

近年来深度学习在计算机视觉 (CV) 和自然语言处理 (NLP) 等单模态领域都取得了十分优异的性能. 随着 技术的发展, 多模态学习的重要性和必要性已经慢慢展现. 视觉语言学习作为多模态学习的重要部分, 得到国内外 研究人员的广泛关注. 得益于 Transformer 框架的发展, 越来越多的预训练模型被运用到视觉语言多模态学习上, 相关任务在性能上得到了质的飞跃. 系统地梳理了当前视觉语言预训练模型相关的工作, 首先介绍了预训练模型 的相关知识, 其次从两种不同的角度分析比较预训练模型结构, 讨论了常用的视觉语言预训练技术, 详细介绍了 5 类下游预训练任务, 最后介绍了常用的图像和视频预训练任务的数据集, 并比较和分析了常用预训练模型在不同 任务下不同数据集上的性能.
http://www.jos.org.cn/jos/article/abstract/6774
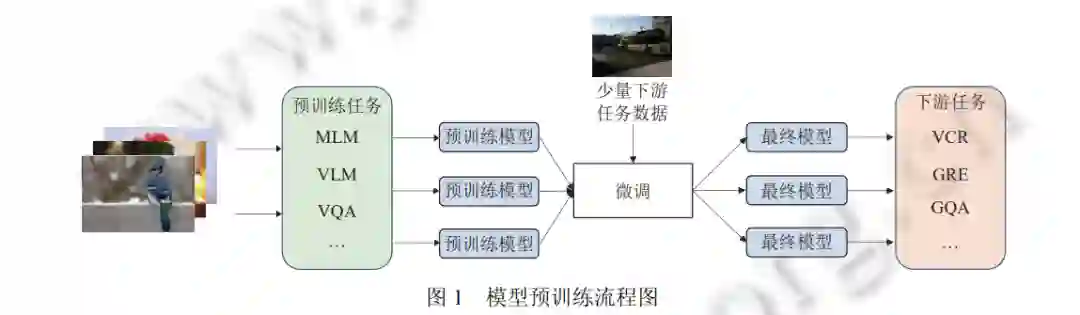
机器学习的目标是让机器像人一样感受世界和理解世界. 正如人的感官能去感知一样, 多模态机器学习旨在 处理和理解不同模态 (诸如视觉、语言、听觉等) 交织融合的信息. 从过去到现在, 研究者们已经做出了很多单模 态学习的工作, 诸如人脸识别、目标检测等, 并从科学研究扩展到产业落地, 最后服务于生活. 但是随着深度学习 技术的发展, 多模态学习慢慢展现出其重要性和必要性[1] . 作为人类生活中最重要的文化载体, 视觉和语言在多模 态学习领域承载着十分重要的一部分, 在近几年里, 视觉语言多模态学习也得到了广泛地关注和飞速地发展. 通 常, 参数较大的模型往往需要大量的标注数据来进行训练, 但由于多模态标注技术、标注成本等一系列因素的制 约, 高质量的标签数据始终比较缺乏, 这也给模型的性能提升带来了瓶颈. 2017 年美国谷歌公司研究人员提出 Transformer[2]的基础框架, 用于解决这个问题. Transformer 模型首先通过 自监督学习进行预训练, 通过一系列的任务来从大规模的无标注数据中挖掘监督信息以训练模型, 从而来学习数 据的一般化表征. 然后对于不同的下游任务只需要采用少量的人工标注的数据进行微调就能达到优异的效果, 预 训练流程见图 1 所示. 在自然语言处理 (NLP) 领域中, BERT[3]的出现后, 各种预训练任务便如雨后春笋般涌现出 来, 诸如 GPT[4]系列, MASS[5]等. 不仅仅局限在 NLP 领域, 计算机视觉 (CV) 领域中也出现了许多杰出的预训练方 法, 比如 ViT[6]等. 与此同时, 模型预训练技术也在多模态领域得到了研究人员越来越多的关注, 特别是在视觉-语 言联合表征学习方面, 预训练模型在各种下游任务上都取得了优异的性能.
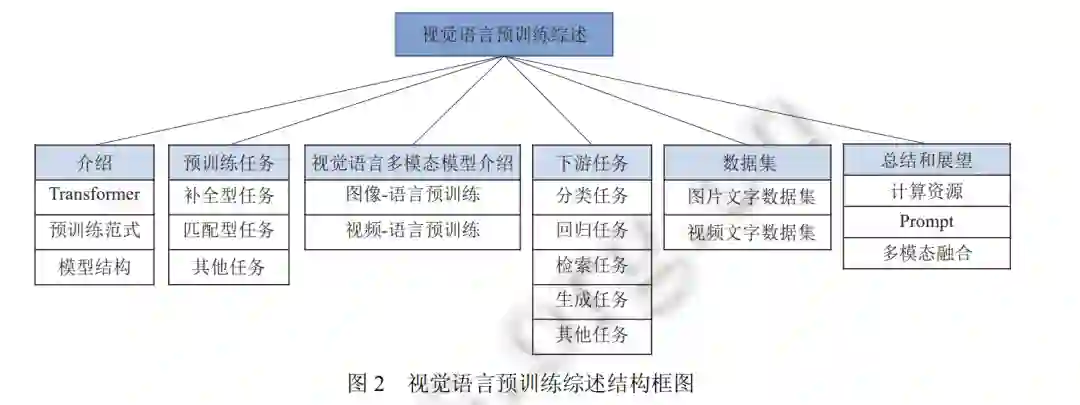
如后文图 2 所示, 本文将围绕视觉语言预训练模型展开介绍, 并通过以下 6 个重要方面详细介绍和讨论视觉 语言预训练模型的最新进展: 首先介绍视觉语言预训练模型的相关知识, 包括 Transformer 框架、模型预训练范式 和视觉语言预训练模型常见网络结构; 其次介绍 3 类模型预训练任务, 通过这些任务, 网络模型可以在无标注的情 况下进行跨模态的语义对齐; 然后我们将从图像-文本预训练和视频-文本预训练两个方面分别来介绍最新的工作 进展; 同时我们也将对预训练模型的下游任务进行分类和介绍; 接着将介绍广泛使用的图像文本和视频文本的多 模态数据集, 并比较和分析了常用预训练模型在不同任务下不同数据集上的性能; 最后对视觉语言预训练进行总 结和展望.
** 1 介 绍 **
在本节中, 我们将介绍与视觉、语言预训练相关的背景基础知识. 第 1.1 节将介绍 Transformer 的关键机制和 结构; 第 1.2 节将介绍当前比较流行的预训练范式, 包括预训练-微调学习和预训练-提示语学习; 第 1.3 节从两个 不同的角度介绍了当前视觉语言预训练的模型结构.
**1.1 Transformer **
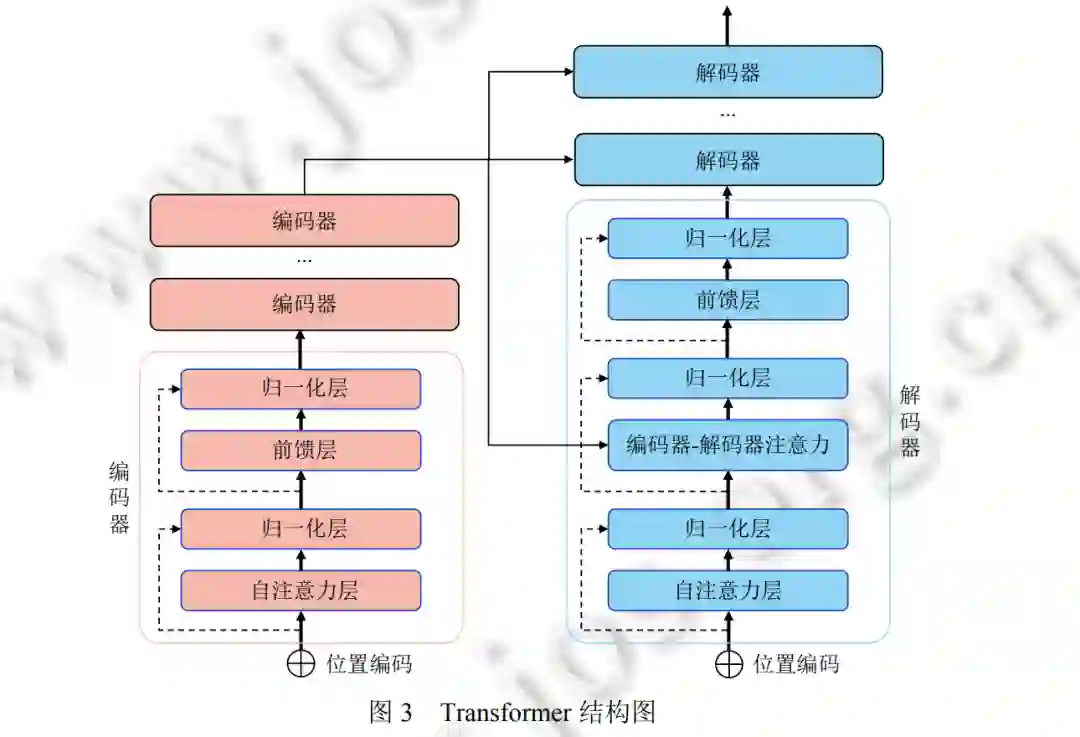
Transformer[2]最早在自然语言处理 (NLP) 领域提出, 并在各种任务上表现出很好的性能. 在此之后, 它也被成 功应用于其他领域, 从语言再到视觉领域. 如图 3 所示, 一个标准的 Transformer 由几个编码器块和解码器块组成. 每个编码器块包含一个自注意 (self-attention[2] ) 层和一个前馈 (feed forward) 层. 不同于编码器块, 每个解码器块除 了自注意力层和前馈层外, 还包含一个编解码注意力层。
**1.2 预训练范式 **
**1.2.1 预训练-微调 (pretrain fine-tuning) **
预训练-微调已经成了经典的预训练范式. 其做法是: 首先以监督或无监督的方式在大型数据集上预训练模型, 然后通过微调将预训练的模型在较小的数据集上适应特定的下游任务. 这种模式可以避免为不同的任务或数据集从头开始训练新模型. 越来越多的实验证明, 在较大的数据集上进行预训练有助于学习通用表征, 从而提高下游任 务的性能. GPT[4]在对有 7 000 本未出版书籍的 BooksCorpus 数据集[10]进行预训练后, 在 9 个下游基准数据集 (如 CoLA[11]、MRPC[12]上获得平均 10% 的性能大提升. 视觉模型 ViT-L/32[6]在对拥有 3 亿张图像的 JFT-300M[13]进行 预训练后, 在 ImageNet[14]的测试集上获得了 13% 的准确率提升. 目前, 预训练微调范式在 NLP 和 CV 领域都在如火如荼展开工作, 多模态领域也不例外, 大量优秀的工作在 此诞生, 包括图像-文本和视频-文本领域.
1.2.2 预训练-提示 (pretrain prompt)
提示学习起源于 NLP 领域, 随着预训练语言模型体量的不断增大, 对其进行微调的硬件要求、数据需求和实 际代价也在不断上涨. 除此之外, 丰富多样的下游任务也使得预训练-微调阶段的设计变得繁琐复杂, 提示学习就 此诞生. 在预训练-提示范式中通常使用一个模板来给预训练模型提供一些线索和提示, 从而能够更好地利用预训 练语言模型中已有的知识, 以此完成下游任务. 在 GPT-3[15]中, 所有任务都可以被统一建模, 任务描述与任务输入视为语言模型的历史上下文, 而输出则为语 言模型需要预测的未来信息, 通过给予模型一些提示语, 让模型根据提示语来生成所需要的输出, 这种方式也被称 为是情景学习 (in-context learning). Prefix-Tuning[16]摒弃了人工设计模板或自动化搜索模板的方式, 提出了任务特 定的可训练前缀. P-tuning V1[17]首次提出了用连续空间搜索的嵌入来做提示语. P-tuning V2[18]引入深度提示编码 (deep prompt encoding) 和多任务学习 (multi-task learning) 等策略进行优化, 解决 V1 版本在一些复杂的自然语言 理解任务上任务不通用和规模不通用的问题. 提示学习相对于微调的优势在于: 1) 计算代价非常低. 由于整个模型的参数都是固定的, 并不需要对模型中所 有的参数进行微调. 2) 非常节省空间. 在使用预训练模型进行微调时, 每个不同的下游任务的参数都会相应改变, 因此每个任务都需要进行存储, 而提示学习则不需要. 基于这些优势, 提示学习已经称为了 NLP 领域的又一大研 究热点, 预训练-提示也作为继预训练-微调的又一大范式, 处处崭露头角. 在多模态领域也慢慢燃起了提示学习之 火, 诸如 CLIP[19] , CPT[20]等出色的工作应运而生.
**1.3 模型结构 **
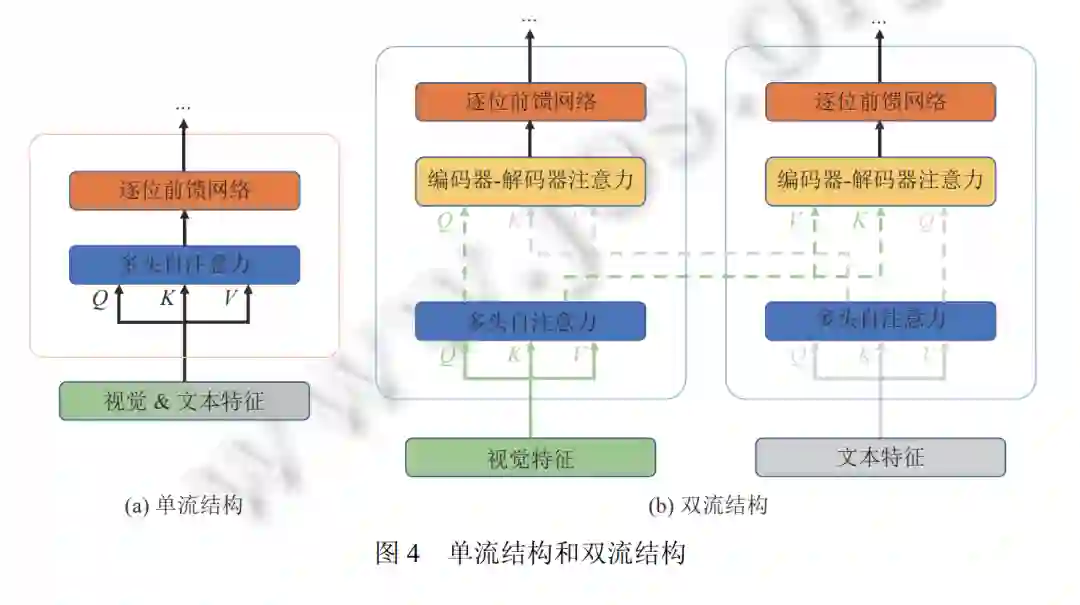
在本节中, 我们从两个不同的角度介绍视觉语言预训练模型的体系结构: (1) 从多模态融合的角度对比单流结 构与双流结构. (2) 从整体架构设计的角度对比仅编码结构和编码-解码结构.
**2 预训练任务 **
本节将介绍如何使用不同的预训练任务对视觉语言预训练模型进行预训练, 这对于模型学习视觉语言的一般 化表征至关重要. 我们将预训练任务归纳为 3 类: 补全型、匹配型、其他型. 补全型任务通过利用未被掩码的剩余信息来理解模态, 从而重建补全被掩码的元素. 匹配型任务是将视觉和语言统一到一个共同的潜在空间中来生成一个一般化的视觉-语言表达. 其他型任务的内容中包含了其他预训练任务.
**3 视觉语言多模态模型介绍 **
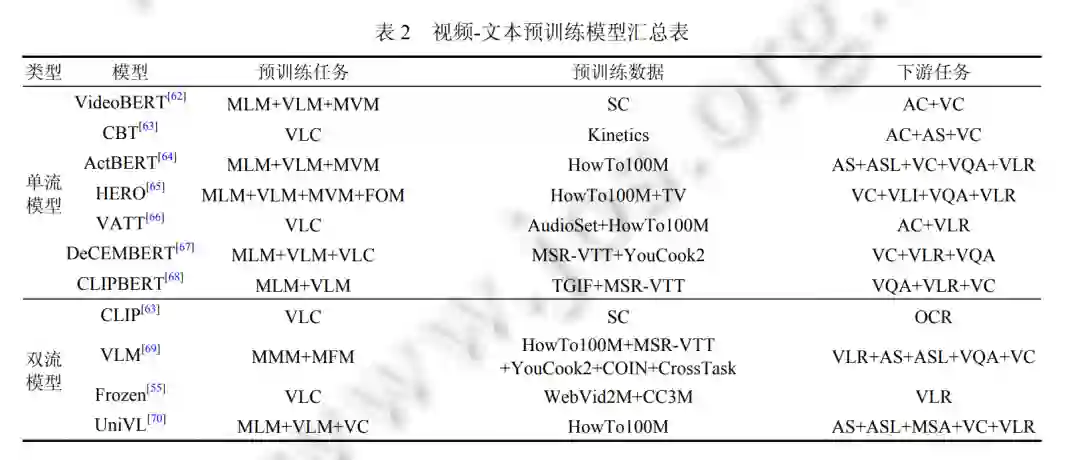
视觉和语言是人类感知世界的两个重要方面, 因此训练神经网络模型处理多模态信息对于人工智能的发展有 着重要的意义. 近年来, 许多研究工作通过对其视觉和语言的语义信息实现了各种跨模态任务. 其中图像文本预训 练和视频文本预训练得到了最广泛的研究. 本节我们将介绍图像-文本预训练和视频-文本预训练两个方面近年来 的最新进展.
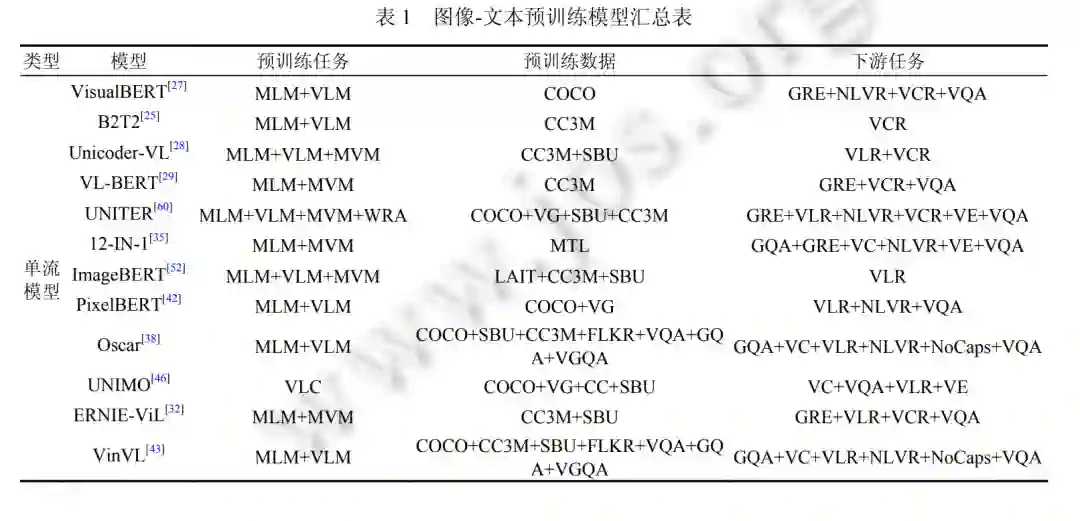
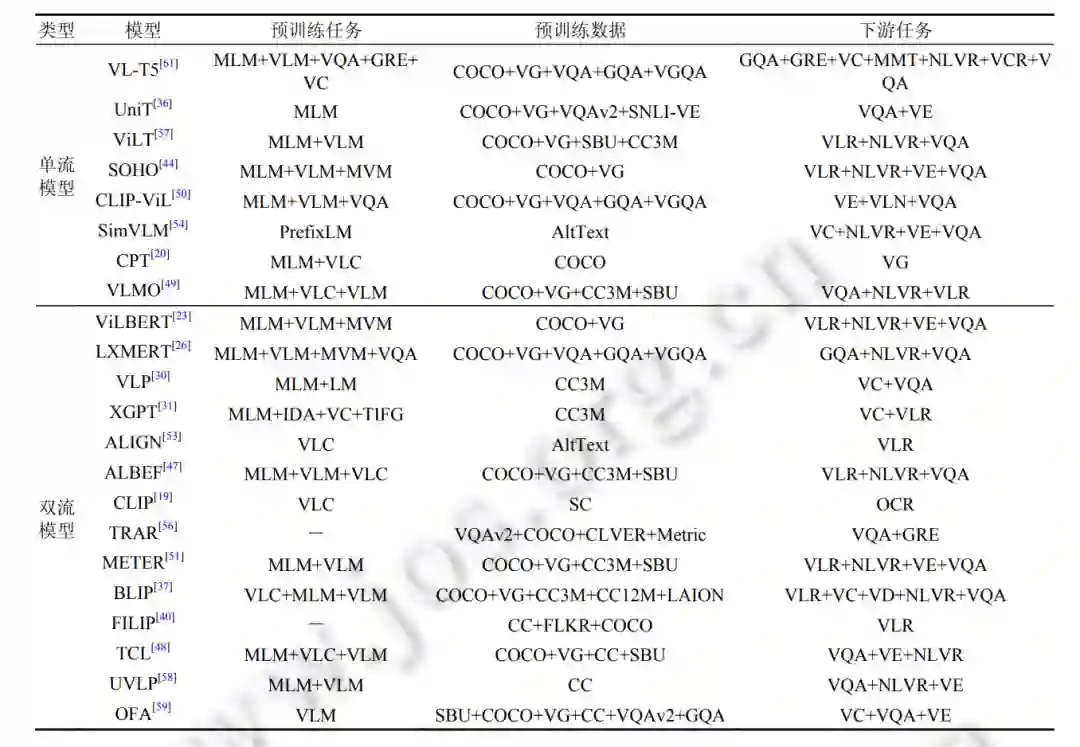
**4 下游任务 **
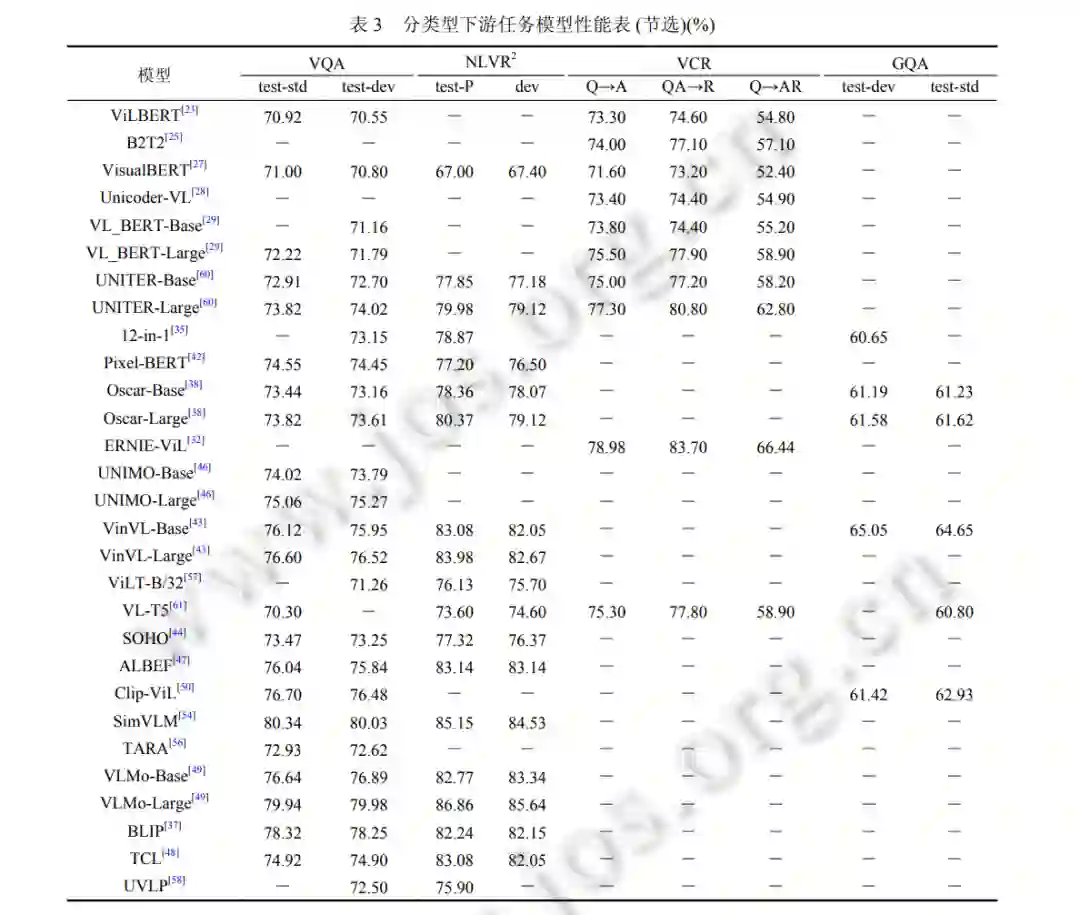
多样化的任务需要视觉和语言的融合知识. 在本节中, 我们将介绍此类任务的基本细节和目标, 并将其分为 4 类: 分类、检索、生成和其他任务. 常见视觉语言预训练模型 对应分类型下游任务如表 3 所示, 包括视觉问答 (VQA), 自然语言视觉推理 (NLVR), 视觉常识推理 (VCR) 和视觉 推理和组合式问答 (GQA), 由于视觉语言预训练任务所包含的下游任务繁多, 表 3 中仅节选出最为常见的下游任 务进行性能的统计与比较.
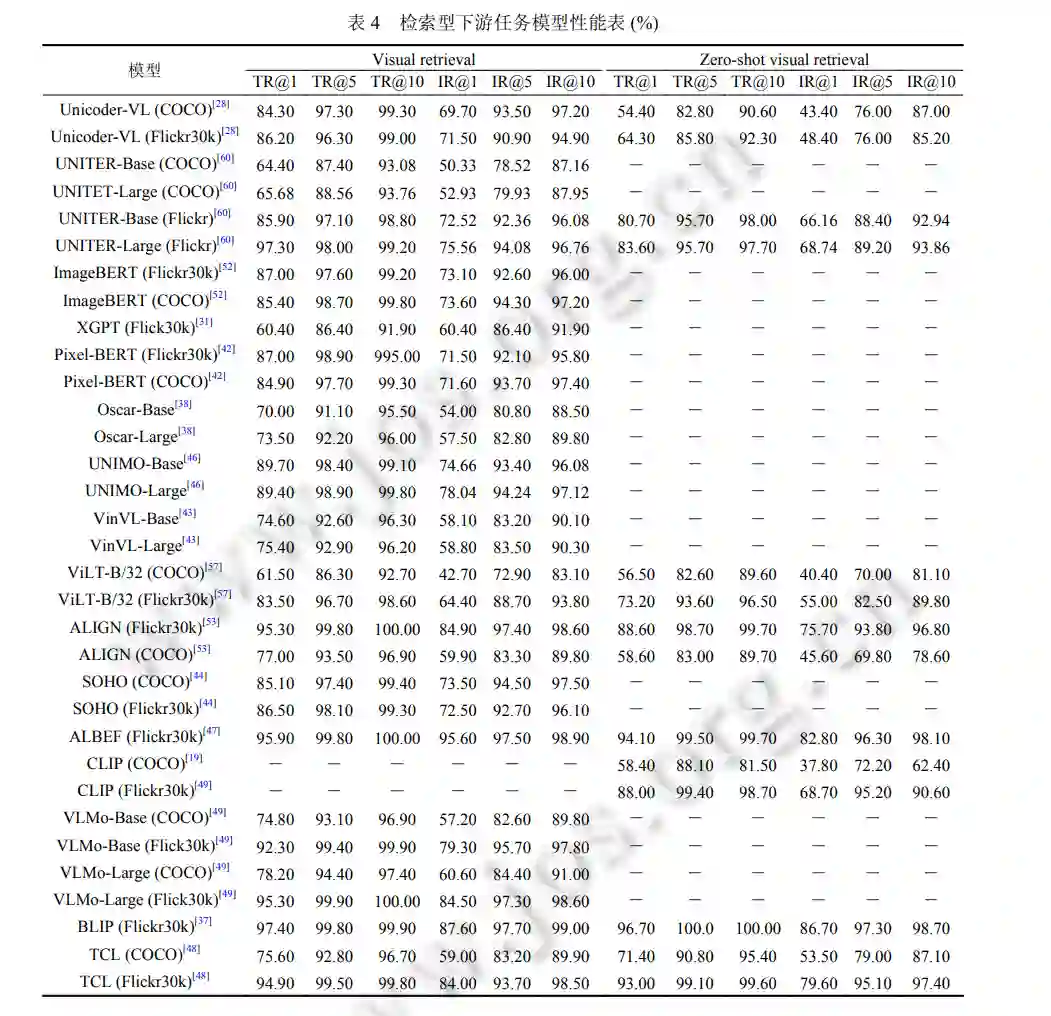
视觉-语言检索 (vision-language retrieval, VLR). VLR 涉及对视觉 (图像或视频) 和语言的理解, 以及适当的匹 配策略. 它包括两个子任务: 从视觉到文本和从文本到视觉的检索, 其中视觉到文本检索是根据视觉从更大的描述库中获取最重要的相关文本描述, 反之亦然. 常见视觉语言预训练模型对应检索型下游任务如表 4 所示, 包括视觉语言检索和零样本 (zero-shot) 的视觉-语言检索。
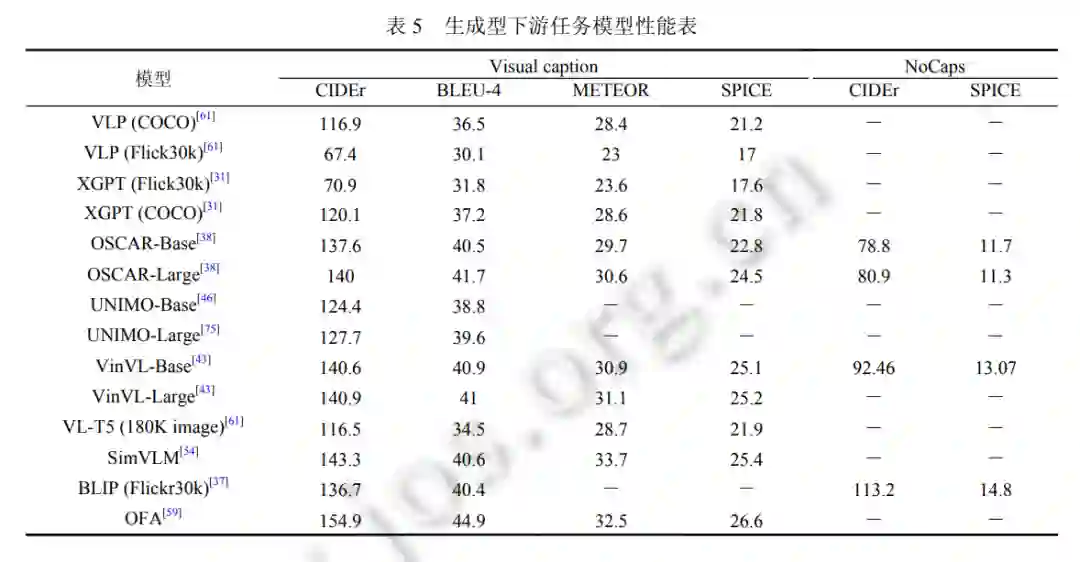
视觉描述 (visual captioning, VC). VC 旨在为给定的视觉 (图像或视频) 输入生成语义和句法上合适的文本描 述. 大规模新物体描述 (novel object captioning at scale, NoCaps): NoCaps[74]扩展了 VC 任务, 以测试模型描述来自 Open Images 数据集的新物体的能力, 这些物体都未曾在训练语料库中出现过. 视觉对话 (visual dialogue, VD): 常见视觉语言预训练模型对应生成型下游任务如表 5 所示, 包括视觉描述和大规模新物体描述. 其中, CIDEr、BLEU-4、METEOR、SPICE 为 4 个评价生成语句的指标.
**5. 总结和展望 **
在本文中, 首先我们介绍了视觉语言预训练模型的相关知识, 包括 Transformer 框架、预训练范式和视觉语言 预训练模型常见网络结构; 其次我们介绍了 3 类模型预训练任务, 通过这些任务, 网络模型可以在无标注的情况下 进行跨模态的语义对齐; 然后我们从图像-文本预训练和视频-文本预训练两个方面分别介绍了最新的工作进展, 并介绍了预训练模型的下游任务; 最后我们介绍了广泛使用的图像文本和视频文本的多模态数据集, 并比较和分 析了常用预训练模型在不同任务下不同数据集上的性能. 视觉语言预训练在飞速发展的同时也取得了许多非常不 错的成果, 未来视觉语言预训练模型的发展方向可以借鉴如下. (1) 计算资源. 目前视觉语言预训练工作仍然需要极大的算力资源做支撑. 2019 年以来, 视觉语言预训练工作 大部分都是产自于工业界, 需要使用数十上百张显卡进行训练, 导致部分研究人员没有足够的计算资源对其展开 研究, 而且难以对这些大规模工作进行验证. 如何在资源受限的情况下进行视觉语言预训练研究, 是一个很有研究 价值的问题. (2) Prompt. 预训练-提示范式在 NLP 领域引起了一波研究热潮, 我们在第 1.2.2 节已经对其进行了介绍. 提示 相对于微调的优势在于: 1) 计算代价低. 2) 节省空间. 目前已有少数工作对其进行展开了研究, 诸如 CLIP, CPT 等, 并且取得了不错的效果. 预训练-提示范式目前还在探索阶段, 未来将会有更多更有意义的工作出现. (3) 多模态融合. 之前大多数的多模态预训练工作都是强调视觉和语言这两个模态进行建模, 但是忽略了其他 模态 (比如音频等) 信息. 其他模态信息往往也对跨模态学习有着重要的意义, 因此研究更多模态信息建模的工作 是具有研究价值和挑战性的.


