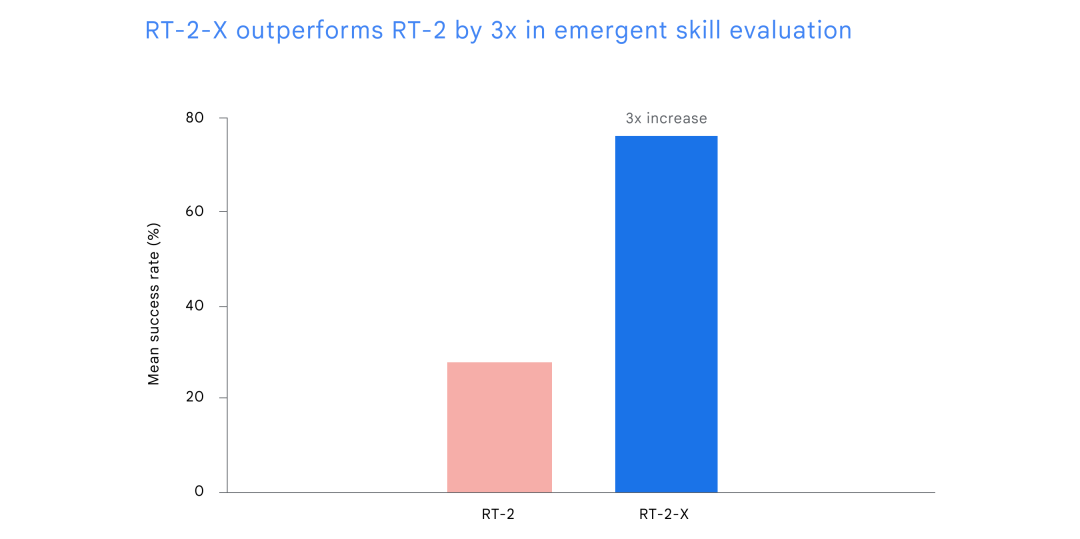

一系列结果表明,RT-2-X 实现了 RT-2 以前无法实现的技能,包括对空间更好的理解。例如,如果我们要求机器人「将苹果移动到布料附近」、又或者要求机器人「将苹果移动到布料上」,为了实现目标要求,机器人会采取完全不同的轨迹。只需将介词从「near」更改为「on」,就可以调整机器人采取的动作。 RT-2-X 表明,将其他机器人的数据结合到 RT-2-X 训练中可以改善机器人的任务执行范围,但前提是使用足够高容量的架构。

研究启发:机器人需要相互学习,研究人员也一样
机器人研究正处于令人兴奋的早期阶段。DeepMind 的这项新研究表明,通过利用更多样化的数据和更好的模型进行扩展学习,有可能开发出更有用的辅助机器人。与世界各地的实验室合作并共享资源,对于以开放和负责任的方式推进机器人研究至关重要。DeepMind 希望通过开放数据源和提供安全但有限的模型来减少障碍,加快研究。机器人技术的未来有赖于机器人之间的相互学习,最重要的是,让研究人员能够相互学习。 这项工作证明,模型可以在不同环境下通用,无论是在谷歌 DeepMind 的机器人上,还是在世界各地不同大学的机器人上,其性能都得到了显著提高。未来的研究可以探索如何将这些进步与 RoboCat 的自我完善特性相结合,使模型能够根据自身经验不断改进。未来的另一个方向是进一步探索不同数据集的混合会如何影响跨具身智能体泛化,以及这种泛化是如何是实现的。 如果你想了解有关 RT-X 的更多信息,可以参考 DeepMind 发布的这篇论文:

