

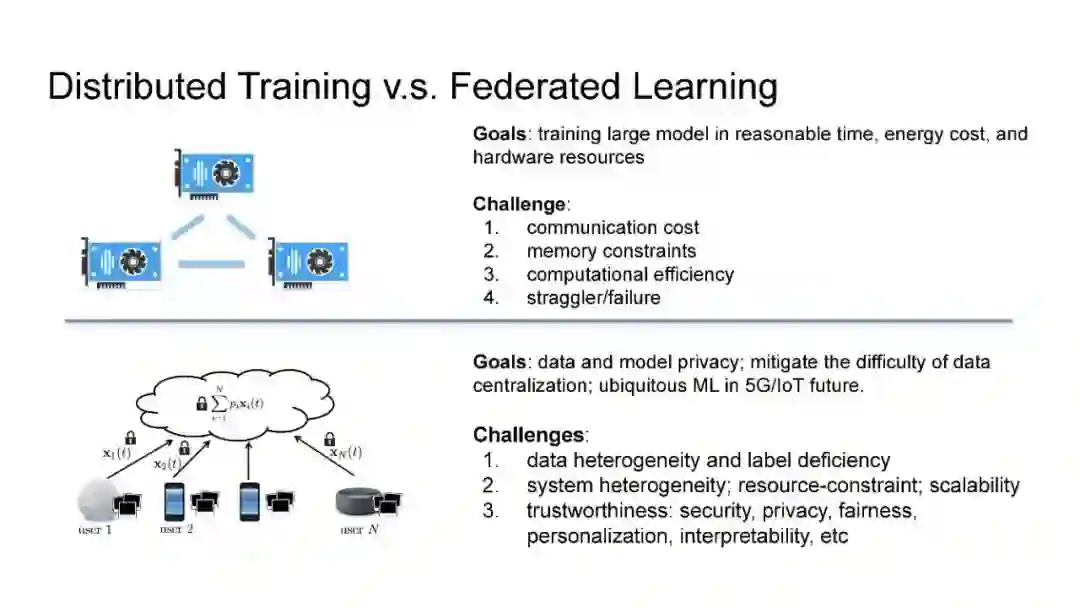
在现代AI中,大规模的深度学习模型已经成为许多重要互联网业务背后的核心技术,如搜索/ADs/推荐系统/CV/NLP。BERT、Vision Transformer、GPT-3和Switch Transformer模型将模型规模扩大到10亿甚至万亿个参数,表明几乎所有学习任务的精度都有了显著提高。使用云集群进行分布式训练是及时成功训练此类大规模模型的关键。开发更先进的分布式训练系统和算法既可以降低能量成本,也可以使我们训练更大的模型。此外,开发联邦学习这样的颠覆式学习范式也至关重要,它不仅可以保护用户的隐私,还可以分担处理前所未有的大数据和模型的负担。本次演讲将主要讨论用于大规模模型的分布式ML系统:用于云集群的动态分布式训练(https://DistML.ai)和用于边缘设备的规模联合学习(https://FedML.ai)。
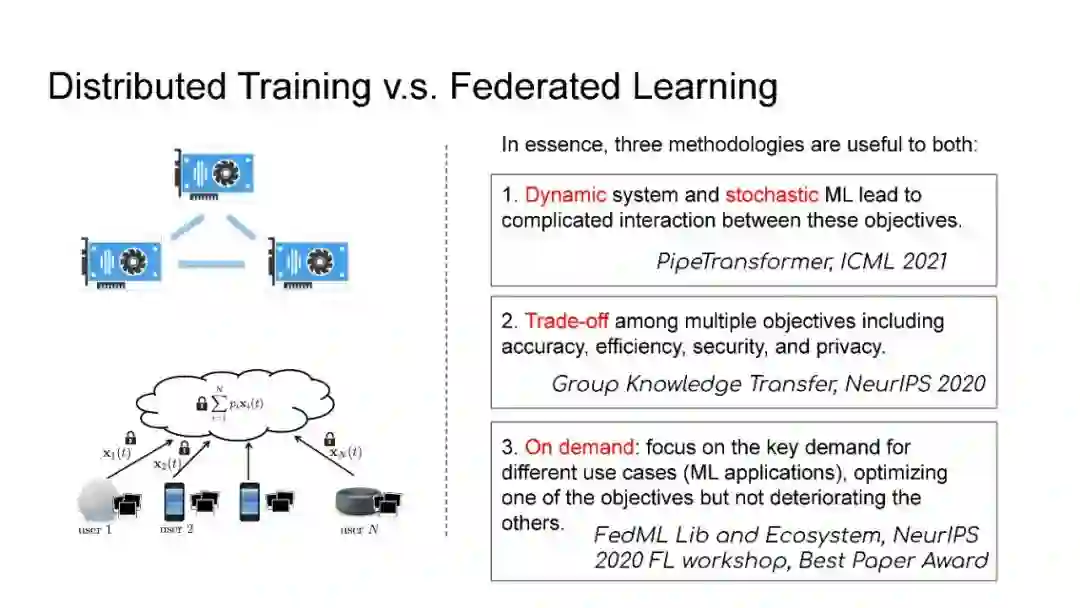
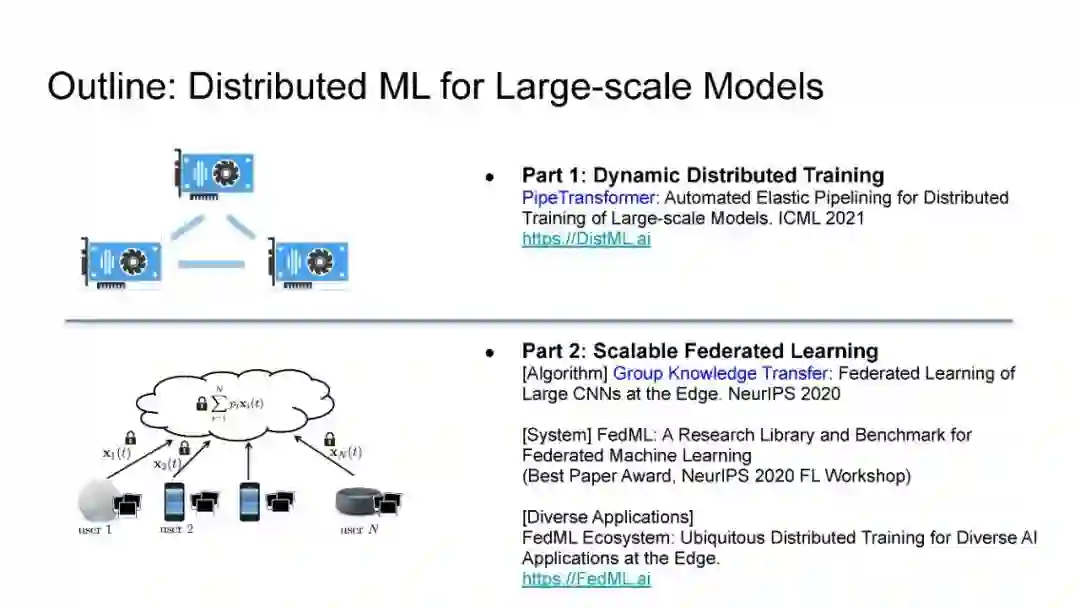
在第一部分中,我将介绍PipeTransformer,这是一种用于Transformer模型分布式训练(BERT和ViT)的自动化弹性pipeline。在PipeTransformer中,我们设计了一种自适应的飞冻结算法,可以在训练过程中逐步识别并冻结某些层,以及一种弹性流水线系统,可以动态减少GPU资源来训练剩余的活动层,并在已释放的GPU资源上分叉更多的流水线,以扩大数据并行度的宽度。在第二部分中,我将讨论可扩展的联邦学习,用于在资源受限的边缘设备和FedML生态系统上训练大规模模型,旨在为各种AI应用(如CV NLP、GraphNN和IoT)在边缘进行无处不在的分布式训练。
Chaoyang He是 FedML 联合创始人兼 CTO,博士毕业于南加州大学,他曾在华为、百度、腾讯任职,拥有丰富的互联网产品和业务研发经验。


成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2022年9月30日
相关主题

相关VIP内容
相关资讯