

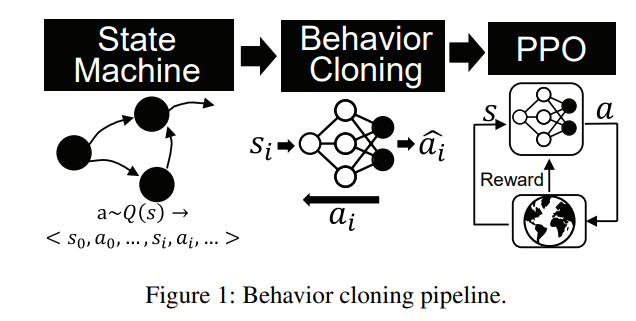
现代建模和仿真环境(如商业游戏或军事训练系统)经常要求交互式智能体按照预先确定的规范(如故事板或军事战术文件)表现出逼真和反应灵敏的行为。创建智能体的传统方法(如状态机或行为树)需要花费大量精力,通过人工知识工程来开发状态表示和转换过程。另一方面,较新的行为生成技术(如深度强化学习)需要大量的训练数据(在许多情况下需要几个世纪),而且无法保证生成的行为与预期目标和行动方案一致。本文研究了行为克隆方法在设计交互式智能体中的应用。在我们的方法中,用户首先通过状态机模型或行为树等直接方法定义所需的行为。然后,使用行为克隆方法将从这些模型中采样的真实轨迹数据转化为可微分策略,并通过参与互动游戏环境进一步完善这些策略。通过对任务性能和训练稳定性进行比较,这种方法可以改善训练结果。

成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2023年10月5日
Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年10月5日
Arxiv
224+阅读 · 2023年4月7日