

摘要——视频异常检测 (VAD) 旨在发现视频中偏离正常行为或事件的异常现象。作为计算机视觉领域中一个长期存在的任务,VAD 已经取得了许多显著的进展。在深度学习的时代,随着具备持续增长的能力和容量的架构的爆发,基于深度学习的各种方法不断涌现于 VAD 任务中,极大地提升了检测算法的泛化能力并拓宽了应用场景。因此,面对如此多样的方法和大量的文献,一篇全面的综述变得迫在眉睫。本文提供了一篇广泛而全面的研究综述,涵盖了五种不同类别的范畴,即半监督、弱监督、全监督、无监督以及开放集监督的 VAD 方法,并深入探讨了基于预训练大模型的最新 VAD 工作,弥补了过去仅关注于半监督 VAD 和小模型方法的综述的局限性。针对不同监督级别的 VAD 任务,我们构建了一个有条理的分类体系,深入讨论了不同类型方法的特点,并展示了它们的性能对比。此外,本综述还涉及了公共数据集、开源代码以及覆盖所有上述 VAD 任务的评估指标。最后,我们为 VAD 社区提供了若干重要的研究方向。 关键词——视频异常检测,异常检测,视频理解,深度学习。
异常代表着偏离标准、正常或预期的事物。正常性有多种多样,而异常现象则非常稀少。然而,当异常出现时,往往会产生负面影响。异常检测旨在通过机器学习发现这些稀有的异常,从而减少人工判断的成本。异常检测在多个领域中有着广泛的应用【1】,例如金融欺诈检测、网络入侵检测、工业缺陷检测和人类暴力检测。在这些应用中,视频异常检测 (VAD) 占据着重要地位,异常在此指的是时间或空间维度上的异常事件。VAD 不仅在智能安防中起着至关重要的作用(例如暴力、入侵和徘徊检测),还广泛应用于其他场景,如在线视频内容审查和自动驾驶中的交通异常预测【2】。由于其在各个领域中显著的应用潜力,VAD 吸引了来自工业界和学术界的广泛关注。
在深度学习时代之前,常规的方法是将特征提取与分类器设计分离,形成一个两阶段的过程,并在推理阶段将它们结合起来。首先进行特征提取,将原始的高维度视频数据转换为基于专家先验知识的紧凑手工特征。尽管手工特征缺乏鲁棒性,且在面对复杂场景时难以有效捕捉行为表达,但这些早期工作极大启发了后续基于深度学习的研究工作。
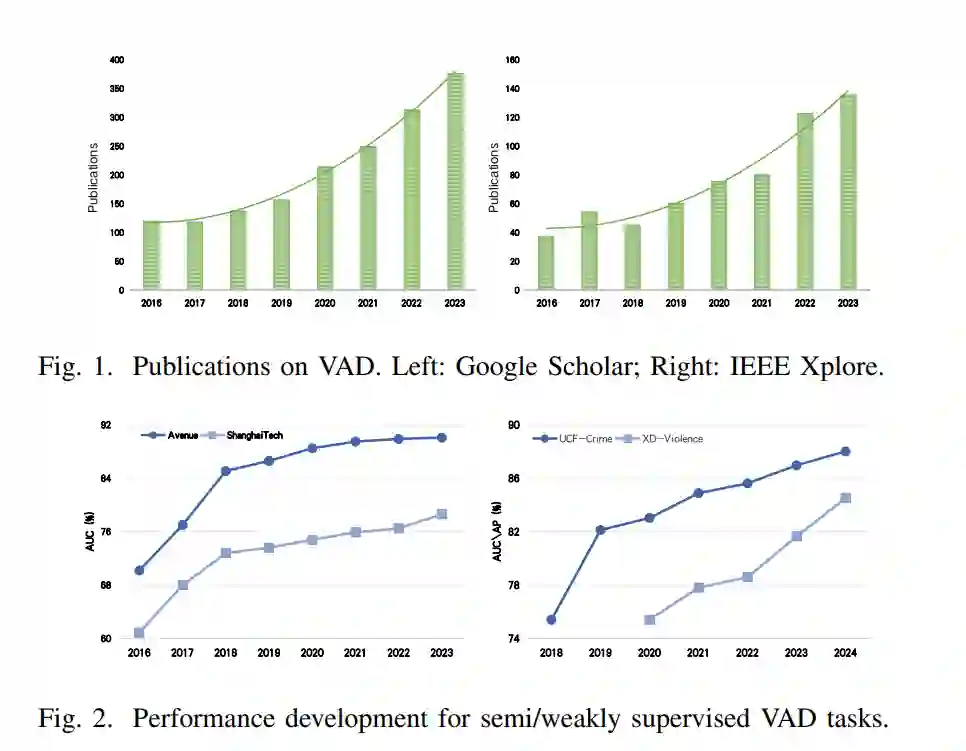
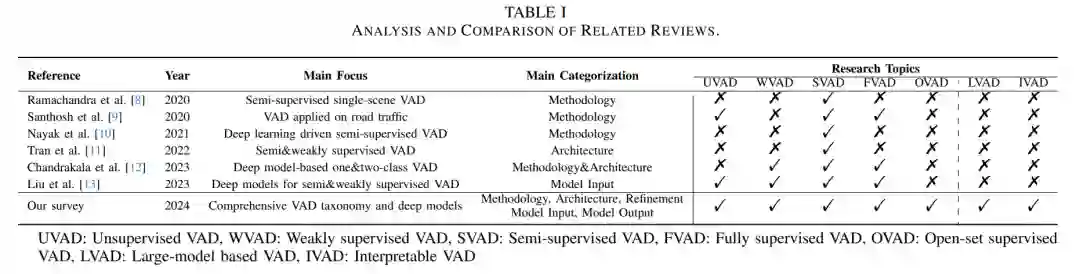
在过去十年中,随着深度学习的崛起,传统的机器学习算法逐渐失去了吸引力。随着计算机硬件的快速发展以及互联网时代大量数据的涌现,近年来基于深度学习的方法在 VAD 领域取得了显著进展。例如,ConvAE【3】作为第一个基于卷积神经网络 (CNN) 的深度自编码器,首次用于捕捉视频中的规律;FuturePred【4】首次利用 U-Net 预测未来的异常;DeepMIL【5】是第一个探索用于现实世界异常的深度多实例学习 (MIL) 框架的工作。为了更直观地展现深度学习时代对 VAD 任务的研究热情,我们通过 Google Scholar 和 IEEE Xplore1 对过去十年中与 VAD 相关的出版物数量进行了统计调查(这个时期由基于深度学习方法的崛起所驱动)。我们选择了五个相关主题,即视频异常检测、异常事件检测、异常行为检测、异常事件检测和异常行为检测,并在图 1 中展示了出版物统计数据。不难看出,从这两个来源统计的相关出版物数量呈现出稳步快速增长的趋势,表明 VAD 已经引起了广泛的关注。此外,我们还展示了在两种常见监督方式下常用数据集上年度最先进方法的检测性能趋势,并在图 2 中呈现了性能趋势。检测性能在所有数据集上均表现出稳步上升的趋势,未显示出任何性能瓶颈。例如,CUHK Avenue【6】上的半监督方法性能在过去七年间显著提升,从 70.2% AUC【3】上升到 90.1% AUC【7】。此外,针对后续提出的弱监督 VAD,研究也取得了显著进展。这表明,随着架构的发展,深度学习方法的能力不断提升,同时也展示了对 VAD 任务中深度学习方法的持续探索热情。
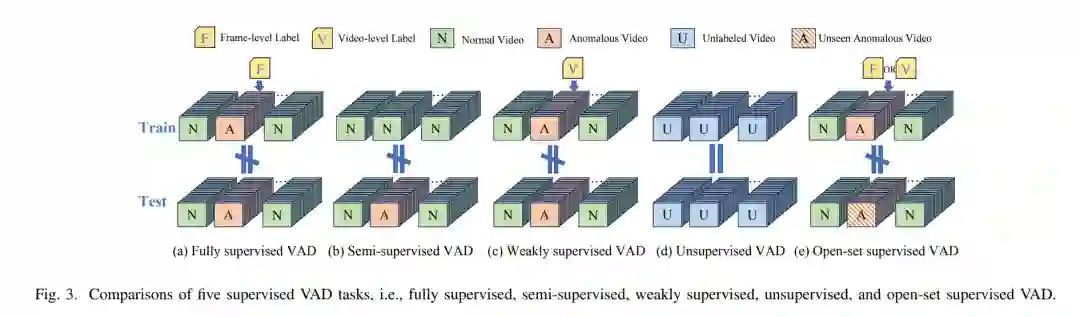
上述统计数据清楚地表明,深度学习驱动的 VAD 是当前研究的热点。因此,迫切需要对现有工作进行系统分类并进行全面总结,以便为新手提供指导并为现有研究人员提供参考。基于此,我们首先收集了近年来一些高影响力的 VAD 综述,见表 I。Ramachandra 等人【8】主要聚焦于单一场景下的半监督 VAD,缺乏对跨场景的讨论。Santhosh 等人【9】回顾了针对道路交通场景中实体的 VAD 方法。其综述缺乏足够的深度分析,主要关注 2020 年之前的方法,忽略了最近的进展。Nayak 等人【10】对基于深度学习的半监督 VAD 方法进行了全面调查,但未考虑弱监督 VAD 方法。随后 Tran 等人【11】介绍了新兴的弱监督 VAD 综述,但其重点不仅限于视频,还涉及图像异常检测,导致对 VAD 任务的系统性组织不足。最近,Chandrakala 等人【12】和 Liu 等人【13】构建了涵盖多种 VAD 任务的分类体系,例如无监督 VAD、半监督 VAD、弱监督 VAD 和全监督 VAD,并对大多数监督 VAD 任务的深度学习方法进行了综述。然而,他们的研究范围局限于传统的闭集场景,未涵盖最新的开放集监督 VAD 研究,也未引入基于预训练大模型和可解释学习的全新框架。
为全面解决这一差距,我们对深度学习时代的 VAD 研究进行了深入综述。我们的综述涵盖了几个关键方面,以提供对 VAD 研究的全面分析。具体而言,我们对深度学习时代 VAD 任务的发展趋势进行了深入调查,并提出了一个统一的框架,将不同的 VAD 任务整合在一起,填补了现有综述在分类方面的空白。我们还收集了最全面的开源资源,包括基准数据集、评估指标、开源代码和性能对比,以帮助该领域的研究人员避免走弯路并提高效率。此外,我们系统地对各种 VAD 任务进行分类,将现有工作划分为不同类别,并建立了一个清晰的结构化分类体系,以提供对各种 VAD 模式的连贯和有条理的概述。除了这个分类体系,我们还对每种模式进行了全面分析。此外,在整个综述中,我们重点介绍了对 VAD 研究进展做出重大贡献的影响力工作。 本综述的主要贡献总结如下三个方面:
-
我们对 VAD 进行了全面综述,涵盖了基于不同监督信号的五种任务,即半监督 VAD、弱监督 VAD、全监督 VAD、无监督 VAD 和开放集监督 VAD。研究重点已经从传统的单任务半监督 VAD 扩展到了更广泛的多任务 VAD。
-
跟随研究趋势,我们回顾了最新的开放集监督 VAD 研究。此外,我们还重新审视了基于预训练大模型和可解释学习的最新 VAD 方法。这些方法的出现提升了 VAD 的性能和应用前景。据我们所知,这是首次对开放集监督 VAD 和基于预训练大模型的 VAD 方法进行的全面综述。
-
针对不同任务,我们系统地回顾了现有的基于深度学习的方法,更重要的是,我们引入了一个统一的分类框架,从模型输入、架构、方法论、模型改进和输出等多个方面对各种 VAD 模式的方法进行了分类。这一精细的科学分类体系有助于对该领域的全面理解。
半监督视频异常检测
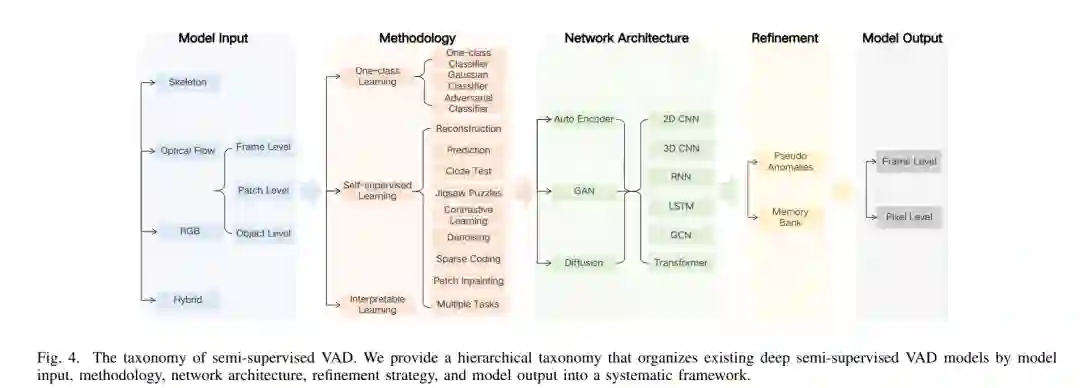
基于我们对以往综述的深入调查,我们发现现有的综述大多缺乏科学的分类体系。许多综述只是根据使用方法将半监督视频异常检测 (VAD) 作品分为不同的组别,例如基于重建、基于距离和基于概率的方法,有些综述则根据输入进行分类,例如基于图像、基于光流和基于片段的方法。显然,现有的分类综述相对简单且表面化,因此难以全面有效地涵盖所有方法。为了解决这个问题,我们建立了一个全面的分类体系,涵盖了模型输入、方法论、架构、模型优化和模型输出。详细说明见图 4。
如前所述,在半监督 VAD 任务中,只有正常样本可用于训练,这使得监督分类范式不可适用。常见的方法是利用训练样本的内在信息,学习深度神经网络 (DNN) 来解决前置任务。例如,正常性重建是一个经典的前置任务【3】。在此过程中,需要考虑几个关键方面:样本信息的选择(模型输入)、前置任务的设计(方法论)、深度网络的利用(网络架构)、方法的改进(优化)和异常结果的表达(模型输出)。这些关键要素共同决定了半监督 VAD 解决方案的有效性。在接下来的章节中,我们将根据上述分类体系系统地介绍现有的基于深度学习的 VAD 方法。
IV. 弱监督视频异常检测
弱监督视频异常检测 (VAD) 是当前 VAD 领域中备受关注的研究方向,其起源可追溯到 DeepMIL【5】。相比于半监督 VAD,这是一个较新的研究方向,因此现有的综述缺乏全面而深入的介绍。如表 I 所示,Chandrakala 等人【12】和 Liu 等人【13】都提到了弱监督 VAD 任务。然而,前者仅简要描述了 2018 至 2020 年间的一些成果,而后者尽管涵盖了近期的工作,却缺乏科学的分类体系,仅根据不同的模态将其简单地分为单模态和多模态。鉴于此背景,我们从 2018 年至今调查了相关工作,包括基于预训练大模型的最新方法,并从四个方面对现有工作进行了分类:模型输入、方法论、优化策略和模型输出。弱监督 VAD 的分类体系如图 8 所示。 与半监督 VAD 相比,弱监督 VAD 在训练过程中明确定义了异常,为检测算法提供了明确的方向。然而,与全监督 VAD 相比,粗糙的弱监督信号为检测过程引入了不确定性。现有的大多数方法利用 MIL 机制来优化模型。这个过程可以视为从正常包(正常视频)中选择看起来最异常的最困难区域(视频片段),以及从异常包(异常视频)中选择最有可能异常的区域。然后,目标是最大化它们之间的预测置信差异(即使最困难的正常区域的置信度接近 0,最异常区域的置信度接近 1),这可以被视为二元分类优化。通过逐步挖掘所有正常和异常区域的不同特征,异常区域的异常置信度逐渐增加,而正常区域的置信度则逐渐下降。不幸的是,由于缺乏强监督信号,检测模型在上述优化过程中不可避免地会涉及盲目猜测。
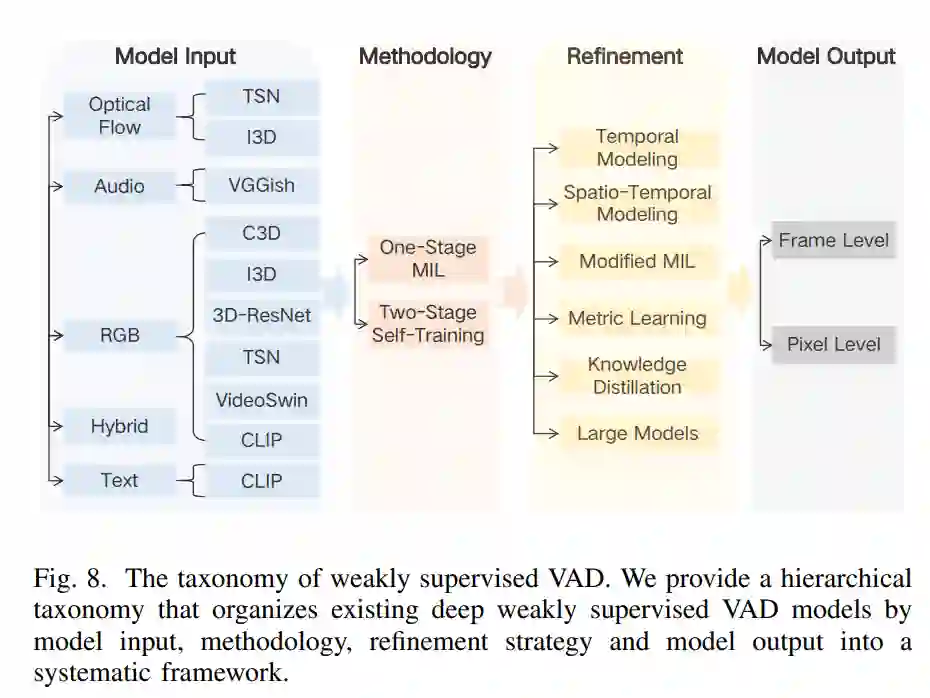
VII. 开集监督视频异常检测
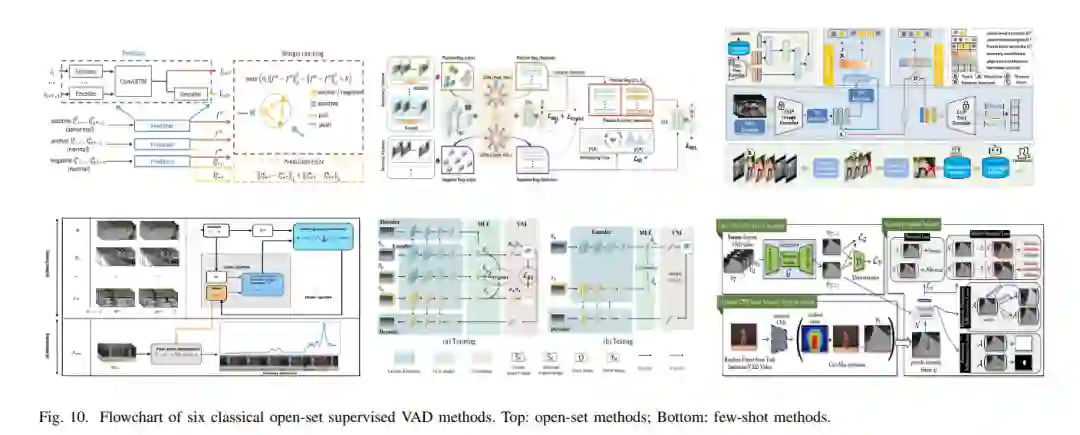
让经过充分训练的监督模型在开放环境中检测未见过的异常是一项具有挑战性的任务。在现实场景中,未见过的异常很可能会出现,因此,关于开集异常检测的研究引起了广泛关注。开集监督视频异常检测 (VAD) 是一项具有挑战性的任务,其目标是在训练阶段未见过的异常事件中进行检测。与传统的(闭集)VAD 不同,传统 VAD 中的异常类型是已知且定义明确的,而开集 VAD 必须处理不可预见和未知的异常。这对现实世界的应用至关重要,因为在训练过程中预见并标注所有可能的异常是不现实的。因此,开集 VAD 的研究引起了极大的关注。然而,现有的综述工作并未对开集 VAD 进行深入研究。基于此,我们进行了深入的调查,并对现有的开集 VAD 工作进行了系统分类。据我们所知,这是第一个包含详细介绍开集监督 VAD 的综述。在本节中,我们根据不同的研究方向,将开集监督 VAD 大致分为两类:开集 VAD 和小样本 VAD。在图 10 中,我们展示了六种经典的开集监督 VAD 方法。
IX. 结论
我们对深度学习时代的视频异常检测方法进行了全面综述。与之前主要集中于半监督视频异常检测的综述不同,我们提出了一个系统的分类体系,将现有的工作根据监督信号分为五类:半监督、弱监督、无监督、全监督和开集监督视频异常检测。对于每个类别,我们进一步根据模型的不同特征进行细分,例如模型输入和输出、方法论、优化策略和架构,并展示了各种方法的性能对比。最后,我们讨论了基于深度学习的视频异常检测未来的一些有前景的研究方向。

