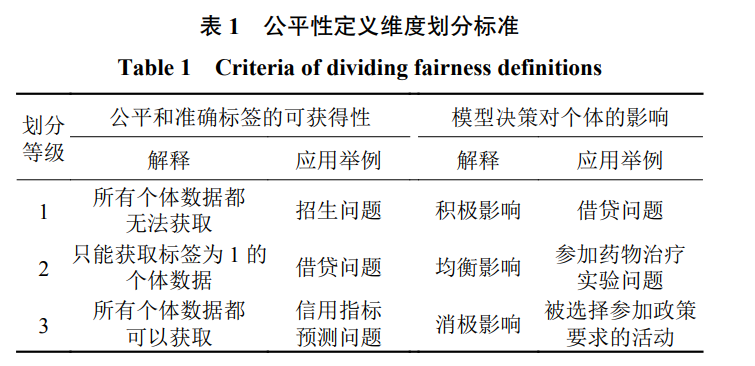
机器学习技术不断发展,在许多领域都有广泛的应用并展现出超出人类本身的能力。但机器学习方法利用不 当或决策存在偏差,反而会损害人们的利益,特别是在一些敏感安全需求高的领域,如金融、医疗等,人们越来越 重视机器学习的可信研究。目前,机器学习技术普遍存在一些缺点,如对代表性不足的群体存在偏见、缺乏用户隐 私保护、缺乏模型可解释性、容易受到威胁攻击等。这些缺点降低了人们对机器学习方法的信任。尽管研究者已针 对这些不足进行了深入探索,但缺乏一个整体的框架与方法系统地提供机器学习的可信分析。因此本文针对机器学 习的公平性、可解释性、鲁棒性与隐私 4 个要素归纳总结了现阶段主流的定义、指标、方法与评估,然后讨论了各 要素之间的关系,并结合机器学习全生命周期构建了一个可信机器学习框架。最后,给出了一些目前可信机器学习 领域亟待解决的问题与面临的挑战。 机器学习是人工智能领域的一个重要分支,是 对通过学习经验数据提高计算机系统或算法性能以 适应各种环境和任务的研究[1]。该方法作为当今发 展速度最快的技术之一,受到了学界和业界的广泛 关注与认可,在各行各业都得到了广泛的应用[2], 在图像识别、自然语言处理、数据挖掘与预测等关 键任务上都展现出了超越人类的能力[3]。随着机器 学习在大众生活中的不断渗入与广泛应用,人们越 发依赖其做出的关键决策。但如果机器学习方法利 用不当或给出决策存在偏差,反而会损害人们的利益。因此机器学习的可信赖性越发受到人们的重 视,以公平性、可解释性、鲁棒性和隐私为要素的 机器学习可信特征越发成为热门研究领域[4-5]。 机器学习的全生命周期可以分为预处理 (preprocessing) 、中间处理 (in-processing) 和后处理 (post-processing) 3 个阶段[6]。预处理阶段主要是对 训练数据进行管理,如数据收集、数据预处理等; 中间处理阶段主要是对模型或算法进行选择、调整 和优化;后处理阶段主要是对测试模型和数据的处 理,如模型泛化性验证、模型输出结果校准等。 在不同的阶段,机器学习可信特征对应的问题 和方法也不尽相同。例如,公平性中消除偏差机制 在预处理阶段表现为消除原始训练数据中敏感特征 信息;在中间处理阶段表现为在机器学习模型中添 加约束或正则项;在后处理阶段表现为校准机器学 习算法输出结果[7-9]。可解释性大致可以分为事前 (ante-hoc) 可解释性和事后 (post-hoc) 可解释性[10]。 事后可解释性在预处理阶段表现为对模型输入的解 释,如数据提取逻辑解释等;在中间处理阶段表现 为对模型本身的解释,如模型结构和参数信息解释 等;在后处理阶段表现为对模型输出的解释,如模 型诊断、特征评估等。隐私中隐私泄漏问题在预处 理阶段表现为收集大量训练数据导致的直接隐私泄 露;在中间处理阶段表现为模型泛化能力欠缺导致 的间接隐私泄漏[11]。 目前,对机器学习可信特征 4 种要素的研究存 在很多能够改进完善的空间,且缺乏一种统一的用 于评估机器学习模型可信度的标准和系统[4, 12]。本文 旨在归纳整理目前可信机器学习的研究现状,明确 可信特征各要素的定义、分类与应用,构建一种统 一的可信机器学习阶段评估模型,为后续可信机器 学习相关研究提供研究思路和方向。