

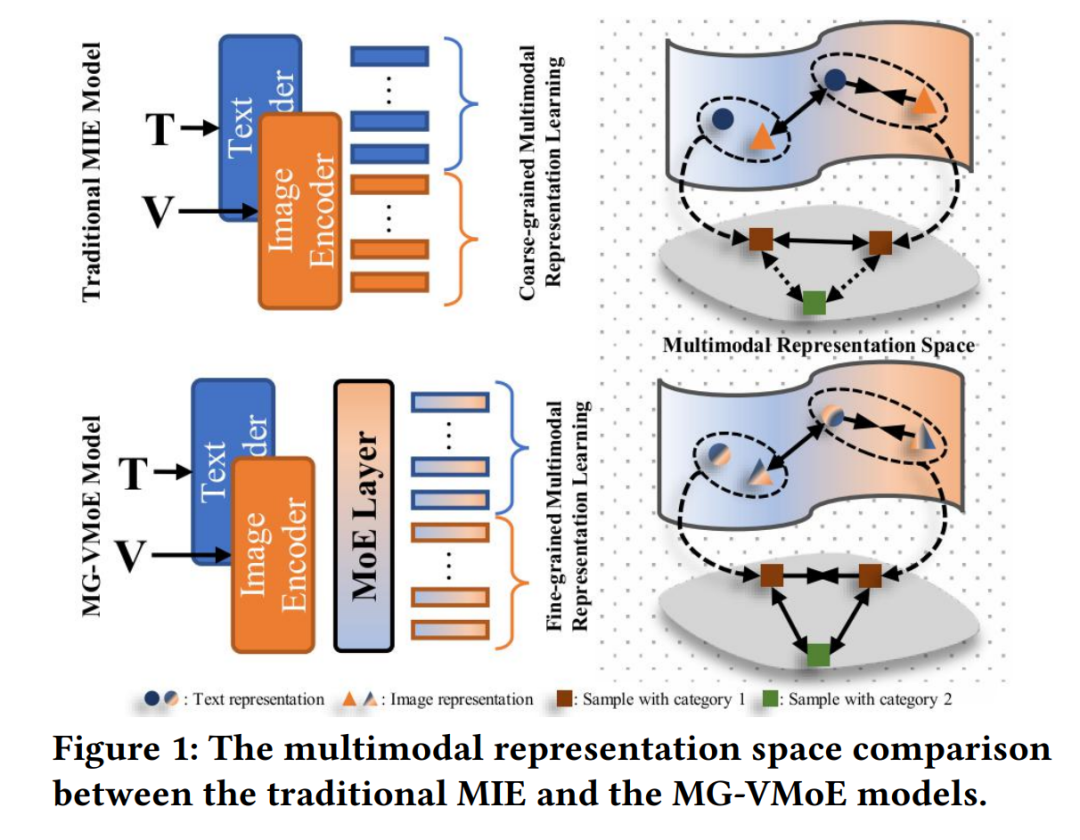
社交媒体多模态信息抽取是构建多模态知识图谱的基础任务,旨在从文本-图像混合数据中提取结构化信息,包括多模态命名实体分类与多模态关系抽取。然而,随着多模态数据规模的增长,实体类型与关系类别持续扩展,模型需具备零样本学习能力以识别未见类别。针对这一挑战,本文提出基于多模态图结构的专家混合变分网络(MG-VMoE),其核心创新如下: 1. 细粒度模态对齐
以专家混合网络(MoE)为骨干,通过变分信息瓶颈(Variational Information Bottleneck)统一处理文本-视觉模态,学习更具判别力的跨模态表示。 * 相较现有方法直接对齐模态的粗粒度策略,MG-VMoE显式建模样本间细粒度语义关联。 1. 对抗训练优化
提出多模态图虚拟对抗训练机制,利用图结构捕捉样本间的拓扑约束,增强模型对噪声的鲁棒性。
在两大基准数据集上的实验表明,MG-VMoE显著优于基线模型,尤其在零样本场景下F1值提升12.7%。本研究为开放类别多模态信息抽取提供了新范式。
成为VIP会员查看完整内容
相关内容
Arxiv
224+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日