1 引言
目标检测是计****算机视觉中的一项基础任务,涉及识别和定位图像或视频中的目标。它包含多个细分领域:通用目标检测(GOD)[1]–[4]、显著目标检测(SOD)[5]–[7]和伪装目标检测(COD)[8]–[10]。GOD的目标是检测一般对象,而SOD识别那些从背景中突显出来的显著对象。相比之下,COD针对的是那些与周围环境融合在一起的目标,这使得它成为一项极具挑战性的任务。图1展示了GOD、SOD和COD任务中目标狗与背景的关系,这些图像来自经典数据集[11]–[13]。近年来,COD因其在促进视觉感知的细微差别识别方面的优势,以及在实际生活应用中广泛的价值,如工业中的隐蔽缺陷检测[14]、农业中的害虫监测[15]、[16]、医学诊断中的病灶分割[17]以及艺术领域,如娱乐艺术[18]和照片真实感融合[19],而获得了越来越多的关注和快速发展。然而,与GOD和SOD不同,COD涉及检测那些被设计成难以察觉的目标,如图1右侧的斑点狗因与周围环境伪装在一起而难以检测到,这需要更为复杂的检测策略。COD可进一步分为图像和视频任务[20]、[21]。普通的COD,即图像级别COD,用于检测静态图像中的伪装目标,而视频级别COD,称为VCOD,则用于检测视频序列中的这些目标。后者由于时间连续性和动态变化的引入而增加了复杂性,要求模型能够有效地提取空间和时间特征。
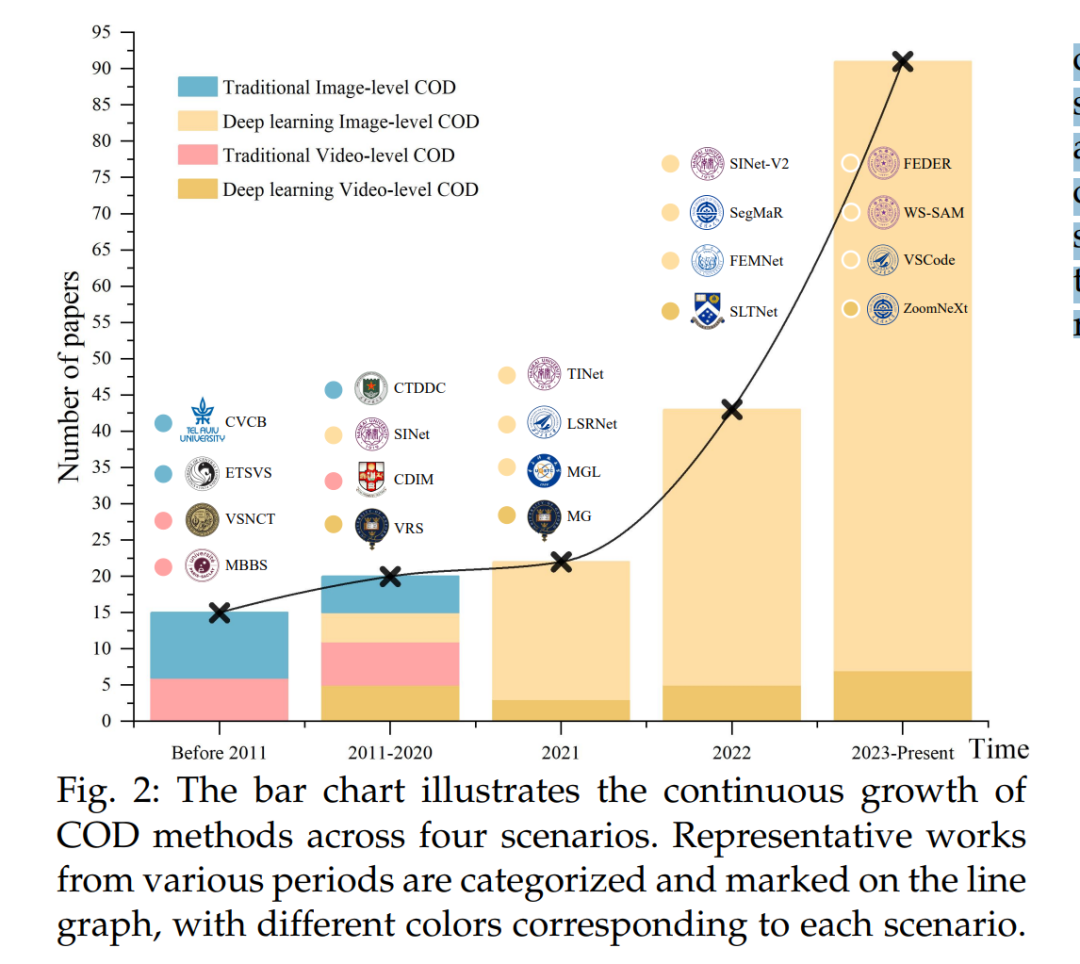
传统的COD和VCOD方法,包括纹理[22]、强度[23]、颜色[24]、运动[25]、光流[26]和多模态分析[27],在特定场景中展示了它们的优势,但也表现出明显的缺陷。这些依赖于手工设计操作符的方法在特征提取能力上有限,因此在处理复杂背景和变化的目标外观时,准确性和鲁棒性受到了限制。相比之下,基于深度学习的COD方法,如卷积神经网络(CNN)、变换器(Transformer)和扩散模型(Diffusion Model),通过自动学习丰富的特征表示,提供了显著优势[8]、[10]。此外,这些方法采用了多种策略来应对这一挑战性任务,例如,多尺度特征聚合[28]–[32]、仿生机制模拟[13]、[20]、[33]–[37]、多源信息融合[10]、[15]、[38]–[40]、多任务学习[9]、[41]–[44]、联合SOD[40]、[45]–[47]以及新任务设定[48]–[52]。尽管这些方法具有优势,但也面临难以克服的挑战,包括高计算需求[53]和对大量标注、干净且成对数据集的需求[29]。已有几篇关于COD的综述文章,其中三篇开创性的工作[54]–[56]为该领域提供了宝贵的概述。然而,这些综述由于涵盖的范围有限和涉及的论文数量不足而存在局限性。例如,这些综述中讨论的大多数方法来自2023年上半年之前,导致在历史深度和领域广度上存在不足。如图2所示,COD领域在2023年发展迅速。为弥补这些空白,我们提出了一篇更为全面的综述,涵盖了图像和视频领域中的传统和深度学习COD方法,并基准测试了这些领域中的深度学习模型。此外,据我们所知,这篇综述是首篇深入探索如基于引用的COD[49]和协作式COD[51]等新任务的综述。我们还对常用的COD数据集进行了更广泛的回顾,并全面覆盖了最新的进展、挑战和未来趋势。本文的动机源于COD的重要性以及现有综述的不足。我们的综述旨在对COD进行更为深入和详细的探讨,填补当前文献中的空白,并强调最近的发展。我们系统地分类和分析了现有的前沿技术,识别关键挑战,并提出未来研究方向,以推动该领域的发展。我们的贡献总结如下:
-
我们对现有的COD方法和伪装场景理解(CSU)相关任务,以及常用的数据集和评估指标进行了全面的综述。据我们所知,这项工作代表了迄今为止最广泛的调查,涵盖了大约180篇CSU相关的前沿研究。
-
我们系统地基准测试了基于深度特征的40个代表性图像级模型和8个代表性视频级模型,使用6个特征性数据集和6个典型评估指标,并对它们进行了定量和定性分析。
-
我们系统地识别了现有COD方法的局限性,并提出了未来研究的潜在方向。通过揭示这些挑战和机会,我们的工作旨在指导和激发进一步的研究,以推进COD技术的前沿发展。
-
我们创建了一个存储COD方法、数据集和相关资源的库,并将持续更新以确保最新信息的可获取性。 我们希望这篇COD综述不仅能加深对该领域的理解,还能在计算机视觉社区中激发更大的兴趣,促进相关领域的进一步研究。注意:在制定我们的搜索策略时,我们对包括DBLP、Google Scholar和ArXiv Sanity Preserver在内的多种数据库进行了深入调查。我们的重点特别放在可信来源上,如TPAMI和IJCV,以及CVPR、ICCV和ECCV等著名会议。我们优先考虑了那些提供官方代码以增强可重复性的研究,以及那些引用率高且在Github上获得较多星标的研究,这些都表明它们在学术界得到了显著认可和采用。在初步筛选之后,我们的文献选择过程涉及对每篇论文的新颖性、贡献和重要性的严格评估,并评估其在该领域中作为开创性工作的地位。尽管我们承认可能遗漏了一些值得注意的论文,但我们的目标是呈现对最具影响力和影响力的研究的全面概述,推动研究进展并提出未来的潜在趋势和方向。