
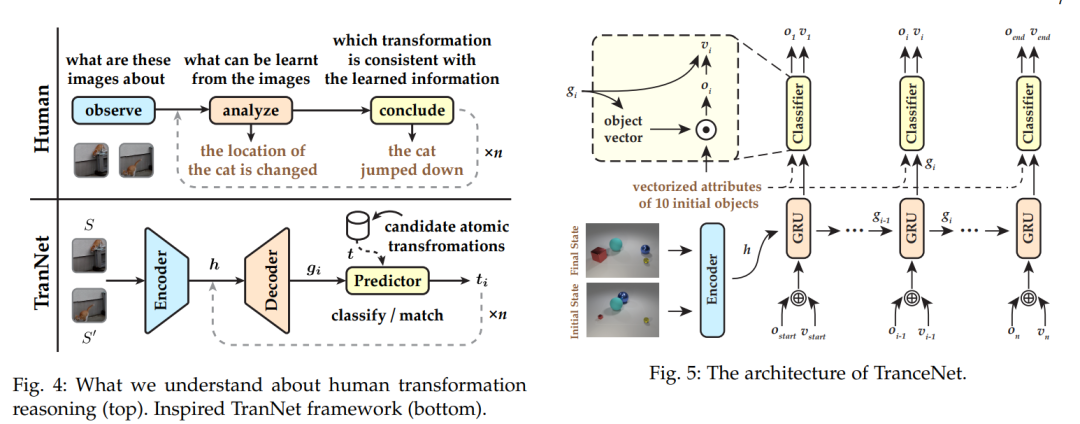
现有的视觉推理任务,如VQA中的CLEVR,忽略了一个重要因素,即变换。这些任务仅旨在测试机器在静态环境中,如一个图像内,理解概念和关系的能力。这种基于状态的视觉推理无法反映出推断不同状态之间的动态变化的能力,而这在皮亚杰的理论中已被证明对于人类的认知同样重要。为了解决这个问题,我们提出了一个新颖的变换驱动视觉推理(TVR)任务。给定初始状态和最终状态,目标就是推断出相应的中间变换。基于这个定义,我们首先构建了一个基于CLEVR的新合成数据集,名为TRANCE,其中包括三个设置级别,即基础(单步变换)、事件(多步变换)和视图(带有不同视角的多步变换)。接下来,我们基于COIN构建了另一个真实数据集,名为TRANCO,以弥补TRANCE在变换多样性上的损失。受到人类推理的启发,我们提出了一个名为TranNet的三阶段推理框架,包括观察、分析和结论,以测试最近的高级技术在TVR上的表现。实验结果表明,最先进的视觉推理模型在基础上表现良好,但在事件、视图和TRANCO上仍然远远达不到人类水平的智能。我们相信,这一新提出的范式将促进机器视觉推理的发展。需要在这个方向上研究更先进的方法和新问题。TVR的资源可在https://hongxin2019.github.io/TVR/ 上获得。
成为VIP会员查看完整内容
相关内容
Arxiv
223+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
223+阅读 · 2023年4月7日