简介 传统视频基准(如YouCook2、ActivityNet)多依赖单轮问答或离散片段,难以评估模型对动态视频流的时序推理能力。中科院-快手团队提出首个针对流式长视频多轮问答的评测基准SVBench,主要包括: * 一个覆盖全面的基准:具有时序****多轮问答链,专门设计用于全面评估当前LVLMs的流式视频理解能力。 * 一个半自动化的标注pipeline:生成表示视频片段上一系列连续多轮对话的QA链,并构建连续QA链之间的时序关系。 * **一个流式视频理解模型StreamingChat:**在SVBench上显著优于开源LVLMs,在各种视觉语言基准上表现相当。
研究动机 * **长上下文流视频理解局限:**当前主流视觉-语言模型在处理长上下文流视频时,无法有效捕捉和理解复杂时序信息和动态变化,无法做到“边看边理解”。 * **传统视频基准不足:**现有基准(如YouCook2、ActivityNet)依赖单轮问答或离散片段,缺乏问答间的联系,无法有效评估模型的时序推理能力。 * **真实场景需求:**用户在持续视频流中发起多轮交互式提问,问题间存在复杂的时空关联,要求模型精准捕捉历史片段与对话的上下文关联。
Tip
针对以上不足,中科院-快手团队推出SVBench,首个针对流式长视频多轮问答的评测基准,攻克现有模型在时间推理与连续对话中的短板!论文已被ICLR 2025 Spotlight收录,为视频理解领域注入新动力!
项目主页:
https://yzy-bupt.github.io/SVBench/ * **论文链接:**https://arxiv.org/abs/2502.10810 * 代码链接:
https://github.com/yzy-bupt/SVBench * 模型链接:
https://huggingface.co/yzy666/StreamingChat_8B * 数据集链接:
https://huggingface.co/datasets/yzy666/SVBench * Leaderboard链接:
https://huggingface.co/spaces/yzy666/SVBench * Leaderboard提交链接:
https://forms.gle/tmY8PmM5KWSvTGcn7
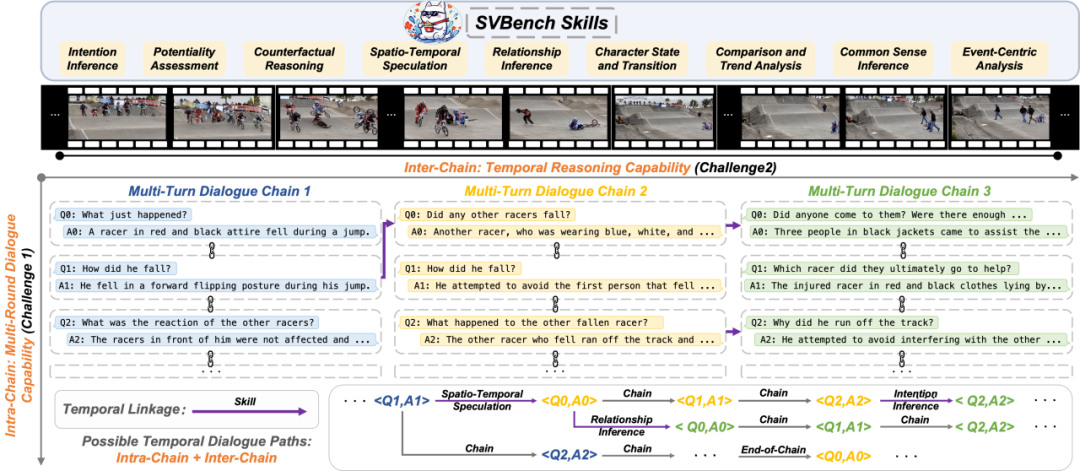
主要贡献 1. 任务创新:时序多轮对话
提出流视频时序多轮对话任务,要求模型在视频流连续播放过程中进行多轮交互,并建立前后QA链的时序关联(如人物、事件、对象的延续性)。模型需综合历史视频片段与对话上下文生成回答(例如,判断“是否有其他赛车手摔倒”需回顾先前片段中的车手状态),以此评估实时流视频下的长程推理与对话能力。 2. 数据集构建:规模与复杂性领先
数据规模:包含来自6个开源数据集的1,353个多样化流视频,标注49,979对QA,平均每视频36.94对,远超现有数据集(如ActivityNet-QA、NExT-QA)。 时序结构:设计时序对话路径,QA链与视频时间轴同步推进,强调跨片段的连贯推理,模拟真实场景中的动态交互。 3. 实验发现与模型提升
现有模型短板:主流LVLM在流视频理解任务中表现欠佳,凸显现有技术局限性。 新模型StreamingChat:通过优化历史上下文,利用多轮对话能力,在SVBench上相比最优开源模型,对话得分提升9.41%,流式推理得分提升3.30%,且在传统图像/视频基准上保持竞争力。
✦ ✦ 数据构建Pipeline
✦
1
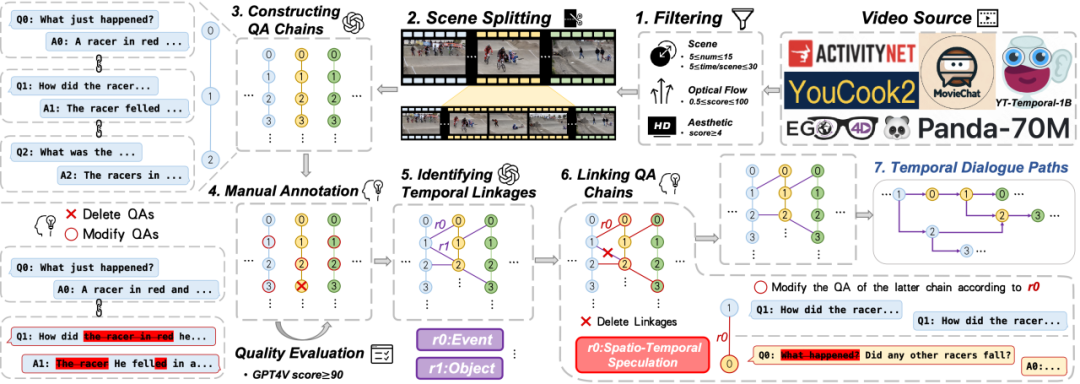
数据集构建与预处理
研究团队从YTTemporal-1B、YouCook2等12,989个公开视频数据源中筛选高质量视频,依据场景复杂度、光学流畅度等标准,最终保留1,353个视频。通过PySceneDetect工具进行场景分割,将视频切分为5-15个场景的片段,并调整片段边界以保持连续性(如相邻片段重叠1秒)。最终形成训练集(1,153视频,42,605 QA对)和评估集(200视频,7,374 QA对),确保数据无重叠。 2
多轮对话标注流程
为评估模型对视频时序对话的理解能力,团队设计半自动化标注流程:首先利用GPT-4等大型视觉语言模型(LVLM)为每个视频片段生成5-6轮初始QA对,形成“QA链”。随后,人工标注者对生成的QA进行修正,确保问题连贯、指代明确(如统一使用第三人称),并与视频内容严格对齐。整个过程耗时3个月,涉及30余名专业标注者。 3
QA质量评估机制
通过GPT-4对标注结果进行7维度量化评估(准确性、逻辑一致性、时间关联性等),并设置总分≥90的严格阈值。未达标者需重新修订,保证数据的高可靠性。这一机制确保QA链具备深度推理价值,例如要求后续问题需基于前序回答的上下文递进,避免重复或简单提问。 4
跨片段时序逻辑关联
为支持跨片段的时间推理,团队通过LLM分析相邻QA链的潜在关联(如相同实体、事件发展),构建关系五元组(包含问题、答案及关系类型)。人工进一步调整后续QA对,形成逻辑闭环:既保持单链内问答的连贯性,又建立跨链的逻辑联系。例如,将后续问题修改为基于前链信息的深化提问,推动多轮对话的纵向推理。 ✦ ✦ SVBench数据集
✦
▍数据集特征
▸ 规模与结构:包含1,353个长视频(平均时长>2分钟),来源覆盖6个不同渠道; ▸ 标注优势:每个视频平均含36.94个半自动标注的QA对(当前最高水平),支持多轮对话分析; ▸ 对话复杂性:每个视频平均含8.61个多轮对话,单个对话平均含4.29个QA对,体现深度交互特性。
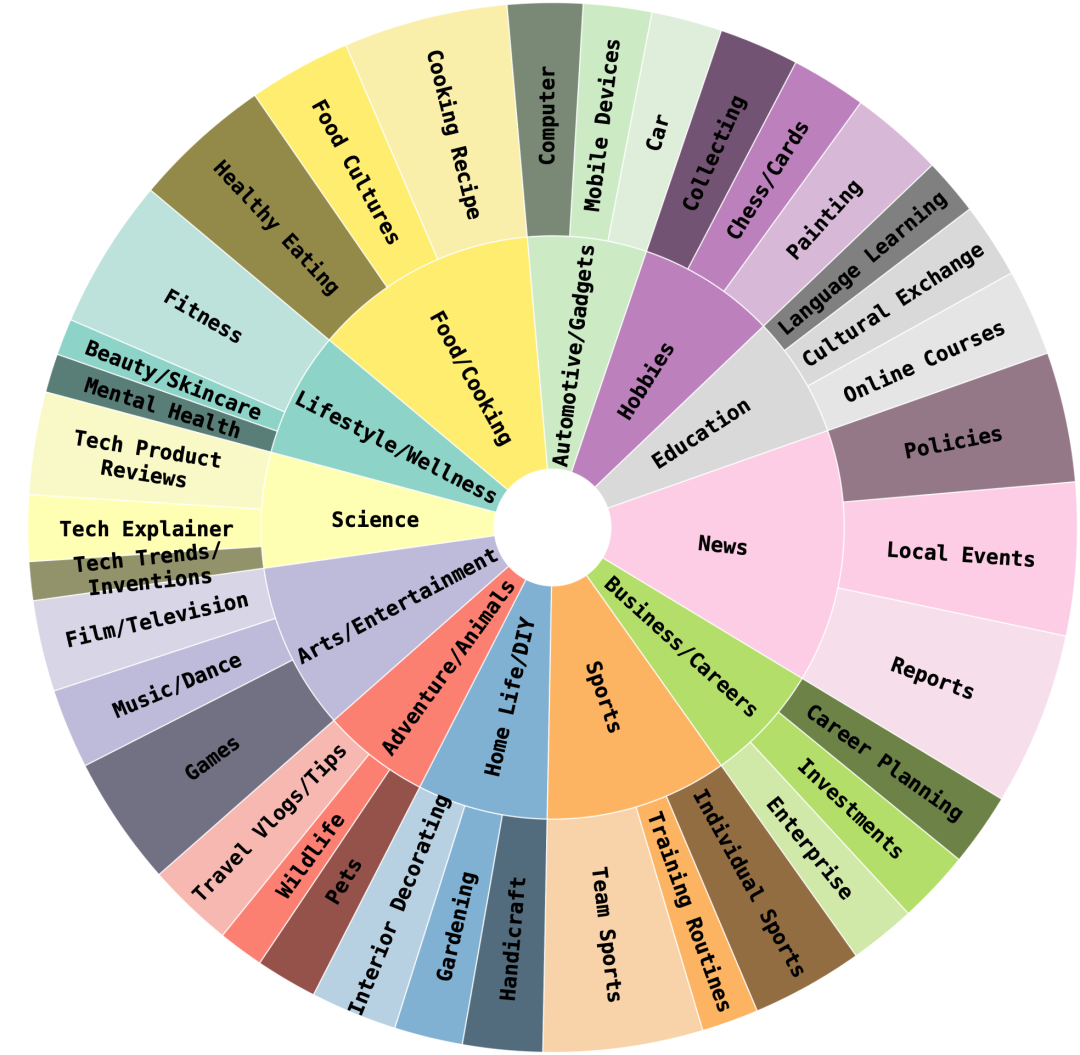
▍内容多样性
▸ 视频分类:12个主类别与36个子类别(如教育、娱乐等),覆盖广泛场景; ▸ 问题分类:设计9类专项评估问题,系统测评多模态大模型(LVLM)的核心能力: ▸ 涵盖意图推断(II)、可行性评估(PA)、反事实推理(CR)、时空关系(STS)、实体关系(RI)、角色状态追踪(CST)、比较与趋势分析(CTA)、常识推理(CSI)、事件深度分析(ECA)。
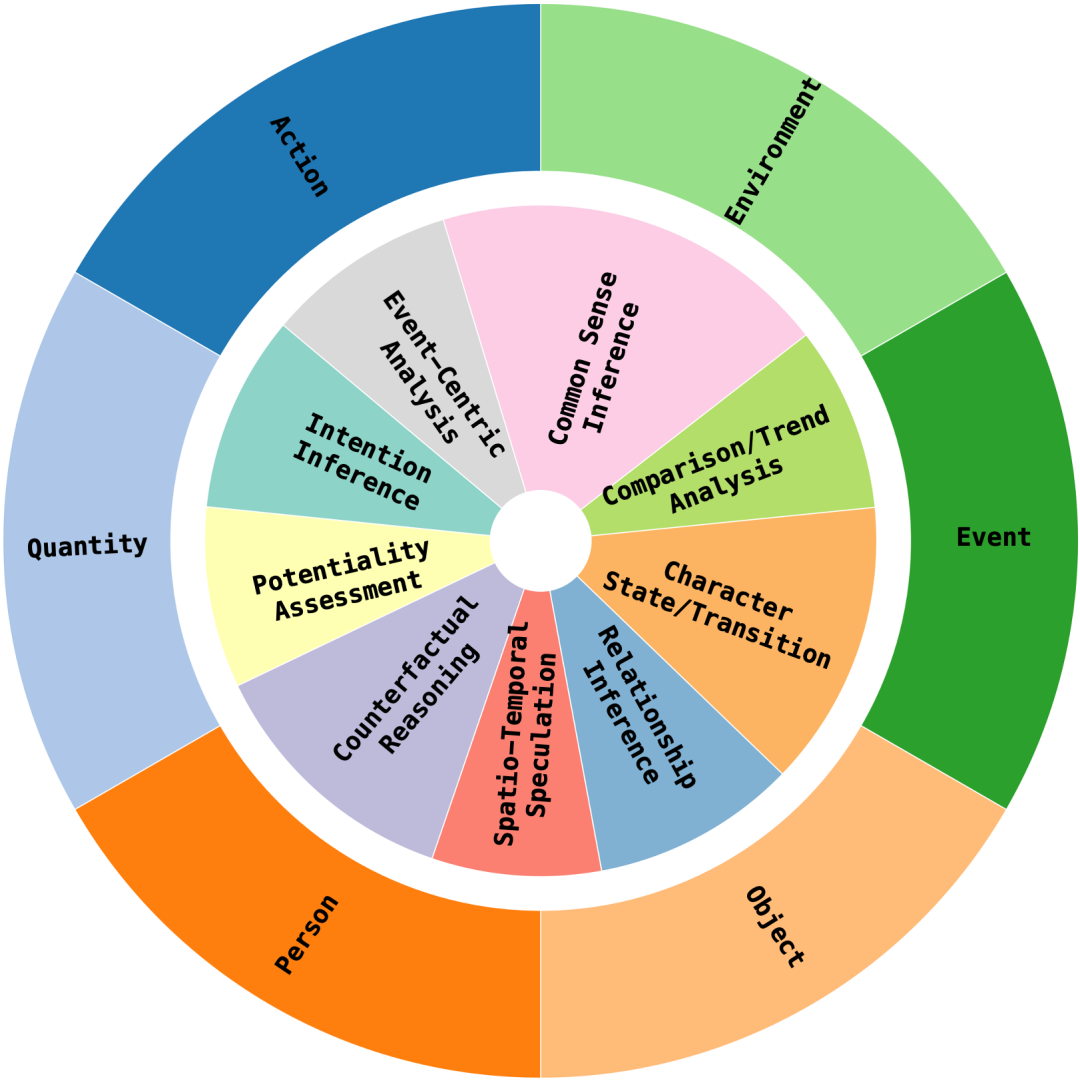
SVBench Demo
✦ ✦ StreamingChat模型
✦
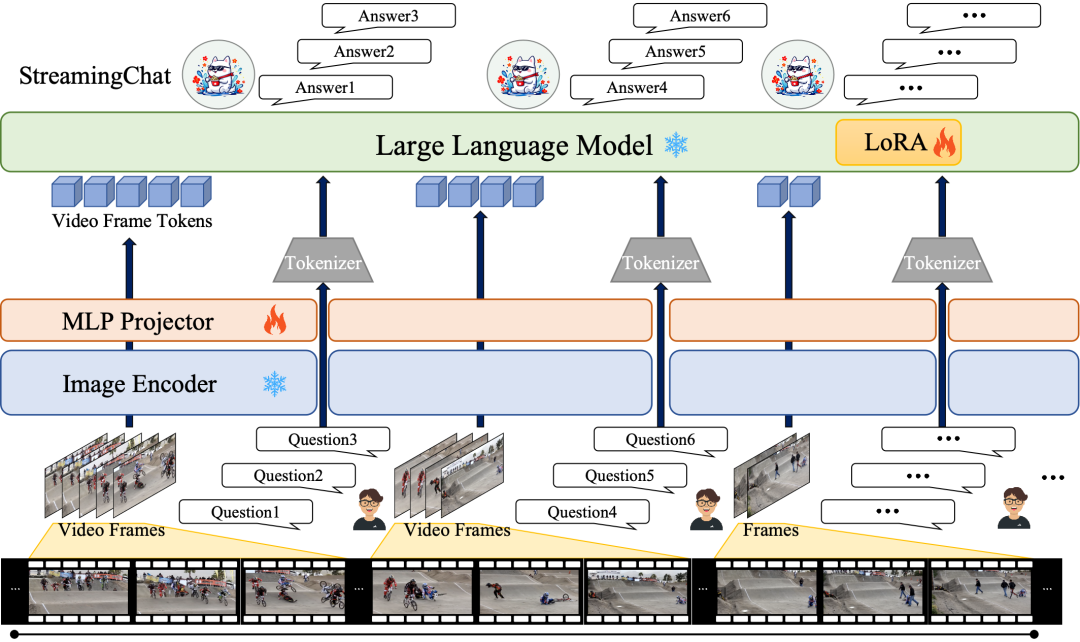
▍模型架构设计
模型基于InternVL2框架构建,采用三阶段结构: ▸ 视觉编码器:选用InternViT模型,该模型通过图像描述生成和OCR专用数据集进行预训练,能够以每秒1帧的速度提取视频帧特征。通过静态分辨率微调策略提升效率,使其可处理长达数分钟的视频流,并适配32k长度的上下文窗口。 ▸ 特征转换模块:采用类似LLaVA-1.5的MLP投影器,将视觉编码器输出的帧特征转化为与语言模型兼容的token序列。 ▸ 语言模型核心:基于InternLM2大语言模型,创新性地在所有线性层嵌入LoRA适配器进行高效微调。视觉token与语言token通过交错拼接方式输入模型,实现跨模态信息融合。
▍训练数据组织策略
训练采用自建数据集的时序对话路径,技术实现上有两个关键设计: **▸ 多模态对话格式:**将视频流切分为连续片段,每个片段后接多轮问答对,形成结构化序列:<视频片段1><问答组1>...<视频片段N><问答组N>。这种设计模拟真实场景中边播放边对话的交互模式。 **▸ 动态分段机制:**为突破上下文窗口限制,对超过100帧的长视频进行智能分割。通过滑动窗口策略将长视频拆分为可管理的数据块,确保模型在训练过程中能有效学习长时依赖关系。
StreamingChat demo
✦ ✦ 实验
✦
▍实验设计
▸ 研究团队为评估LVLMs(大规模视觉语言模型)在流媒体视频理解中的表现,设计了两种实验模式:对话评估与流媒体评估。 ▸ 对话评估要求模型在多轮问答中逐步处理视频片段,每段视频对应一个问答链。模型需基于历史对话上下文回答当前问题,旨在模拟用户观看视频时连续提问的场景,检验模型对长对话的连贯性与上下文追踪能力。 ▸ 流媒体评估在对话基础上引入时间跳转机制,当问题涉及后续视频片段时,有80%概率直接跳转至关联问题。这一设定考验模型处理时间关联性任务的能力,例如跨片段的事件推理与动态场景整合。
▍评估指标
研究采用基础指标与多维度对话框架结合的方式衡量性能: **▸ 基础指标:**包括衡量文本相似度的METEOR和基于GPT-4的语义相似度评分(GPT4-Score)。 ▸ 对话框架指标:
▸ 语义准确性(SA):答案与事实及语境的匹配程度。 ▸ 上下文连贯性(CC):跨对话的逻辑连贯与话题延续性。 ▸ 逻辑一致性(LC):避免答案自相矛盾。 ▸ 时间理解(TU):对视频时序事件的推理能力。 ▸ 信息完整性(IC):答案的全面性与细节覆盖。 ▸ 综合得分(OS):上述指标的加权总分。
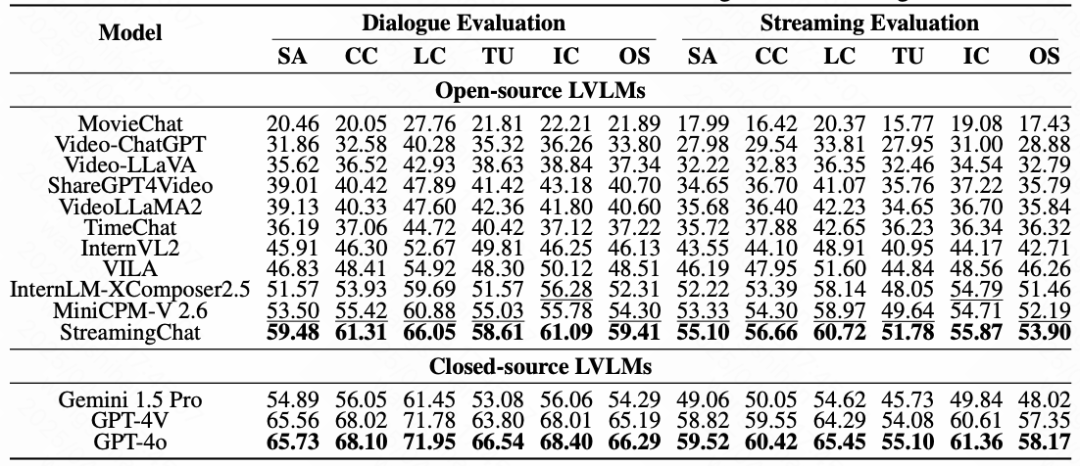
为展示多个模型在流媒体视频理解任务中的表现,研究团队提供了多个模型在SVBench数据集上的排行榜,旨在对各模型在处理长上下文流媒体视频方面能力的全面比较。
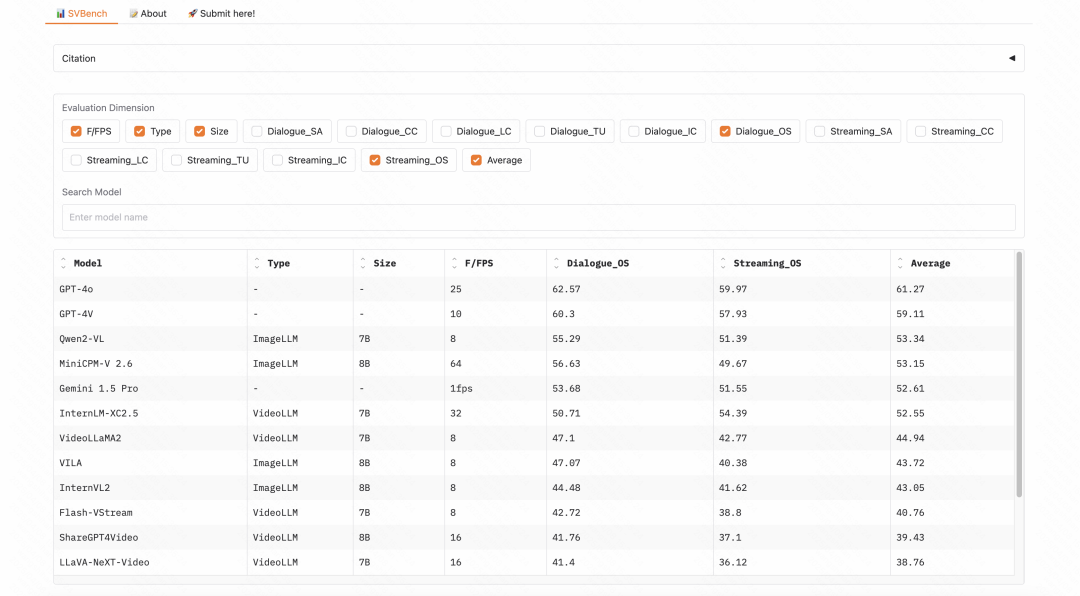
SVBench的Leaderboard展示,见https://huggingface.co/spaces/yzy666/SVBench
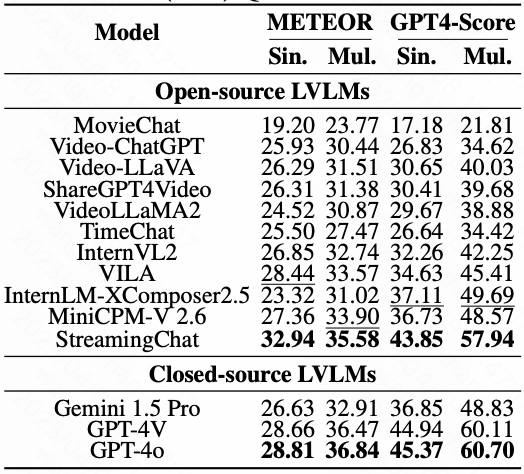
▍整体性能对比
▸ 实验结果显示闭源模型(如GPT-4o、GPT-4V)在两项评估中均大幅领先,其OS得分分别达66.29(对话)与58.17(流媒体)。开源模型中,StreamingChat与MiniCPM-V 2.6表现最佳,OS分别提升28.79%与26.20%超过原版模型,表明训练数据对流媒体任务的有效性。值得注意的是,流媒体评估得分普遍低于对话评估,主因是其需处理动态时序信息与跨片段推理的复杂性。
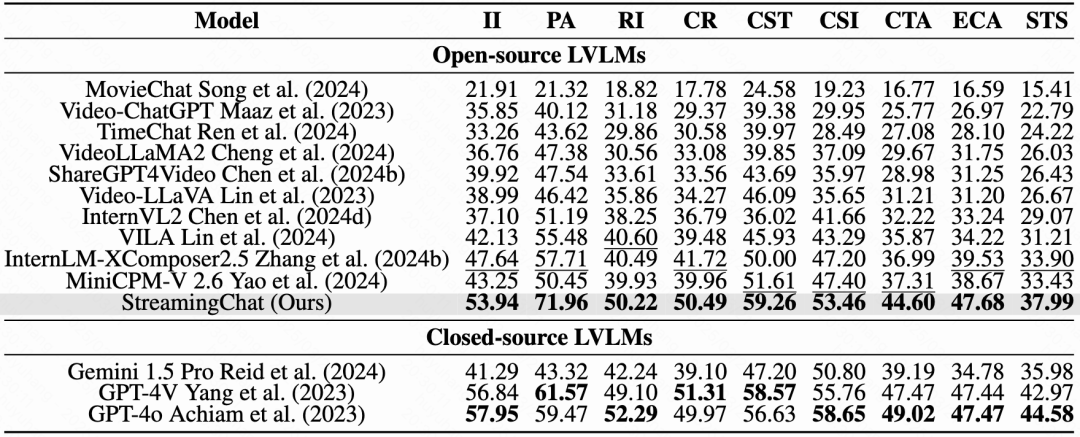
▍技能专项分析
模型在9类视频理解技能上的表现差异显著: ▸ 优势技能:意图推断(II)与潜力评估(PA)得分较高,显示模型对角色动机和未来动作预测较擅长。 ▸ 薄弱环节:反事实推理(CR)与时空推测(STS)挑战最大,因涉及抽象逻辑和复杂场景构建。开源模型StreamingChat在PA、CST(上下文敏感跟踪)与ECA(事件因果分析)上甚至超越部分闭源模型,但其多数技能得分仍低于60,凸显任务难度。
▍消融实验验证
▸ 通过对比单轮问答(传统评估)与多轮对话评估,研究发现:引入历史对话上下文后,所有模型的METEOR与GPT4-Score均显著提升。这验证了多轮交互设计能更有效挖掘模型潜力,但也暴露出部分场景下性能瓶颈,为未来优化指明方向。