通用基础模型,如GPT-4,在多种领域和任务中展现出了惊人的能力。然而,普遍的假设是,它们在没有对专业知识进行密集训练的情况下,无法匹敌专家的能力。例如,迄今为止在医学能力基准测试上的大多数探索都利用了领域特定的训练,如BioGPT和Med-PaLM的努力就是典范。我们在之前的研究基础上,探讨了GPT-4在没有特殊训练的情况下对医学挑战基准的专家能力。与为了突出模型开箱即用能力而故意使用简单提示不同,我们进行了系统的提示工程探索,以提升性能。我们发现,提示创新可以解锁更深层次的专家能力,并展示出GPT-4在医学问答数据集上轻松超越之前的领先成果。我们探索的提示工程方法具有通用性,不需要特别使用领域专家知识,从而消除了对专家策划内容的需求。我们的实验设计严格控制了在提示工程过程中的过拟合。我们引入了基于多种提示策略组合的Medprompt。Medprompt大幅提升了GPT-4的性能,在MultiMedQA套件中的全部九个基准数据集上都达到了最新的成果。该方法以数量级更少的模型调用次数,大幅超越了如Med-PaLM 2等最新专家模型。使用Medprompt指导GPT-4在MedQA数据集(USMLE考试)上的错误率比迄今为止使用专家模型获得的最佳方法减少了27%,并首次超过了90%的分数。超越了医学挑战问题,我们展示了Medprompt在其他领域的普适性,并通过在电气工程、机器学习、哲学、会计、法律、护理和临床心理学的能力考试中的策略研究,提供了这种方法广泛适用性的证据。
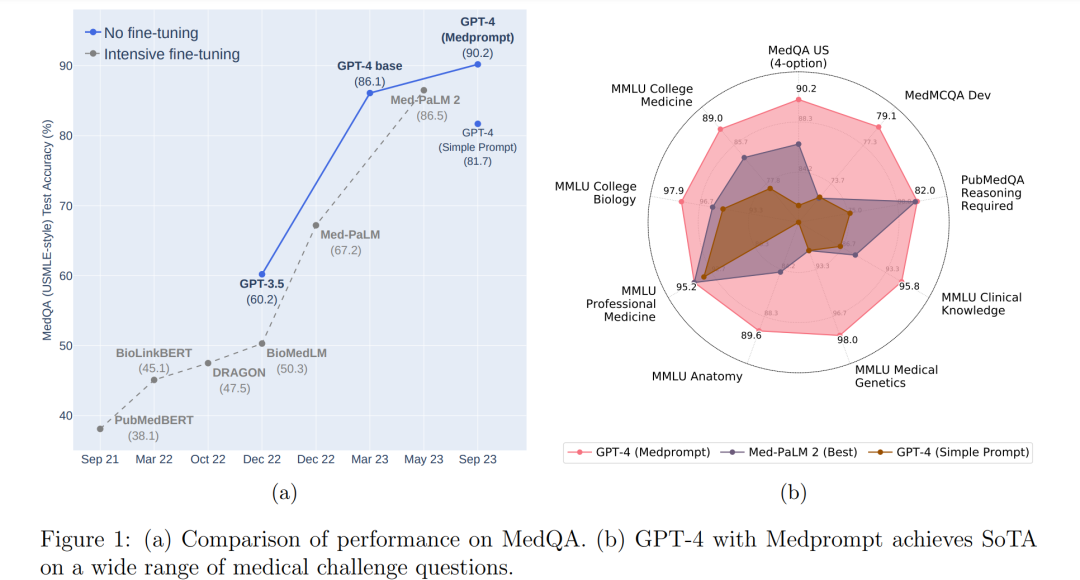
人工智能研究的长期愿景是发展计算智能的原则,并利用这些原则构建能够在多样化任务中进行通用问题解决的学习和推理系统[21, 22]。与这一目标一致,大型语言模型,也被称为基础模型,如GPT-3[3]和GPT-4[24],已在广泛的任务上展现出惊人的能力,而无需重度专业化训练[4]。这些模型基于文本到文本的范式[31],通过在计算和数据上的投入,从大量公共网络数据的不加选择的消费中进行大规模学习。这些模型中的一些通过学习目标进行调整,以通过提示执行通用指令跟随。基础模型性能的核心指标是下一个词预测的准确性。根据实证得出的“神经模型缩放定律”[3, 12],发现在训练数据、模型参数和计算规模方面的增加与下一个词预测的准确性提高相一致。然而,除了基本测量如下一个词预测上的缩放定律预测外,基础模型在不同规模阈值上突然显现了众多问题解决能力[33, 27, 24]。 尽管观察到了一系列通用能力的出现,但关于在没有广泛专业化训练或对通用模型进行微调的情况下,是否能在医学等专业领域的挑战上实现真正卓越的表现,仍然存在疑问。大多数对基础模型在生物医学应用上的能力探索,严重依赖于领域和任务特定的微调。在第一代基础模型中,社区发现了领域特定预训练的明显优势,如生物医学领域流行的模型PubMedBERT[10]和BioGPT[19]所示。但对于在更大规模上预训练的现代基础模型,这是否仍然是这样尚不清楚。 我们在本文中专注于通过提示工程引导基础模型在一系列医学挑战基准上取得优异成绩。Med-PaLM 2在MedQA和其他医学挑战问题上取得了有竞争力的成绩,通过对通用PaLM[6]基础模型[29, 30]进行昂贵的任务特定微调。除了依赖于对基础PaLM模型的微调外,Med-PaLM 2在医学基准上的结果是通过使用由专家制定的复杂的提示策略生成的。例如,许多答案依赖于一个复杂的两阶段提示方案,每个问题需要44次调用来回答。
在2023年3月GPT-4公开后不久,本研究的几位合著者展示了该模型在医学挑战基准上“开箱即用”的令人印象深刻的生物医学能力。为了展示GPT-4在专业医学专长上的潜在能力,合著者故意采用了一种基本的提示策略[23]。尽管在那项研究中展示了强大的成果,但关于GPT-4在没有额外特殊训练或调整的情况下,其领域特定能力的深度仍有疑问。
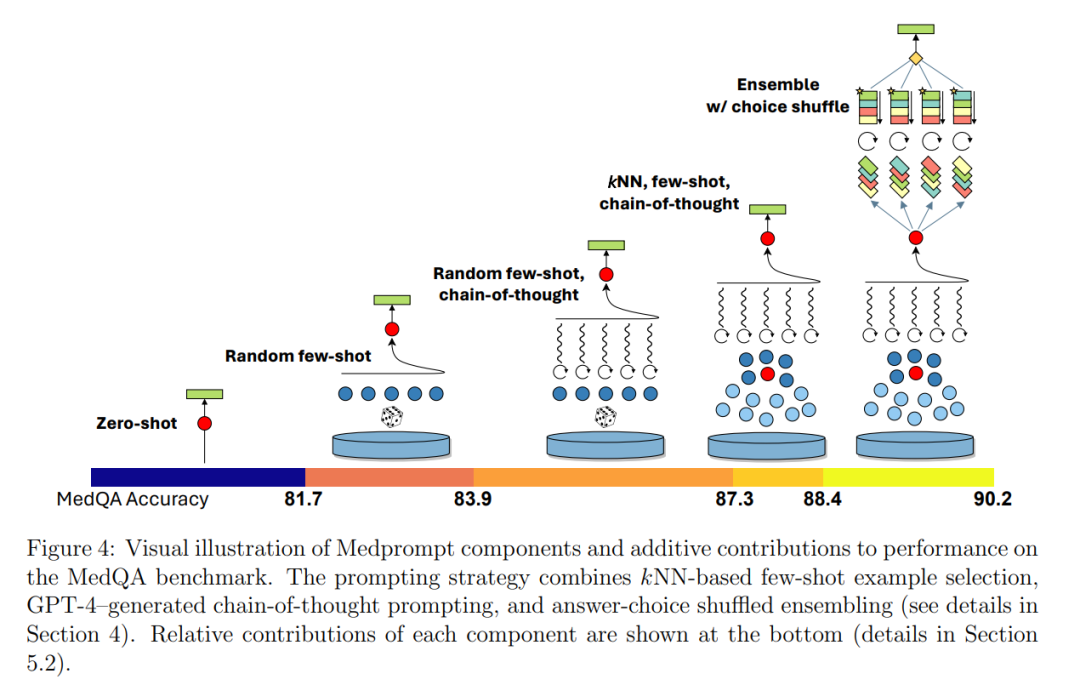
我们展示了通过创新提示策略引导GPT-4回答医学挑战问题的结果和方法的案例研究。我们包括了在评估环境中研究提示的最佳实践的考虑,包括保留一个真正的眼外评估集。我们发现GPT-4确实拥有可以通过提示创新激发的深层专家能力。该性能是通过系统地探索提示策略实现的。作为设计原则,我们选择探索易于执行且未针对我们的基准工作负载定制的提示策略。我们为GPT-4的医学挑战问题找到了一个顶级的提示策略,我们称之为Medprompt。Medprompt在没有专家设计的情况下激发了GPT-4的医学专家技能,轻松超越了所有标准医学问答数据集的现有基准。这种方法比简单提示策略的GPT-4和如Med-PaLM 2等最新专家模型都有很大的优势。在MedQA数据集(USMLE考试)上,Medprompt实现了9个绝对点的准确度提高,首次在该基准上超过90%。
作为我们调查的一部分,我们进行了一项全面的消融研究,揭示了Medprompt贡献组件的相对重要性。我们发现,包括上下文学习和思维链在内的方法组合可以产生协同效应。或许最有趣的是,我们发现,引导像GPT-4这样的通用模型在我们研究的医学专家工作负载上取得优异成绩的最佳策略是使用通用提示。我们发现,GPT-4从被允许设计其自己的提示中受益颇多,特别是在为上下文学习提出自己的思维链。这一观察与其他报告相呼应,即GPT-4通过内省具有自我改进能力,如自我验证[9]。
我们注意到,自动的思维链推理消除了对特殊人类专家知识和医学数据集的依赖。因此,尽管名为Medprompt,但从我们对GPT-4在医学挑战问题能力的调查的框架背景和研究轨迹来看,该方法不包括任何特定面向医学的组件。正如我们在第5.3节中探讨的,这种方法可以轻松应用于其他领域。我们提供了关于Medprompt的细节,以促进未来对引导通用基础模型提供专家建议的研究。