基于未来现代化海上作战背景, 提出了利用多智能体深度强化学习方案来完成无人艇群博弈对抗中的协同围捕任务。首先, 根据不同的作战模式和应用场景, 提出基于分布式执行的多智能体深度确定性策略梯度算法, 并对其原理进行了介绍; 其次, 模拟具体作战场景平台, 设计多智能体网络模型、奖励函数机制以及训练策略。实验结果表明, 文中方法可以有效应对敌方无人艇的协同围捕决策问题, 在不同作战场景下具有较高的效率, 为未来复杂作战场景下无人艇智能决策研究提供理论参考价值。
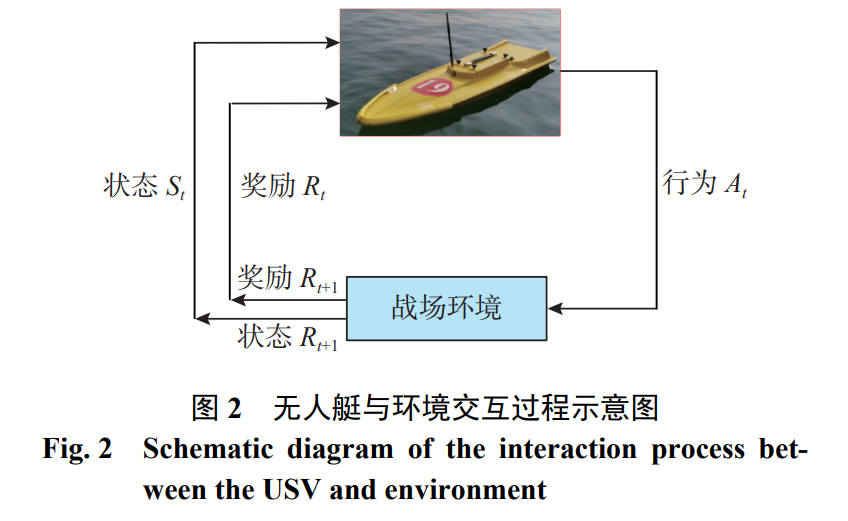
在现代军事研究领域, 随着高新技术的快速发 展, 催化了战场中作战思想、理论和模式等方面的 迅速变革, 战争形态逐渐趋于信息化和智能化[1-3]。 人工智能和无人系统技术为未来战争中的决策分 析、指挥控制和博弈对抗等应用提供了更多智能 决策和自主作战能力, 逐渐扮演着更加重要的角 色。其中, 无人艇作为一种全自动小型水面机器 人, 具有体型小、机动灵活以及活动范围广等优势, 在情报侦查、海上巡逻以及环境检测等领域发挥 着重要作用[4]。 强化学习作为人工智能技术的重要分支, 目前 在无人艇、无人机等多智能体博弈对抗问题中具有 重要的应用价值[5-7]。李波等[8] 将多智能体深度确 定性策略梯度(multi-agent deep deterministic policy gradient, MADDPG)算法应用于多无人机的协同任 务研究, 可以解决简单的任务决策问题。刘菁等[9] 提出了博弈理论与 Q-Learning 相结合的无人机集 群协同围捕方法, 结果表明该方法可以完成对单 目标的有效围捕。Zhan 等 [10] 提出了多智能体近 端策略优化(multi-agent proximal policy optimization, MAPPO)算法, 用于实现异构无人机的分布式决策 和协作任务完成。赵伟等[11] 对无人机智能决策的 发展现状和未来挑战进行了讨论和分析。相比之 下, 目前国内外对于无人艇的博弈对抗研究工作 相对较少, 仍处于发展阶段。苏震等[12] 开展了关 于无人艇集群动态博弈对抗的研究, 提出利用深 度确定性策略梯度(deep deterministic policy gradient, DDPG)算法来设计策略求解方法, 训练得到的 智能体可以较好地完成协同围捕任务。夏家伟等[13] 则使用 MAPPO 算法完成对单一无人艇的协同围 捕任务, 通过结合围捕任务背景, 建立了伸缩性和 排列不变性的状态空间, 最后利用课程式学习训 练技巧完成对围捕策略的训练, 结果表明所提方 法在围捕成功率上相较于其他算法具有一定优势。 无人艇集群博弈对抗的研究工作仍处于起步 阶段, 存在较大的提升空间: 目前的研究中, 无人 艇博弈对抗中的敌方通常采用传统算法躲避我方 的拦截围捕, 缺乏智能化决策能力; 其次, 海上目 标行为动作较为复杂, 双方博弈过程中的当前决 策需要充分考虑前后阶段产生的影响结果; 此外, 除需要围捕的动态目标外, 海上还存在岛礁等障 碍物, 在博弈对抗中还需要考虑躲避岛礁障碍物 等问题。 受到以上启发, 文中以无人艇集群对敌方入侵 岛礁目标进行围捕拦截为背景, 开展基于多智能 体深度强化学习的无人艇集群协同围捕研究。首 先基于现代式作战需求, 合理设计作战假想, 建模 相应的围捕环境; 其次, 采用 MADDPG 算法求解 策略方法, 根据不同的围捕任务设计网络结构、奖 励函数和训练方法; 最后通过仿真实验表明, 训练 得到的我方无人艇经过博弈后能够有效完成对敌 方的围捕拦截任务。