
机器之心发布机器之心编辑部
本文对近年来引起较大研究热情的动态神经网络 (Dynamic Neural Networks) 做了一个比较全面和系统的综述。

论文链接:https://arxiv.org/pdf/2102.04906v2.pdf
开始正文之前,首先简要介绍下动态网络的概念。传统(静态)神经网络的使用流程为:1) 固定网络架构,初始化网络参数;2) 训练阶段:在训练集上优化网络参数;3) 推理阶段:固定网络架构与参数,输入测试样本进行前向传播,得到预测结果。
可以看出,静态网络在测试阶段,对所有的输入样本,均采用相同的网络架构与参数进行推理。与静态网络不同的是,动态网络可以在处理不同测试样本时,动态地调节自身的结构 / 参数,从而在推理效率、表达能力、自适应性等方面展现出卓越的优势。
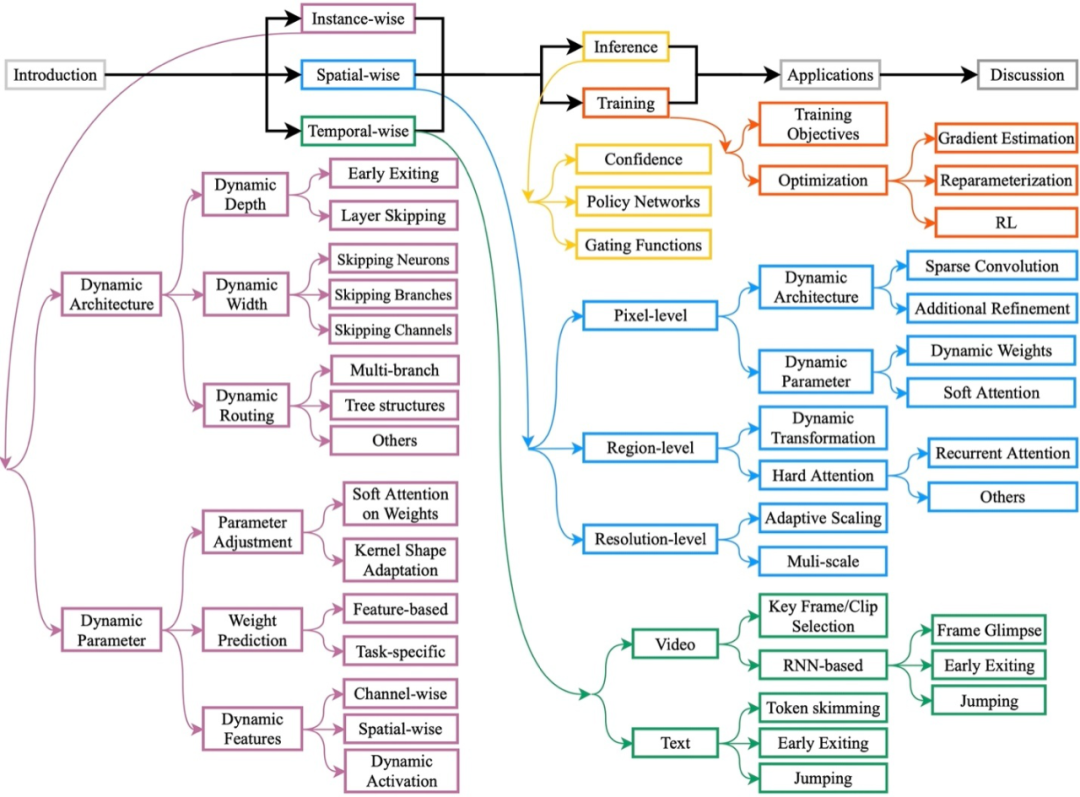
本文综述的框架如下图 1 所示。文章根据自适应推理的方式,将动态网络分为三类:样本自适应,空间自适应以及时间自适应动态网络。第 1 章介绍了动态网络的概念、优点以及综述动机。第 2 章主要介绍了最为常见的样本自适应动态网络:模型能够针对不同输入样本,自适应地调节其结构或参数。第 3、4 章中分别介绍了两种更细粒度的动态模型:空间自适应和时间自适应动态网络,分别从每个输入样本的空间、时间维度进行自适应推理。第 5 章总结了动态网络的决策机制和训练策略。第 6 章介绍了动态网络的应用。最后,领域内的开放性问题与未来研究方向在第 7 章中进行讨论。
Introduction (动态网络简介与综述动机)
深度神经网络已经在计算机视觉、自然语言处理等领域取得了较大的成功。这些年来我们不断见证越来越强大、高效的神经网络模型设计(如 AlexNet[1], VGG[2], GoogleNet[3], ResNet[4], DenseNet[5]以及最近很火的 Transformer[6]等),而近几年发展起来的网络架构搜索技术 (NAS)[7],[8]也帮助人们建立更加强大的结构。
然而,大多数当前流行的深度网络都具有相同的静态推理范式:一旦完成训练,网络的结构与参数在测试阶段都保持不变,这在一定程度上限制了模型的表征能力、推理效率和可解释性[9],[10],[11],[12]。
如前所述,动态网络则可以在推理阶段根据输入样本自适应地调节自身的结构 / 参数,从而拥有诸多静态网络无法享有的良好特性。总体来说,深度学习中的动态计算在以下方面具有优势:
**1. 推理效率。**很多动态网络可以通过选择性地激活模型中的模块(如网络层 [10]、卷积通道[13] 或子网络[14])来实现计算资源的按需分配,从而在更容易识别的样本上或信息量更少的区域位置(时间或空间)上节约冗余计算,提升推理效率;
**2. 表达能力。**通过动态调节网络的结构 / 参数,动态模型可以拥有更大的参数空间以及更强的表达能力。例如,通过对多组卷积权重进行基于特征的动态集成 [11],[15],模型容量可以在增加极小计算开销的前提下得到显著提升。值得一提的是,常用的注意力机制也可以被统一到动态网络的框架中,因为特征的不同通道[16]、空间区域[17] 和时间位置 [18] 都在测试阶段被动态地重新加权;
3. 自适应性。相较于一个静态网络拥有固定的计算量,动态网络可以在面对变化的环境(如不同的硬件平台)时实现模型精度 vs 效率的动态平衡;
4. 兼容性。动态网络并非「另起炉灶」,而是与深度学习领域其他的先进技术相兼容,从而可以利用这些先进技术达到 SOTA 性能。例如,动态网络可以直接基于轻量化模型构建 [19],也可以利用 NAS 技术设计[7],[8]。另外,动态网络也可以利用针对传统静态模型设计的加速技术(剪枝[20]、量化[21] 等)进一步提升运算效率;
**5. 通用性。**许多动态网络可以被用于多任务中,包括图像分类 [10],[22]、目标检测[23]、语义分割[24] 等。另外,许多视觉任务中发展起来的技术可以被拓展至 NLP 领域[25],[26],反之亦然;
**6. 可解释性。**最后,鉴于有研究指出生物大脑脑处理信息的动态机制[27],[28],关于动态网络的研究可能会帮助人们在深度模型和大脑的内在运行机制之间架起一座桥梁。利用动态网络,人们可以分析:1)处理一个样本时,网络的哪些模块被激活[22];2)输入中的哪些部分对最终的预测起决定性作用[29]。
实际上,动态网络的核心思想——自适应推理,在如今的深度网络流行之前已经被部分研究者研究。其中最经典的做法是构建多个模型的动态集成(以级联 [30] 或并行 [31] 的方式),并根据输入样本自适应地激活这些模型。另外,脉冲神经网络 (SNN)[32],[33]通过在模型中传递脉冲信号来实现基于输入数据的自适应推理。然而,SNN 的训练与如今常用的卷积神经网络 (CNN)有较大区别,因此在视觉任务中应用较少。因此,在本篇综述中,研究者没有对 SNN 相关的工作做更多详细的讨论。 在深度学习中,基于先进深度模型的自适应推理带来了很多新的研究问题。尽管已经各种各样的动态网络被设计出来并取得一定成功,该领域仍然缺少一个系统而全面的综述。因此,研究者写作本篇综述的动机主要为:
为对此主题感兴趣的研究人员提供领域概述和新的视角; 指出不同子领域之间的紧密关系,并减少重复造轮子的风险; 总结了主要挑战和未来可能的研究方向。
接下来,本文对综述的各个章节进行主要内容的概述。
Instance-wise Dynamic Networks (样本自适应动态网络)
样本自适应动态网络对每个输入样本进行自适应计算。根据网络动态变化的主体,其主要可以分为两大类:动态结构与动态参数。前者主要是为了在处理 “简单” 样本时分配更少的计算资源从而提升运算效率,而后者主要是为了在增加尽可能少计算量的情况下,提升模型表达能力。 Dynamic Architectures (动态结构)
流行的深度网络结构往往包括深度(网络层数)和宽度(通道数、并列的子网络个数等)这两个维度。因此,具有动态结构的网络又包括动态深度、动态宽度两个类型。另外,还有一类工作则是首先建立具有多条前向通道的超网络 (SuperNet), 然后采用一定的策略,对不同的输入样本进行动态路由。因此,本节内容包括了上述三种类型的工作,即动态深度、动态宽度和超网络中的动态路由。
*动态深度
由于几乎所有的网络都由多个网络层堆叠而成,一个比较自然的实现动态结构的思路就是针对不同样本,选择性地执行不同的网络层。具体地,实现动态深度又主要包含两类思路:
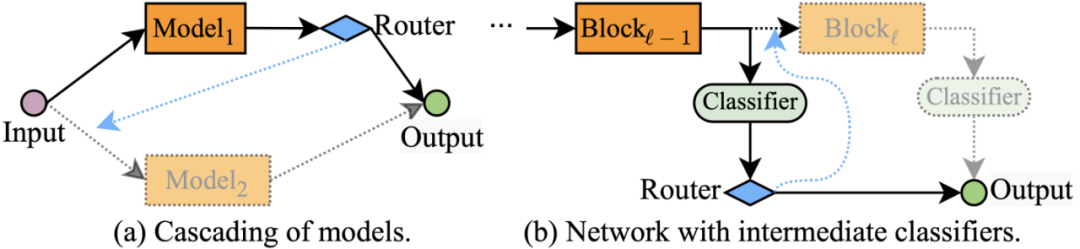
1.「早退」机制。顾名思义,「早退」机制的核心思想是:在模型中间层设置出口,并根据每个样本在这些中间出口处的输出,自适应地决定该样本是否「早退」。不同的工作设计了不同的网络结构来实现这样的「早退」,包括将多个模型串联 [34]、在单个 backbone 中间层添加分类器[35] 等(如下图 2 所示)。
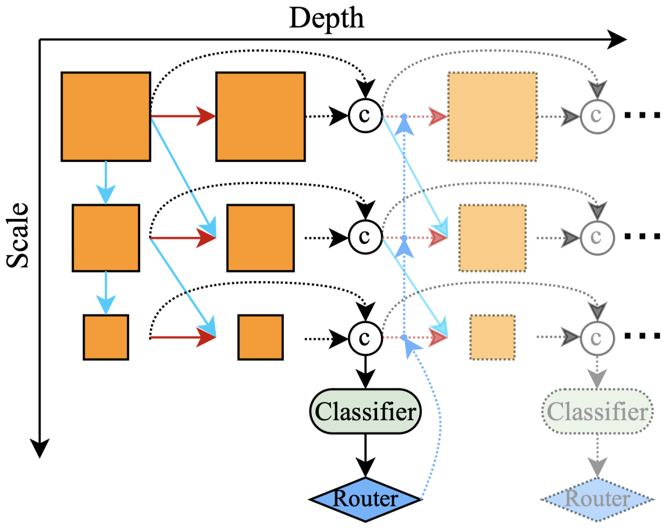
2.「跳层」机制。「早退」机制相当于跳过了某一分类器之后所有层的运算。第二类具有动态深度的网络则更加灵活:针对每个输入样本,自适应地决定网络的每个中间层是否执行。根据决策方式,动态「跳层」主要有三种实现(如下图 4 所示):基于 halting score[9]、基于门函数 [36] 和基于策略网络[37]。

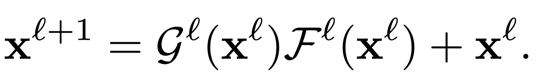
其中,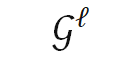
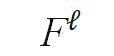
动态宽度
早期工作曾经研究通过低秩分解 [38] 等方式控制线性层中神经元的动态激活。文章中着重讨论了另外两种如今更加常用的方法:多专家混合系统 (MoE)以及 CNN 中的动态通道剪枝。
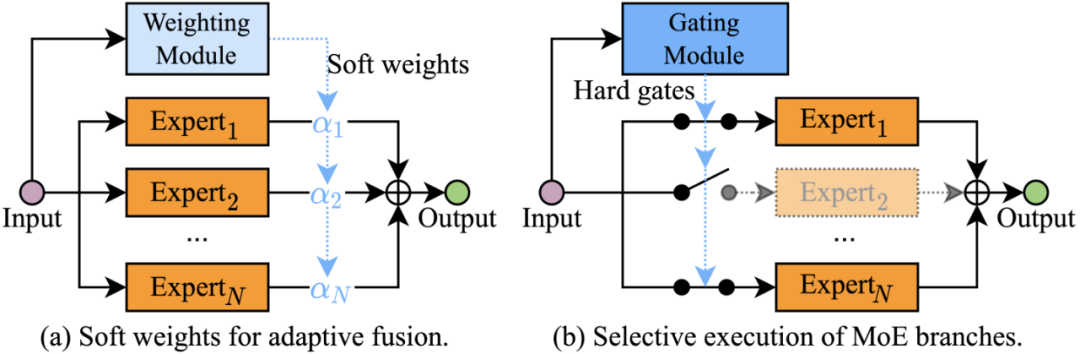
1.** 多专家混合系统 (MoE)。有一类工作通过并行结构**建立多个「专家」(可以是完整模型或者网络模块),并对这些「专家」的输出结果进行动态加权来得到最终预测。早期的相关工作往往对这些结果进行「软」加权(如下图 5 (a) 所示)来提升模型的表征能力[39],[40]。然而,网络的运算量随着「专家」个数线性增长,带来了大量的冗余计算。因此,近期的一些研究通过控制门(gates)来选择性地激活这些「专家」子网络,从而实现模型效率的提升(见图 5 (b))。
**2.CNN 中的动态通道剪枝。**这一课题在近年来被广泛研究。相较于静态剪枝方法将某些「不重要」的通道永久性地去除,此类方法可以根据样本自适应地激活不同的卷积通道,从而在保持模型容量的情况下实现计算效率的提升。文章将此方向的研究分为三类:通道维度的多阶段结构 [41]、基于门函数的动态剪枝[13] 以及直接基于特征激活的动态剪枝[42]。 类似于动态跳层机制,由于门函数的「即插即用」特性,其在 CNN 的动态剪枝中也是当前较为流行的主要方法。不同的工作采用了不同的门函数设计,以及训练方法等。更多细节的讨论这里不再赘述。 值得一提的是,已经有工作利用门函数同时控制网络的深度和宽度[43],[44]。这些方法通常先决定某个网络层是否执行,若执行,则进一步对该层的不同通道进行更细粒度的挑选。
动态路由
区别于之前工作中基于已有链式结构或多尺度架构进行网络层的动态执行,有一部分工作建立更加通用的超网络,并在超网络内部的(部分)节点,采用一定的路由机制来对到达该网络的样本特征进行动态路由。对于第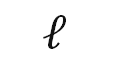
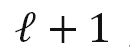
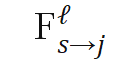
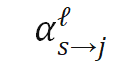
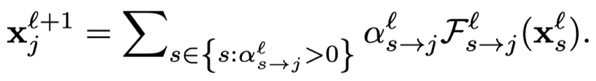
文章中讨论了三种超网络的结构:多分枝结构、树状结构以及其他。这里不再展开介绍,感兴趣的读者可以查阅原文相关章节。
Dynamic Parameters (动态参数)
前面介绍的具有动态结构的网络往往需要特别的结构设计、训练策略或超参数调整等。另一类工作则保持网络结构在推理过程中不变,根据输入样本自适应地调节模型的(部分)参数,从而提升模型的表达能力。静态网络的推理过程可表示为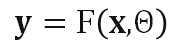
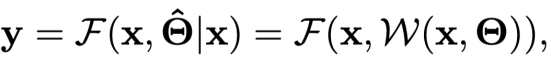
其中是产生动态参数的操作。 总体来说,动态参数类的研究可以分为三大类(如下图 6 所示):参数的动态调节、参数预测以及基于注意力的动态特征。

参数的动态调节
这类工作的核心思路包括两种:1)对主干网络的参数在测试阶段使用注意力进行重新加权,从而提升网络的表达能力;2)自适应调节卷积核的形状,从而让网络拥有动态感受野。
- 权重注意力机制。最具代表性的工作包括 CondConv[11]和 DY-CNN[15] , 核心操作是设立多组卷积核,并基于输入特征学习一组权重,将这些卷积核进行加权求和后进行卷积:
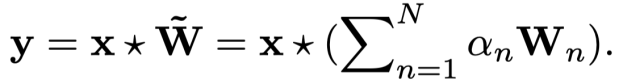
这样的操作与将输入与各组权重进行卷积的输出进行加权求和效果相同,但只需执行一次卷积操作,从而大大节约了计算开销。
- 卷积核形状的自适应调节。著名的可形变卷积 (Deformable Convolution)系列 [45],[46] 对于每个像素点,在整张特征图中进行采样作为其卷积操作的临域。可形变卷积核 (Deformable kernels) 则在核空间而非特征像素空间进行动态采样,从而对网络的有效感受野进行自适应调节。这三种操作的具体形式如下表所示:

参数预测
参数预测比前面介绍的动态调节方式更为直接,其直接由输入预测生成网络的(部分)参数。早期的代表性工作有分别针对 CNN 和 RNN 的 dynamic filter network [48]以及 HyperNetwork[49]。近期的 WeightNet[50]则统一了 CondConv 和通道注意力网络 SENet[16]的自适应范式,通过参数预测的方式实现了更好的网络性能与效率平衡。
基于注意力的动态特征
前面描述的动态参数方法的主要效果是生成更加动态与多样的特征,从而提升模型的表达能力。为实现这一目的,一个等效的解决方案是直接针对特征进行动态加权。对于一个线性变换, 对其输出进行加权,得到的结果等效于先对参数加权,再执行该变换,即
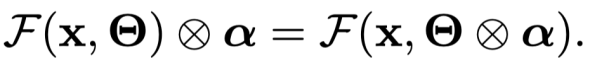
最常用的方法是以 SENet 为代表的对卷积层的输出特征中不同通道进行自适应加权。其基本形式为
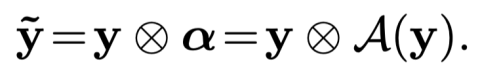
不同的工作设计了各种各样的注意力模块, 这里不再展开介绍。 除了通道以外,注意力也可以被用来对特征的不同空间位置进行自适应加权[51],且这两种注意力范式(通道、空间)可以被以多种形式组合起来进一步提升模型表达能力[52](见图 6 (c))。 上述动态特征方法通常在非线性激活函数(如 ReLU)前对特征进行重新加权。近期的一些工作(如 Dynamic ReLU[53])直接设计动态激活函数,并替换传统网络中的静态激活函数,同样能够大幅提高模型的表达能力。
Spatial-wise Dynamic Networks (空间自适应动态网络)
在视觉任务中,已有研究表明输入中不同的空间位置对 CNN 的最终预测起着不同的作用[54]。也就是说,做一个精确的预测,可能只需要自适应的处理输入中一部分空间位置,而无需对整张输入图像的不同位置进行相同计算量的运算。 另有研究表明,对输入图像仅使用较低的分辨率,已经可以使网络取得不错的准确率[55]。因此,传统 CNN 中对所有输入图像采用相同分辨率表征的做法会带来无可避免的冗余计算。 为此,空间自适应动态网络被设计以对图像输入从空间的角度进行自适应推理。根据动态运算的粒度,研究者进一步将空间自适应网络分为三个级别:像素级、区域级以及分辨率级。
Pixel-level Dynamic Networks (像素级动态网络)
作为空间自适应网络中最常见的类型,像素级动态网络对输入特征图的每个空间位置进行自适应计算。类似于第 2 章中样本自适应动态网络中的分类方法,研究者将本方向的工作也分为动态结构和动态参数两大类。
动态结构
顾名思义,像素级动态结构网络对不同的像素点调用不同的网络模块,从而避免在背景区域等与任务无关的区域上进行冗余计算。具体实现又可以细分为两种类型:
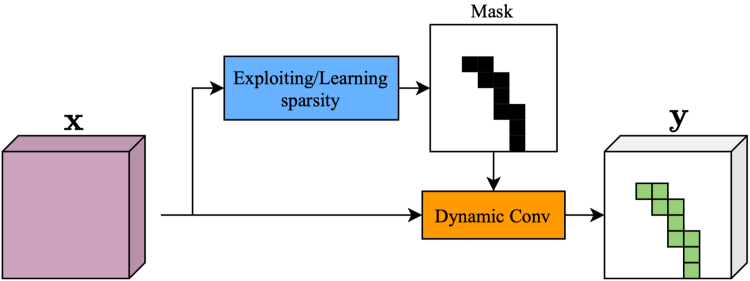
- 稀疏卷积。第一种类型的工作整体操作过程大体如图 7 所示,即生成一个空间掩码,进而对选中的像素进行稀疏卷积运算。值得一提的是,大多数方法对于未选中的区域不分配任何计算,从而可能对网络性能带来一定影响。近期工作 [56] 通过插值的方式,对未选中的区域通过较少的计算进行了填充,从而在一定程度上解决了该问题的影响;
- 额外修正。第二种类型的工作则是先对整张图(采用相对较少的计算)进行处理,再根据处理结果选中某些位置的像素进行额外修正,从而得到更加精细的特征表达。代表性的工作有额外激活卷积通道的 channel gating network [41], 以及激活线性层的 PointRend[57]等。
动态参数
在第 2 章中介绍的几类动态参数方法(参数调整、预测以及基于注意力的动态特征)都可以被运用于像素级动态网络。 以参数预测方法为例,设为卷积核大小,分别为特征图的高和宽,通过生成一个大小的 kernel map, 便得到了输出特征图每个位置需要采用的卷积核。考虑到属于同一物体的不同像素可以共享卷积核参数,近期工作 [58] 将输入特征图自动划分为多个区域,并对每个区域采用一套生成的权重进行卷积运算。 另外,前面章节 (2.2.1) 提到的可形变卷积,也属于像素级动态参数网络。
Region-level Dynamic Networks (区域级动态网络)
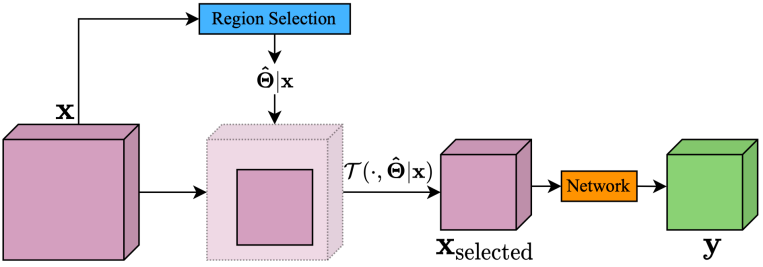
像素级动态网络中的稀疏采样操作往往导致模型在实际运行中难以取得理论上的加速效果。区域级动态网络则从原输入中选择一块整体区域进行自适应计算(整体流程如下图 8 所示):
Resolution-level Dynamic Networks (分辨率级动态网络)
上述工作通常需要将一张输入图像划分为不同区域,并对每个区域进行自适应计算。其中的稀疏采样 / 裁剪操作往往会影响模型实际运行时的效率。另一类动态网络则依然将每个输入样本作为整体处理,为了减少「简单」样本的高分辨率表征带来的冗余计算,对不同的输入图像采用动态分辨率进行数据表示。 现有工作中,动态分辨率主要有两种实现思路: 第一种是动态的放缩比例。以 ResNet 结构为例,传统的 ResNet 将网络分为多个阶段,并在每个阶段的第一个残差块 (residual block) 采用步长 stride=2 的卷积,将图像分辨率降为上个阶段的 1/4。动态步长网络 (dynamic stride network)[61]则在每个阶段开始处根据不同输入样本,自适应地选择第一个残差块的卷积步长,从而实现动态特征分辨率; 第二种是采用多尺度架构。分辨率自适应网络 (resolution adaptive network) [22]建立多尺度架构 (如下图 9 所示),用不同的子网络处理不同分辨率的特征,并将这些子网络从小到大顺序执行。通过允许「早退」,「简单」的图像样本能够以较低的分辨率被处理,从而避免调用处理更大分辨率特征的子网络。

Temporal-wise Dynamic Networks (时间自适应动态网络)
时序数据(如文本、视频等)在时间维度上具有较大的冗余性。因此,时间自适应动态网络被设计用来对不同时间位置的数据进行自适应计算,文章中根据数据类型,分别介绍了用于文本处理的动态 RNN 以及时间自适应动态视频识别方法。总体来说,时间自适应动态网络可以从两个方面减少冗余计算:1) 对于某些「不重要」位置的输入,分配较少的计算;2) 仅在一部分采样出的时间位置上执行计算。由于视频识别可以视作对帧特征的时序化处理,以下主要介绍文章中的 4.1 节,即基于动态 RNN 的文本处理方法。
RNN-based Dynamic Text Processing (基于 RNN 的动态文本处理)
常规的静态 RNN 对于长度为 T 的时序数据处理流程为迭代式地更新其隐状态,即
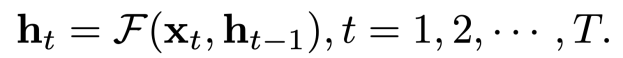
然而,由于不同时刻的输入对于任务的贡献程度(重要性)不同,对每个时刻的输入均采用相同复杂度的操作会导致无法避免的冗余计算。因此,不同形式的动态 RNN 被设计以根据不同时刻的输入自适应地决定是否分配计算,或者采用何等复杂度的计算。

隐状态的动态更新
考虑到不同时刻输入数据的重要性不同,第一类动态 RNN 在每一时间步采用自适应计算的方式更新其隐状态。这样的自适应计算具体可以由以下三种方式实现:
- 跳过隐状态的更新 [62]。具体而言,动态网络可以直接忽略不重要的输入,直接将上一时刻的隐状态复制至下一时刻(如图 10 (a) 所示),即
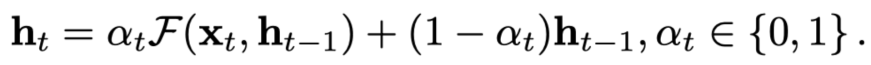
不同工作采用了不同的具体设计来判断是否进行隐状态的更新,这里不再赘述。
- 粗略的更新[63]。相较于直接跳过状态更新,另一类动态网络采用自适应的网络结构来更新每一时刻的隐状态,即
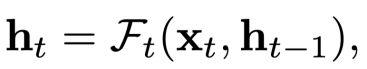
对于动态网络结构,如前面章节所述,可以通过变化网络的深度或宽度来实现。例如,模型可以选择隐状态的部分维度来更新(见图 10 (b))。 3. 用多尺度架构进行选择性更新 [64]。另一类网络则采用多尺度架构以捕获长序列中的层次化结构信息。如图 10 (c) 所示,底层的 RNN 模型可以用来处理字符序列,而当输入满足一定条件(如接收到标点符号),更高层的 RNN(处理单词序列)将底层模型的状态作为输入,更新其状态。
早退」机制
上一节中介绍的动态 RNN 依然需要将所有时刻的样本输入,再进行自适应计算所需的决策。在很多场景中,只根据时序数据的开头就可以解决所需的问题。例如,人类只需阅读文章的摘要就可以对文章的大意有一定的了解。因此,有一类动态 RNN 实现了这样的「早退」机制,即在某一中间时刻,判断当前隐状态是否可以用于解决所需任务[65]。如是,则提前终止「阅读」。本节中与第二章中介绍的「早退」机制不同的是,后者在网络深度的维度实现了动态结构,而前者则从数据的时间维度实现「早退」以避免冗余计算。
*动态「跳跃」机制
在上一节中的「早退」机制中,网络只能决定是否终止运算,而不能决定去「看」输入中哪些位置的数据。本文中介绍的第三类动态 RNN 则通过动态「跳跃」机制解决这一问题,即在每一时刻,模型可以自适应地决定下一时刻输入模型的数据从何位置读取(如图 10 (d)所示)。值得一提的是,这样的机制与「早退」可以同时实现。例如,工作 [66]中的模型在更新完一步隐状态后,先决定是否早退,如否,则决定是否跳过一定数量的输入。
Inference and Training (推理与训练)
在前面的章节中,研究者回顾了三种类型的动态网络(样本自适应、空间自适应以及时间自适应)。可以发现,动态网络的一个核心要素是在推理阶段进行基于数据的决策。另外,这样的决策过程也给动态网络带来了相对于静态模型更多训练上的挑战。 值得一提的是,大多数具有动态参数的网络可以通过可微分的操作来实现[11],[16],[50], 因而可以用常规的梯度下降方法训练。因此,在本章中更多关注动态网络在推理阶段所进行的离散决策及其优化。 Decision Making of Dynamic Networks (动态网络的决策方式)
如前文所述,动态网络可以在推理阶段来调整其结构 / 参数,或者自适应的决定样本中的对哪些空间 / 时间位置进行运算。这里研究者总结了三种常见的决策方式:
- 基于置信度的准则:常用于具有「早退」机制的分类网络中,无需分配额外的计算量,但往往需要在验证集上对阈值进行调参数;
- 基于策略网络:建立独立于主干网络的策略网络,常用于第 2 章的动态结构方法中用以变换网络的深度、宽度或进行动态路由;
- 基于门函数(gating functions):在主干网络中插入轻量级模块进行离散决策,由于门函数的即插即用特性,其相对于策略网络方法具有更好的通用性。但由于离散决策函数没有梯度信息,往往需要特别的训练方法,在下节中进行介绍。 Training of Dynamic Networks (动态网络训练)
本节从训练目标与优化方法两个角度总结动态网络的训练策略。
训练目标
- 训练多出口网络。多出口网络的训练方式往往较为简单:将各个出口的损失函数加权相加。前面章节中提到,链式结构中,这样的方法往往导致出口之间相互干扰。MSDNet 通过特别的结构设计来解决这一问题。基于 MSDNet 的结构,一篇后续的工作 [67]从训练的角度出发,提出梯度平衡算法来稳定训练过程,并利用双向信息传递来改善多个分类器的协同训练;
- 鼓励稀疏度。对于具有动态结构或者进行空间 / 时间位置采样的模型,如果不添加额外的约束项,一个可能的结果是网络为了极小化训练误差,倾向于激活其所有的模块 / 采样所有的位置进行计算。因此,为了减少冗余计算,此类网络通常需要添加一项正则项以鼓励稀疏度。从而,整体的训练目标可以写为。该正则项可以是候选单元的激活比率或范数[56],也可以是由输入输出的数据维度估算的模型计算量[43];
- 其他。另有工作引入额外的损失函数项(如采用知识蒸馏技术)不是为了提升模型的效率,而是为了提升多个子模型的协同训练效果[41]。
不可导函数的优化方法
- 梯度估计: 早期的一些工作使用 straight-through estimation (STE)来估计离散门函数的梯度[68],[69];
- 重参数化技术: 近年最常用的技术是 Gumbel SoftMax[70], 通过引入具有 Gumbel 分布的噪声来拟合类别分布。同样常用于离散门函数的训练[71];
- 强化学习:用强化学习算法来训练需要进行离散决策的策略网络。训练的回报中往往包含一项对于计算量的惩罚项,用以提升模型的推理效率。
###Application of Dynamic Networks (动态网络的应用)
根据输入模态,研究者总结了动态网络在领域中的应用情况以及相对应的自适应推理类型,如下表所示:
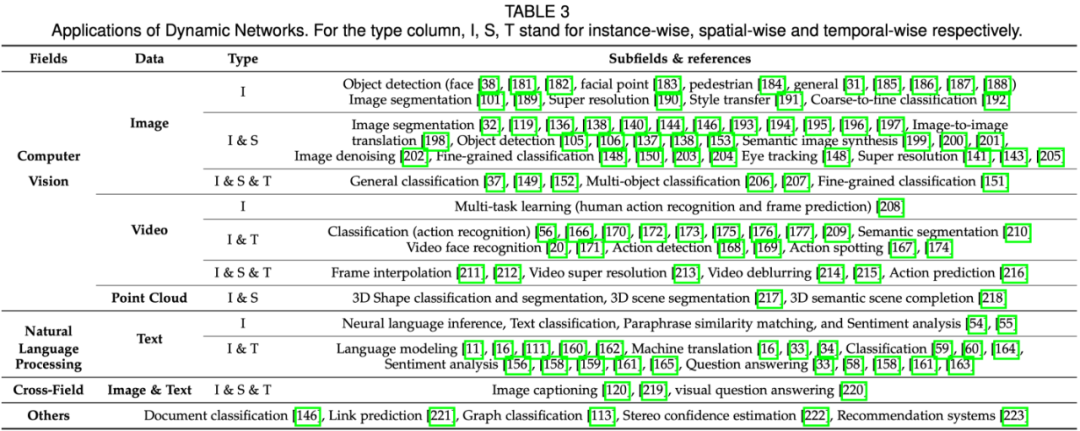
另外,动态网络还被用来解决一些深度学习中的基础性问题,例如,多出口网络被用来解决具有长尾分布的图像分类 [72],动态路由思想可以被用来减少多任务设定下的训练开销[73] 等。
Discussion (讨论)
本章对动态网络领域内的开放性问题和未来研究方向进行了讨论,包括以下方面:
- 动态网络理论。包括 1) 最优决策问题:决策是大多数动态网络推理过程中一个本质性的操作。现有方法 (基于置信度、策略网络或门函数) 均缺乏一定的理论保障,且并不一定是最优的决策方式。因此,设计具有理论保障的决策函数是未来很有价值的研究方向。2) 泛化性能。在动态模型中,不同的子网络被不同的测试样本激活,导致这些子网络在训练和测试阶段所面临数据分布存在一定偏差。因此,对于动态网络泛化性能的新理论将是一个有趣的课题;
- 动态网络的结构设计。目前大多数网络结构方面的工作致力于设计静态网络,而多数动态网络设计方法基于已有的经典静态模型架构,选择性地执行其中的不同单元。这对于动态网络的结构设计可能只是一个次优解,例如 MSDNet [10]中的多尺度架构与密集连接可以较好的解决之前链式多出口网络分类器之间相互干扰的问题。因此,针对于自适应计算的动态网络结构设计可以进一步提升其性能和运算效率;
- 更多样任务下的适用性。目前大多数动态网络仍只是针对分类任务设计,难以直接运用于其他视觉任务,如目标检测和语义分割。其难点在于这些任务中没有一个简单的准则来判断样本的难易程度,而一个样本中又包含多个不同复杂度的目标 / 像素点。现有一些方法,如空间自适应网络 [56] 和软注意力机制[16],已经可以用于分类之外的更多任务。然而,设计一个统一而简洁优雅,并可以直接作为其他任务主干网络的动态网络结构仍然具有一定的挑战性;
- 实际效率与理论的差距。现有的深度学习计算硬件和软件库大多针对静态模型开发,对于动态模型的加速尚不够友好,从而导致动态模型的实际加速可能落后于理论效果。因此,设计硬件友好的动态网络是一个有价值和挑战性的课题。另一个有趣的方向则是进一步优化计算硬件和软件平台,从而更好的收获动态网络带来的理论效率提升;
- 鲁棒性。近期工作 [74]已经显示,动态模型可以为深度网络的鲁棒性带来新的研究角度。另外,通常的对抗攻击致力于降低模型准确率,而对于动态网络,可以同时攻击模型的准确率和效率[75]。因此,动态网络的鲁棒性是一个有趣而尚未被充分研究的课题;
- 可解释性。动态网络继承了深度神经网络的 “黑箱” 特性,带来了解释其工作机制的研究方向。特别之处在于,动态网络的自适应推理机制,如空间 / 时间上的自适应性,与人类的视觉系统相符合。另外,对于一个给定样本,可以很方便的分析动态网络做出预测需要激活哪些部分。研究者期望这些性质可以启发新的深度学习可解释性方面的工作。
**嘉宾简介:**韩益增,2018年本科毕业于清华大学自动化系,现为清华大学自动化系博士生,导师为宋士吉教授、黄高助理教授。当前研究方向为深度学习与计算机视觉,其中重点为动态神经网络以及高效模型架构设计与搜索。
**分享摘要:**本次报告我们将结合近日上线的论文《Dynamic Neural Networks: A Survey》,对近年来吸引大量关注的动态神经网络进行综述性的介绍。 与传统静态模型不同的是,动态网络可以在推理阶段根据输入自适应的调节模型结构/参数,从而在运算效率、表达能力等方面展现出卓越的优势。根据自适应计算的方式,我们将动态网络分为三类:样本自适应,空间自适应以及时间自适应。报告中,我们将回顾动态网络中重要的研究问题,并探讨领域内的开放性问题与未来研究方向。
参考文献:[1]Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In NeurIPS, 2012. [2]Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015. [3]Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In CVPR, 2015. [4]Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016. [5]Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In CVPR, 2017. [6]Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and IlliaPolosukhin. Attention is all you need. In NeurIPS, 2017. [7]Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning. In ICLR, 2017. [8]Hanxiao Liu, Karen Simonyan, and Yiming Yang. DARTS: Dif- ferentiable Architecture Search. In ICLR, 2018. [9]Alex Graves. Adaptive computation time for recurrent neural networks. arXiv preprint arXiv:1603.08983, 2016. [10]Gao Huang, Danlu Chen, Tianhong Li, Felix Wu, Laurens van der Maaten, and Kilian Weinberger. Multi-scale dense networks for resource efficient image classification. In ICLR, 2018. [11]Brandon Yang, Gabriel Bender, Quoc V Le, and JiquanNgiam. Condconv: Conditionally parameterized convolutions for effi- cient inference. In NeurIPS, 2019. [12]Sara Sabour, Nicholas Frosst, and Geoffrey E Hinton. Dynamic routing between capsules. In NeurIPs, 2017. [13]Ji Lin, Yongming Rao, Jiwen Lu, and Jie Zhou. Runtime neural pruning. In NeurIPS, 2017. [14]Noam Shazeer, AzaliaMirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. In ICLR, 2017. [15]Yinpeng Chen, Xiyang Dai, Mengchen Liu, Dongdong Chen, Lu Yuan, and Zicheng Liu. Dynamic convolution: Attention over convolution kernels. In CVPR, 2020. [16]Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In CVPR, 2018. [17]Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. Cbam: Convolutional block attention module. In ECCV, 2018. [18]Jiaolong Yang, Peiran Ren, Dongqing Zhang, Dong Chen, Fang Wen, Hongdong Li, and Gang Hua. Neural aggregation network for video face recognition. In CVPR, 2017. [19]Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neu- ral networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017. [20]Gao Huang, Shichen Liu, Laurens Van der Maaten, and Kilian Q Weinberger. Condensenet: An efficient densenet using learned group convolutions. In CVPR, 2018. [21]ItayHubara, Matthieu Courbariaux, Daniel Soudry, Ran El-Yaniv, and YoshuaBengio. Binarized neural networks. In NeurIPS, 2016. [22]Le Yang, Yizeng Han, Xi Chen, Shiji Song, Jifeng Dai, and Gao Huang. Resolution Adaptive Networks for Efficient Inference. In CVPR, 2020.[23]Michael Figurnov, Maxwell D Collins, Yukun Zhu, Li Zhang, Jonathan Huang, Dmitry Vetrov, and Ruslan Salakhutdinov. Spa- tially adaptive computation time for residual networks. In CVPR, 2017. [24]Xiaoxiao Li, Ziwei Liu, Ping Luo, Chen Change Loy, and Xiaoou Tang. Not all pixels are equal: Difficulty-aware semantic segmen- tation via deep layer cascade. In CVPR, 2017. [25]Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszko- reit, and Lukasz Kaiser. Universal Transformers. In ICLR, 2019. [26]MahaElbayad, Jiatao Gu, Edouard Grave, and Michael Auli. Depth-Adaptive Transformer. In ICLR, 2020. [27]David H Hubel and Torsten N Wiesel. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. The Journal of physiology, 1962. [28]Akira Murata, Vittorio Gallese, Giuseppe Luppino, Masakazu Kaseda, and Hideo Sakata. Selectivity for the shape, size, and orientation of objects for grasping in neurons of monkey parietal area aip. Journal of neurophysiology, 2000. [29]Yulin Wang, KangchenLv, Rui Huang, Shiji Song, Le Yang, and Gao Huang. Glance and focus: a dynamic approach to reducing spatial redundancy in image classification. In NeurIPS, 2020. [30]Paul Viola and Michael J. Jones. Robust real-time face detection. IJCV, 2004. [31]Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Ge- offrey E Hinton. Adaptive mixtures of local experts. Neural computation, 1991. [32]Wolfgang Maass. Networks of spiking neurons: the third gener- ation of neural network models. Neural networks, 1997. [33]Eugene M Izhikevich. Simple model of spiking neurons. TNN, 2003. [34]TolgaBolukbasi, Joseph Wang, OferDekel, and Venkatesh Saligrama. Adaptive neural networks for efficient inference. In ICML, 2017. [35]Surat Teerapittayanon, Bradley McDanel, and Hsiang-Tsung Kung. Branchynet: Fast inference via early exiting from deep neural networks. In ICPR, 2016. [36]Xin Wang, Fisher Yu, Zi-Yi Dou, Trevor Darrell, and Joseph E Gonzalez. Skipnet: Learning dynamic routing in convolutional networks. In ECCV, 2018. [37]Zuxuan Wu, Tushar Nagarajan, Abhishek Kumar, Steven Rennie, Larry S Davis, Kristen Grauman, and RogerioFeris. Blockdrop: Dynamic inference paths in residual networks. In CVPR, 2018. [38]Andrew Davis and ItamarArel. Low-rank approximations for conditional feedforward computation in deep neural networks. arXiv preprint arXiv:1312.4461, 2013. [39]Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Ge- offrey E Hinton. Adaptive mixtures of local experts. Neural computation, 1991. [40]David Eigen, Marc’AurelioRanzato, and Ilya Sutskever. Learning factored representations in a deep mixture of experts. In ICLR Workshop, 2013. [41]Weizhe Hua, Yuan Zhou, Christopher M De Sa, Zhiru Zhang, and G Edward Suh. Channel gating neural networks. In NeurIPS, 2019. [42]Chuanjian Liu, Yunhe Wang, Kai Han, Chunjing Xu, and Chang Xu. Learning instance-wise sparsity for accelerating deep models. In IJCAI, 2019.[43]Yue Wang, Jianghao Shen, Ting-Kuei Hu, Pengfei Xu, Tan Nguyen, Richard G. Baraniuk, Zhangyang Wang, and Yingyan Lin. Dual dynamic inference: Enabling more efficient, adaptive and controllable deep inference. JSTSP, 2020. [44]Wenhan Xia, Hongxu Yin, Xiaoliang Dai, and Niraj K Jha. Fully dynamic inference with deep neural networks. arXiv preprint arXiv:2007.15151, 2020. [45]Jifeng Dai, Haozhi Qi, YuwenXiong, Yi Li, Guodong Zhang, Han Hu, and Yichen Wei. Deformable convolutional networks. In ICCV, 2017. [46]Xizhou Zhu, Han Hu, Stephen Lin, and Jifeng Dai. Deformable convnets v2: More deformable, better results. In CVPR, 2019. [47]Hang Gao, Xizhou Zhu, Stephen Lin, and Jifeng Dai. Deformable Kernels: Adapting Effective Receptive Fields for Object Deformation. In ICLR, 2019. [48]Xu Jia, Bert De Brabandere, TinneTuytelaars, and Luc V Gool. Dynamic filter networks. In NeurIPS, 2016. [49]David Ha, Andrew Dai, and Quoc V Le. Hypernetworks. In ICLR, 2016.[50]Ningning Ma, Xiangyu Zhang, Jiawei Huang, and Jian Sun. WeightNet: Revisiting the Design Space of Weight Networks. In ECCV, 2020. [51]Fei Wang, Mengqing Jiang, Chen Qian, Shuo Yang, Cheng Li, Honggang Zhang, Xiaogang Wang, and Xiaoou Tang. Residual attention network for image classification. In CVPR, 2017. [52]Abhijit Guha Roy, Nassir Navab, and Christian Wachinger. Con- current spatial and channel ‘squeeze &excitation’in fully convo- lutional networks. In MICCAI, 2018. [53]Yinpeng Chen, Xiyang Dai, Mengchen Liu, Dongdong Chen, Lu Yuan, and Zicheng Liu. Dynamic relu. In ECCV, 2020. [54]BoleiZhou, AdityaKhosla, AgataLapedriza, Aude Oliva, and Antonio Torralba. Learning deep features for discriminative localization. In CVPR, 2016.[55]Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neu- ral networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017. [56]ZhendaXie, Zheng Zhang, Xizhou Zhu, Gao Huang, and Stephen Lin. Spatially Adaptive Inference with Stochastic Feature Sam- pling and Interpolation. In ECCV, 2020. [57]Alexander Kirillov, Yuxin Wu, Kaiming He, and Ross Girshick. Pointrend: Image segmentation as rendering. In CVPR, 2020. [58]Jin Chen, Xijun Wang, Zichao Guo, Xiangyu Zhang, and Jian Sun. Dynamic region-aware convolution. arXiv preprint arXiv:2003.12243, 2020. [59]Max Jaderberg, Karen Simonyan, and Andrew Zisserman. Spatial transformer networks. In NeurIPS, 2015. [60]Adria Recasens, Petr Kellnhofer, Simon Stent, Wojciech Matusik, and Antonio Torralba. Learning to zoom: a saliency-based sam- pling layer for neural networks. In ECCV, 2018.[61]Zerui Yang, Yuhui Xu, Wenrui Dai, and HongkaiXiong. Dynamic-stride-net: deep convolutional neural network with dynamic stride. In SPIE Optoelectronic Imaging and Multimedia Technology, 2019. [62]V ́ıctor Campos, Brendan Jou, Xavier Giro ́-I-Nieto, Jordi Torres, and Shih Fu Chang. Skip RNN: Learning to skip state updates in recurrent neural networks. In ICLR, 2018.[63]MinjoonSeo, Sewon Min, Ali Farhadi, and HannanehHajishirzi. Neural Speed Reading via Skim-RNN. In ICLR, 2018. [64]Junyoung Chung, SungjinAhn, and YoshuaBengio. Hierarchical multiscale recurrent neural networks. In ICLR, 2017. [65]Zhengjie Huang, Zi Ye, Shuangyin Li, and Rong Pan. Length adaptive recurrent model for text classification. In CIKM, 2017. [66]Keyi Yu, Yang Liu, Alexander G. Schwing, and Jian Peng. Fast and accurate text classification: Skimming, rereading and early stopping. In ICLR Workshop, 2018. [67]Hao Li, Hong Zhang, Xiaojuan Qi, Ruigang Yang, and Gao Huang. Improved techniques for training adaptive deep net- works. In ICCV, 2019. [68]YoshuaBengio, Nicholas Le ́onard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432, 2013. [69]Junyoung Chung, SungjinAhn, and YoshuaBengio. Hierarchical multiscale recurrent neural networks. In ICLR, 2017. [70]Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameter- ization with gumbel-softmax. In ICLR, 2017. [71]Andreas Veit and Serge Belongie. Convolutional networks with adaptive inference graphs. In ECCV, 2018. [72]Rahul Duggal, Scott Freitas, Sunny Dhamnani, DuenHorng, Chau, and Jimeng Sun. ELF: An Early-Exiting Framework for Long-Tailed Classification. arXiv:2006.11979 [cs, stat], 2020. [73]ClemensRosenbaum,TimKlinger,andMatthewRiemer.Routing networks: Adaptive selection of non-linear functions for multi- task learning. In ICLR, 2018. [74]Ting-Kuei Hu, Tianlong Chen, Haotao Wang, and Zhangyang Wang. Triple Wins: Boosting Accuracy,Robustness and Efficiency Together by Enabling Input-Adaptive Inference. In ICLR, 2020.[75]Sanghyun Hong, Yi˘gitcan Kaya, Ionut¸-Vlad Modoranu, and Tudor Dumitras¸. A panda? no, it’s a sloth: Slowdown attacks on adaptive multi-exit neural network inference. arXiv preprint arXiv:2010.02432, 2020.
© THE END 转载请联系本公众号获得授权 投稿或寻求报道:content@jiqizhixin.com


