

多模态模型被认为是未来人工智能进步的关键组成部分。由于基础模型在自然语言处理 (NLP) 和视觉领域的成功,这一领域正迅速发展,并涌现出大量新的设计元素。人们普遍希望将基础模型进一步扩展到多种模态(如文本、图像、视频、传感器、时间序列、图等),最终形成通用的多模态模型,即在不同数据模态和任务之间通用的单一模型。然而,关于最近的多模态模型(尤其是那些超越文本和视觉的模型)的系统性分析研究较少,特别是对于所提出的底层架构。因此,本研究通过一种新颖的架构和训练配置特定的分类法,提供了关于通用多模态模型(GMMs)的新视角。这包括统一性、模块化和适应性等对GMMs广泛采用和应用至关重要的因素。本文综述进一步强调了该领域的关键挑战和前景,并指导研究人员了解新的进展。
引言
多模态模型是能够跨越多种数据模态进行学习的深度学习模型。有人推测,这类模型可能是实现人工通用智能(AGI)所必需的一步,因此,机器学习社区对它们的兴趣正在迅速增加。多模态学习的最终目标是开发一个可以执行(或轻松适应执行)各种多模态任务的单一模型。一个简单的多模态例子是一个视觉语言模型,它可以执行单模态任务(如文本生成、图像分类)和跨模态任务(如文本到图像检索或图像字幕生成),后者需要跨模态的上下文和联合学习【58】。
在机器学习的发展历程中,多模态研究一直在积极推进【3, 28, 31, 33, 34, 44, 75, 83】。然而,这些研究偏重于跨模态学习和有限范围的模态(文本和图像)。因此,模型架构的设计元素不足以促进向更通用模型的现代研究的平稳过渡。例如,与传统机器学习(ML)模型不同,基础模型通过重建大量(通常是未标注的)数据进行训练,以便在各种下游数据集和任务中表现良好。训练基础模型的目标是学习如何提取可在不同领域和应用中重用的通用特征表示。类似地,多模态领域基础模型的目标是实现跨多种模态和任务的学习,但这些模型受限于对文本和图像模态的研究重点。
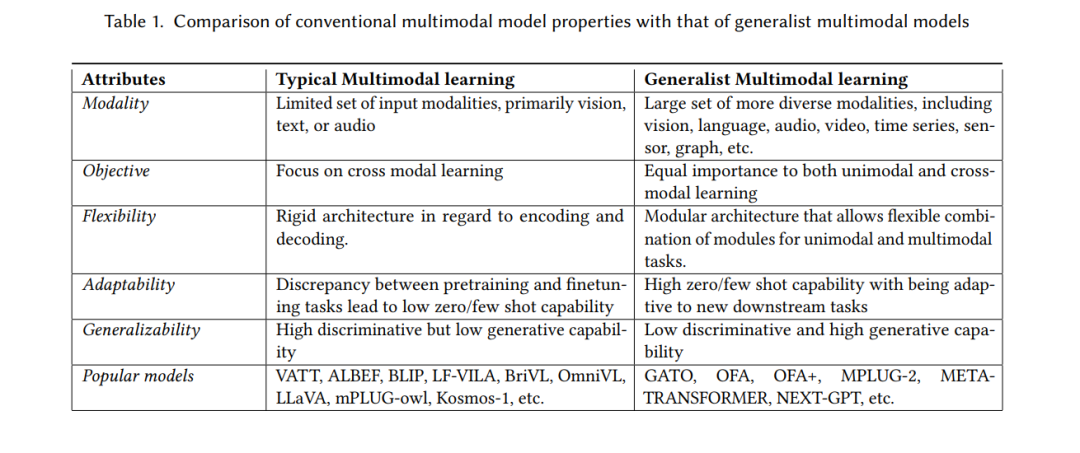
受这些差距的激励,多模态文献中引入了一系列新的设计元素【5, 58, 70, 84, 93, 106】。这些大多受NLP和视觉领域的单模态基础模型成功的启发。我们将这类新模型称为通用多模态模型(GMMs)。GMMs可以包括那些能够跨越研究中最常见的两种数据类型(文本和图像)之外的模态运行的模型。更具体地说,模型必须展示跨越多种模态(包括但不限于文本、图像、语音、音频、视频和传感器)的能力。这一更广泛的定义捕捉了在不同模态中具有广泛泛化表示的模型。表1总结了我们对通用多模态模型和典型多模态模型的定义之间的详细区分。
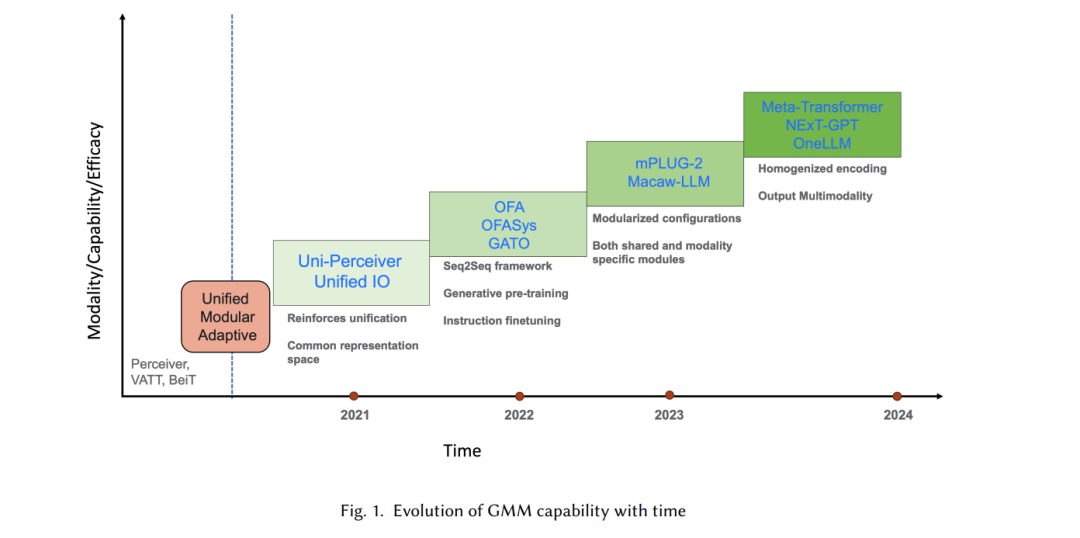
与标准深度学习模型相比,基础模型具有多种独特的属性,包括大规模预训练(监督或/和自监督,例如掩码语言建模【12】)和特殊的微调策略(例如,提示调优、参数高效微调)。这些基础模型的特性使它们在文本和视觉模态中成为领跑者【96】。这些特性也被引入GMMs,并在多模态学习中显示出类似的改进。另一方面,多模态学习在架构、训练策略和评估方面有许多方面,使得GMMs的发展成为一个独特的研究领域。如图1所示,GMMs的能力随着新策略的引入而不断增长。因此,审视当前GMMs的努力并确定进一步增强GMMs能力的必要属性具有重要价值。在本综述中,我们确定了这些新兴属性并进行了全面分析。
尽管已有一些关于多模态学习的综述论文【1, 20, 43, 51】,但它们存在以下局限:(i)主要处理文本-视觉范式,对其他模态考虑甚少;(ii)仅关注跨模态的数据融合,忽略了其他关键因素,如架构设计、预训练目标以及不断扩展的多模态任务范围【17, 62】;(iii)对跨模态学习的关注较多,对单模态方面考虑较少【51】。因此,我们对现有的GMMs(涵盖文本和视觉以外模态的模型)进行了全面的综述,结合了各种数据处理、架构和训练方面的内容。据作者所知,这是第一篇全面回顾GMMs学习最新趋势的综述。本文的主要贡献如下:
- 提出了一种新的分类法,解决了当前多模态架构设计空间的问题。
- 分类法因素明确与基础模型的背景相一致,与之前的综述论文不同。
- 提出了一种基于分类法的问题化当前方法的方法。
- 提供了一系列可以推进多模态范式的研究方向。 本文其余部分的组织结构如下:第二部分提供了关于各单模态领域基础模型的背景;第三部分讨论了GMMs的典型架构管道;第四部分描述了我们的分类法,将现有工作分类到分类法中,并利用分类法评论当前方法的优缺点;第五部分强调了多模态基础范式中的关键挑战;第六部分列出了实现真正通用模型的发展潜在研究机会;最后,第七部分总结了我们的研究发现。
典型的GMM架构管道
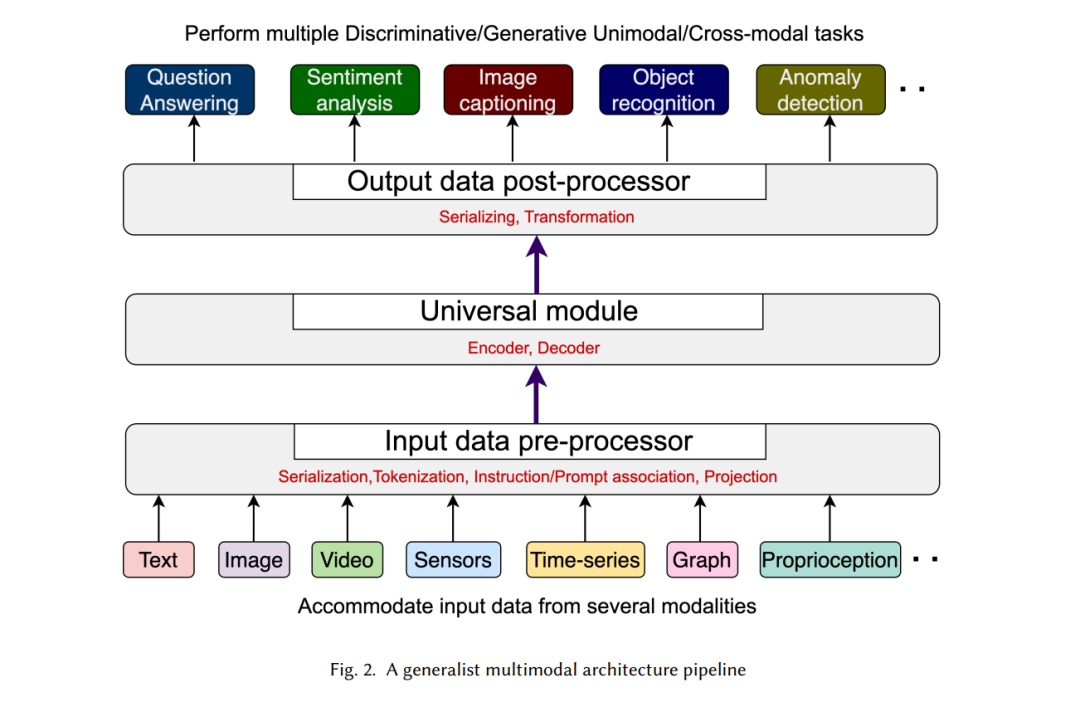
从输入数据到输出预测的典型GMM架构管道可以分为不同的阶段,如下所述,并在图2中进行了说明。以下小节将更详细地描述这些不同的阶段。
**输入预处理
第一个模块与数据预处理相关,其中来自不同模态的原始数据被转换为可被通用学习模型消耗的形式。这包括不同的阶段,如下所述:
**序列化/标记化
这一过程将文本、音频、图像等不同模态转换为通用的数值格式(也称为标记)。例如,在文本模态中,输入文本被解析为标记,每个标记被映射到模型词汇表中的一个数值ID。在视觉模态中,图像被调整为固定大小的补丁(例如,在CLIP中为224 x 224像素【65】),并将对应的像素值存储在数值张量中。在音频模态中,原始音频被转换为频谱图表示,然后进一步切分为小的时间/频率帧。在点云中,"最远点采样"(原始点云的代表性骨架采样)、最近邻和邻接矩阵可以定位/简化输入数据【103】。这一步的主要目的是为编码器准备数据。
**编码
编码器在高维空间中获取输入标记的数值表示,称为嵌入。编码器利用预定义的知识(通过训练的冻结模型)准确地将输入标记定位在支持学习的高维语义空间中。对于文本模态,任何在大规模文本语料库上训练的语言模型(LLM)都可以作为有效的嵌入模型。CLIP和CLIP-VIT【65】系列模型是编码视觉信息(包括图像和视频帧)的强有力候选者。大型音频模型如WHISPER【66】用于编码音频模态。上述所有编码器都是特定模态的,通常分别训练,导致不同编码器生成的表示(嵌入)之间可能存在差异。IMAGEBIND【19】是一种潜在的解决方案,它学习跨越六种模态(包括图像、文本、音频、深度、热成像和惯性测量单元数据)的联合嵌入。诸如NEXT-GPT等GMMs利用IMAGEBIND来编码其输入模态。此外,最近的GMMs,如META-TRANSFORMER【103】和ONELLM【22】,已经表明,任何经过良好预训练的Transformer都可以作为通用的跨模态编码器。
**投影
投影将编码器的表示(嵌入)转换为通用模型可理解的新空间。通常,LLM被用作通用模型;因此,投影器将原始嵌入转换为语言空间。虽然序列化、标记化和编码是标准化的,但投影步骤在不同模型之间有所不同,通常是可训练的组件。投影可以从简单的全连接线性层到复杂的卷积操作不等。它还通过交叉注意力和其他精妙机制对齐不同模态特定的表示。
**** 通用学习**
来自输入预处理模块的不同模态的统一表示被送入第二个模块,即通用/主干模型,该模型通过多个神经网络层在共享语义空间中执行表示学习和推理。在多模态学习中,通常使用预训练/微调的LLM作为通用模型(例如,OFA中的BART【84】,ONELLM中的LLAMA-2【22】)。这主要有两个原因:(i)与其他模态不同,语言模型在各种通用任务上已经在大量数据上进行了广泛训练,从而形成了一个强大的知识模型;(ii)输入和输出交互大多以文本形式进行,因此使用LLM作为核心模型并将其他模态围绕其对齐是合理的,而不是反过来。
**** 输出解码**
在最后一个模块中,数据后处理阶段将学习到的多模态表示转换为特定模态/任务的输出。解码器利用多模态编码器表示的丰富融合,生成具有跨模态理解背景的任务特定输出。对于仅文本输出,可以利用标准的Transformer解码器(具有注意力、交叉注意力和多层感知器(MLP)层),共享模型可以接受不同类型的输入并适应各种任务的文本生成。对于图像生成,使用扩散解码器模型如Stable Diffusion(SD)【72】;对于音频合成,使用AudioLDM【53】。