

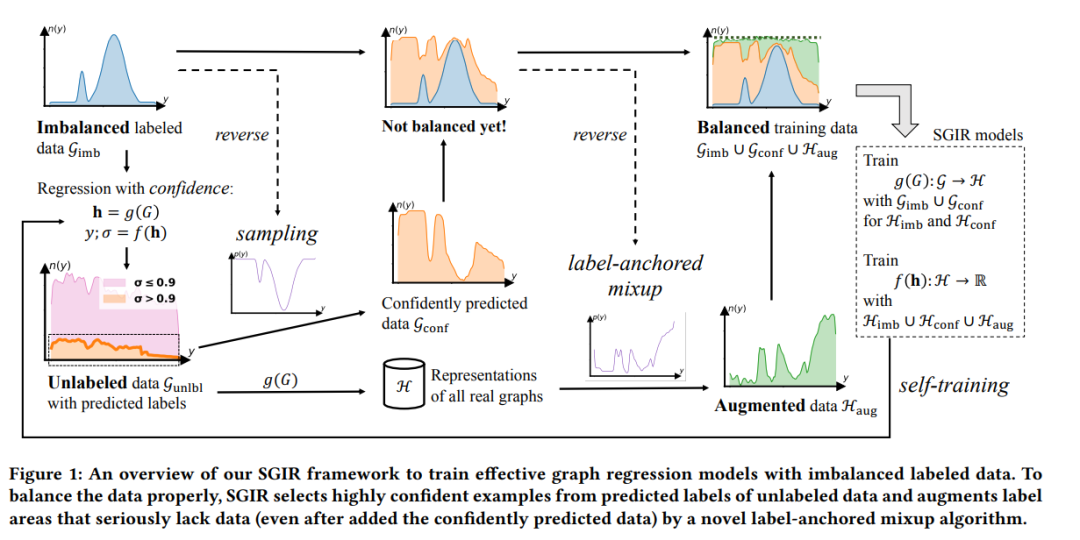
在回归任务中,当某些连续标签值的观测难以收集时,数据不平衡容易出现在带注释的数据中。当涉及到分子和聚合物属性预测时,带注释的图形数据集通常很小,因为标记它们需要昂贵的设备和努力。为解决图形回归任务中稀有标签值的示例不足的问题,我们提出了一个半监督框架,通过自我训练逐步平衡训练数据并减少模型偏差。训练数据的平衡是通过(1)使用新的回归置信度测量为代表性不足的标签给更多的图形贴上伪标签,和(2)在用伪标签平衡数据后,为剩余的稀有标签在潜在空间中增加图形示例来实现的。前者是为了从标签被自信地预测的未标记数据中识别出质量示例,并从不平衡的带注释的数据中按照反向分布抽取一部分。后者与前者协作,使用新的标签锚定混合算法,以达到完美的平衡。我们在图数据集上对七个回归任务进行了实验。结果表明,提出的框架显著减少了预测图属性的错误,特别是在代表性不足的标签区域。
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2023年7月10日
Arxiv
0+阅读 · 2023年7月8日
Arxiv
0+阅读 · 2023年7月7日
Arxiv
0+阅读 · 2023年7月7日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年7月10日
Arxiv
0+阅读 · 2023年7月8日
Arxiv
0+阅读 · 2023年7月7日
Arxiv
0+阅读 · 2023年7月7日